Enhancing Generative AI Image Refinement with Scribbles and Annotations: A Comparative Study of Multimodal Prompts
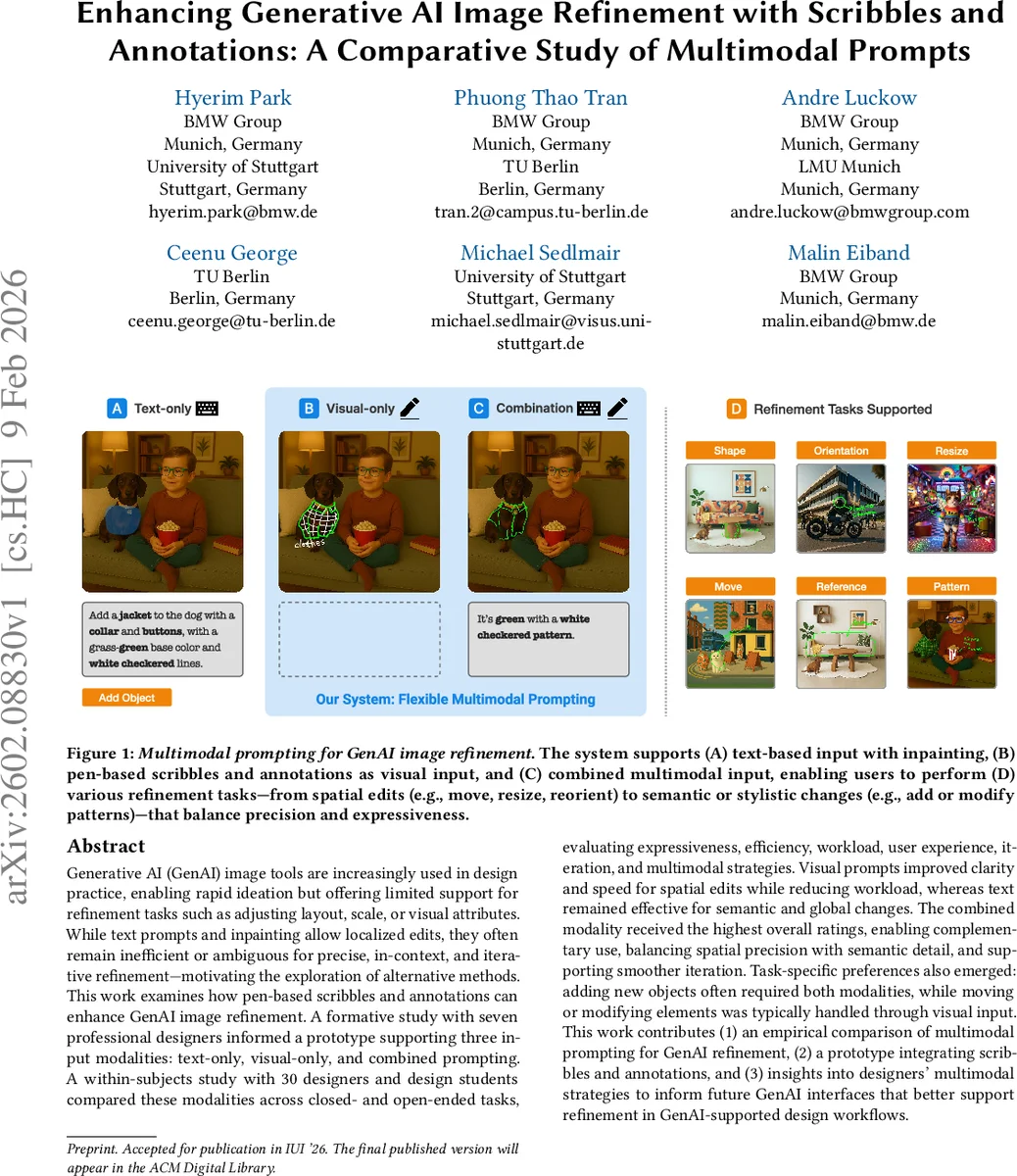
Generative AI (GenAI) image tools are increasingly used in design practice, enabling rapid ideation but offering limited support for refinement tasks such as adjusting layout, scale, or visual attributes. While text prompts and inpainting allow localized edits, they often remain inefficient or ambiguous for precise, in-context, and iterative refinement – motivating the exploration of alternative methods. This work examines how pen-based scribbles and annotations can enhance GenAI image refinement. A formative study with seven professional designers informed a prototype supporting three input modalities: text-only, visual-only, and combined prompting. A within-subjects study with 30 designers and design students compared these modalities across closed- and open-ended tasks, evaluating expressiveness, efficiency, workload, user experience, iteration, and multimodal strategies. Visual prompts improved clarity and speed for spatial edits while reducing workload, whereas text remained effective for semantic and global changes. The combined modality received the highest overall ratings, enabling complementary use, balancing spatial precision with semantic detail, and supporting smoother iteration. Task-specific preferences also emerged: adding new objects often required both modalities, while moving or modifying elements was typically handled through visual input. This work contributes (1) an empirical comparison of multimodal prompting for GenAI refinement, (2) a prototype integrating scribbles and annotations, and (3) insights into designers’ multimodal strategies to inform future GenAI interfaces that better support refinement in GenAI-supported design workflows.
💡 Research Summary
This paper investigates how multimodal prompting—specifically text‑only, visual‑only (pen‑based scribbles and annotations), and a combined modality—affects the refinement of images generated by generative AI (GenAI) tools. While existing GenAI systems excel at rapid ideation, they struggle with iterative refinement tasks such as adjusting layout, scale, orientation, or fine visual attributes, because text‑based inpainting can be ambiguous and inefficient for spatially precise edits. To address this gap, the authors define scribbles and annotations not merely as sketches but as actionable visual prompts that directly encode refinement intent (e.g., “move this object”, “resize this region”, “transfer this pattern”).
A formative study with seven professional designers explored how these three input types are used across six refinement tasks (adding objects, modifying elements, changing material/pattern, spatial adjustments, global modifications, and self‑directed edits). Findings indicated that designers naturally gravitate toward visual marks for spatial relationships and toward text for semantic or global changes. These insights guided the design of a prototype system implemented on an iPad with stylus support, offering (1) a text field with inpainting selection, (2) a free‑form pen tool for scribbles and annotations, and (3) the ability to combine both modalities in a single workflow.
The main evaluation involved a within‑subjects experiment with 30 participants (designers and design students). Each participant completed the same six tasks under three conditions: text‑only, visual‑only, and combined prompting. Objective metrics (task completion time, NASA‑TLX workload) and subjective measures (System Usability Scale, open‑ended questionnaires) were collected.
Key results:
- Expressiveness – Visual prompts yielded the highest clarity for spatial edits (moving, resizing, re‑orienting), while text remained superior for conveying object type, material, style, or other high‑level concepts.
- Efficiency – Average completion times were 45 s (text), 35 s (visual), and 28 s (combined), showing a 22 % speed gain for visual‑only over text and an additional ~20 % gain when both modalities were used together.
- Workload – NASA‑TLX scores dropped from 5.6 (text) to 4.2 (visual) to 3.4 (combined), indicating that visual input reduces cognitive load and that the multimodal condition minimizes it further.
- User Experience – SUS scores rose from 68 (text) to 78 (visual) to 84 (combined). Participants reported that a “visual‑first, text‑supplement” workflow felt natural and gave them confidence during iteration.
- Strategic Use – Most participants adopted a “visual‑first” approach, using scribbles/annotations to lock down spatial intent and then adding textual details for semantics. Adding new objects often required both modalities, whereas moving or resizing existing elements could be handled with visual input alone.
The study demonstrates that multimodal prompting bridges the gap between designers’ visual thinking and the language‑centric interfaces of current GenAI tools. Visual prompts provide direct, unambiguous communication for spatial refinement, while text leverages the model’s semantic knowledge for global or abstract changes. The combined modality leverages the strengths of both, delivering the highest overall satisfaction, lowest workload, and fastest task completion.
Contributions include: (1) an empirical comparison of text‑only, visual‑only, and combined prompting for GenAI image refinement; (2) a prototype integrating pen‑based scribbles/annotations with text‑based inpainting; and (3) actionable insights into designers’ multimodal strategies, informing future interface designs that better support iterative refinement in AI‑augmented design workflows. The authors suggest future work on real‑time model integration, richer visual token representations, and collaborative multimodal prompting environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment