Learning Self-Correction in Vision-Language Models via Rollout Augmentation
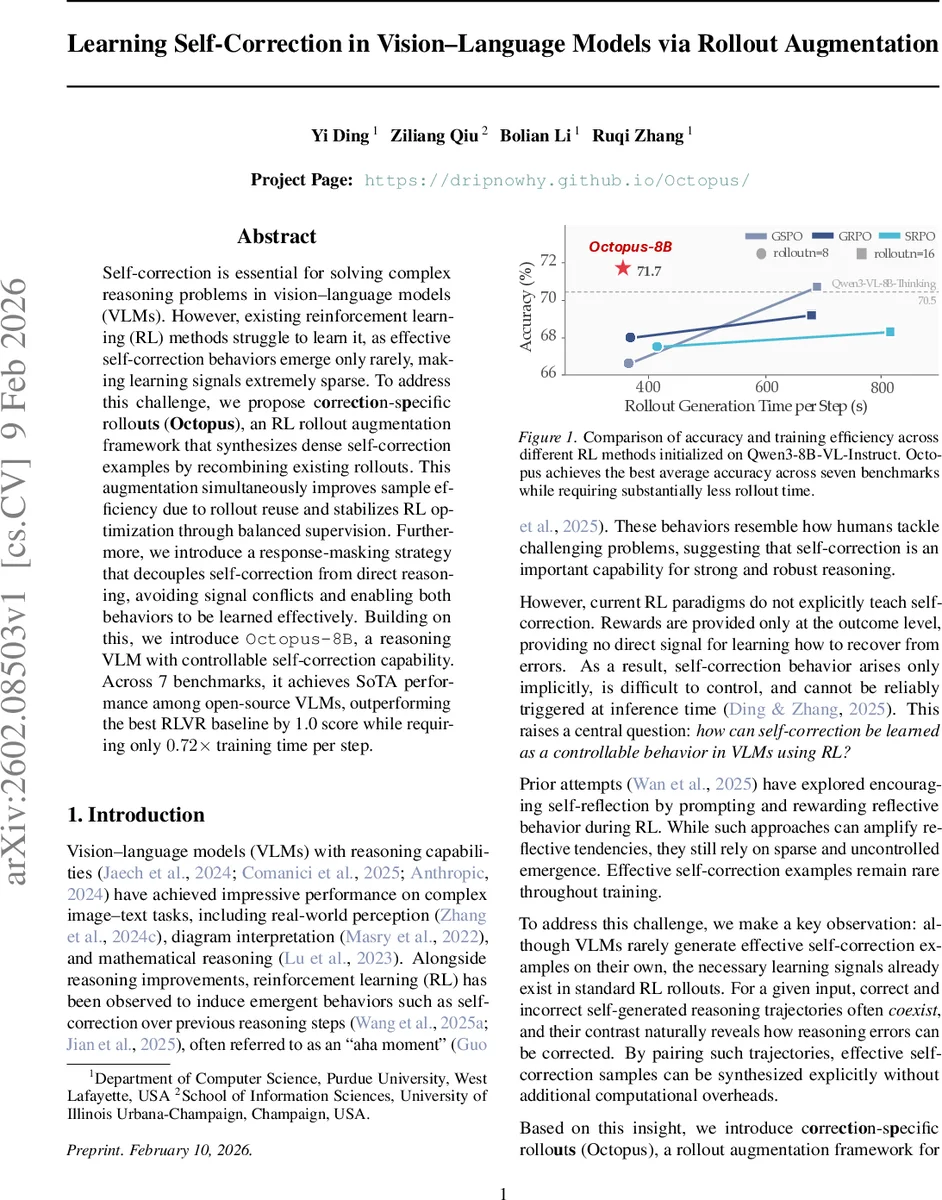
Self-correction is essential for solving complex reasoning problems in vision-language models (VLMs). However, existing reinforcement learning (RL) methods struggle to learn it, as effective self-correction behaviors emerge only rarely, making learning signals extremely sparse. To address this challenge, we propose correction-specific rollouts (Octopus), an RL rollout augmentation framework that synthesizes dense self-correction examples by recombining existing rollouts. This augmentation simultaneously improves sample efficiency due to rollout reuse and stabilizes RL optimization through balanced supervision. Furthermore, we introduce a response-masking strategy that decouples self-correction from direct reasoning, avoiding signal conflicts and enabling both behaviors to be learned effectively. Building on this, we introduce Octopus-8B, a reasoning VLM with controllable self-correction capability. Across 7 benchmarks, it achieves SoTA performance among open-source VLMs, outperforming the best RLVR baseline by 1.0 score while requiring only $0.72\times$ training time per step.
💡 Research Summary
The paper tackles the problem of teaching self‑correction to vision‑language models (VLMs) that are required to solve complex reasoning tasks. Existing reinforcement‑learning (RL) approaches, such as RL with verifiable rewards (RLVR), provide reward only at the final outcome, which makes “wrong → correct” correction signals extremely sparse. Empirical analysis shows that even with prompting tricks the proportion of effective self‑correction transitions stays below 1 % of all rollouts, severely limiting learning.
To overcome this sparsity, the authors introduce Octopus, a rollout‑augmentation framework that synthesizes dense self‑correction examples by recombining the components of standard RL rollouts. The method works as follows: (1) the policy is first asked to generate rollouts in an explicit self‑correction format o₁ ⊕ <sc> marks the start of a correction. (2) All pre‑correction responses o₁ and all post‑correction responses o₂ are collected across a batch of n rollouts. (3) By pairing any o₁ with any o₂, the algorithm creates n² new “paired rollouts”. These pairs fall into four categories: wrong → correct (positive), correct → correct (positive), correct → wrong (negative), and wrong → wrong (negative). (4) From this pool, a balanced subset (equal numbers of positive and negative examples) is selected for the actual RL update, while the original n rollouts are retained to preserve on‑policy data. In practice the authors use n = 8 and a total batch size N = 16, yielding 64 augmented rollouts, from which 16 balanced samples are drawn. This augmentation dramatically increases the density of self‑correction signals without any extra forward passes, improving sample efficiency and stabilizing policy updates.
A second challenge is the conflict between direct reasoning and self‑correction under a binary reward (1 for correct final answer, 0 otherwise). The model can achieve the reward either by answering correctly before <sc> (direct reasoning) or by correcting an earlier mistake after <sc> (self‑correction). When both signals are combined in a single loss, the gradients interfere, leading to reward hacking or unstable training. The authors propose a response‑masking strategy to decouple the two signals. During the first stage of RL training, the pre‑correction segment o₁ is masked and regularized with a KL term, so that only the post‑correction segment o₂ receives the reward gradient. In a second stage, the mask on o₁ is lifted only for samples where the reward for o₁ and o₂ do not conflict, allowing the model to learn both abilities without mutual interference.
Before applying Octopus, a cold‑start phase is required to teach the model the self‑correction format. Two data‑construction strategies are explored: (i) in‑distribution sampling, where both o₁ and o₂ are generated by the base policy, and (ii) mixed sampling, where o₁ comes from the base policy but o₂ is generated by a stronger “correction” model conditioned on the input, o₁, and the ground‑truth answer. Mixed sampling yields higher‑quality corrections and prevents entropy collapse, leading to more stable RL training. Experiments confirm that mixed sampling outperforms pure in‑distribution sampling in both entropy dynamics and final accuracy.
The authors evaluate Octopus‑8B, built on Qwen‑3‑VL‑8B‑Instruct, on seven diverse benchmarks covering mathematical reasoning, diagram interpretation, and real‑world image‑text tasks. Compared with the base model, Octopus‑8B improves average accuracy by 9.5 points. Against the strongest open‑source RL baseline (GSPO), it gains an additional 1.0 point while requiring only 0.72× the rollout time per training step, demonstrating both performance and efficiency gains. Ablation studies show that (a) removing the augmentation eliminates the dense correction signal and degrades performance, (b) disabling response masking causes the two objectives to clash and destabilizes training, and (c) using only in‑distribution sampling leads to early entropy collapse and poorer results.
The paper’s contributions are threefold: (1) identifying the sparsity of self‑correction signals as a core bottleneck in RL for VLMs, (2) proposing Octopus, a rollout‑recombination augmentation that creates dense, balanced correction examples without extra computation, and (3) introducing a response‑masking optimization that cleanly separates direct reasoning from correction learning. Limitations include the focus on single‑pass self‑correction; multi‑step correction, tool‑assisted reasoning, and human‑in‑the‑loop feedback remain open research directions. Moreover, scalability to larger models (e.g., 30 B parameters) and broader domains needs further validation.
In summary, Octopus provides a practical and theoretically sound pathway to endow vision‑language models with controllable self‑correction capabilities, achieving state‑of‑the‑art results among open‑source VLMs while reducing training cost. This work paves the way for more robust, self‑repairing multimodal AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment