Dynamic Long Context Reasoning over Compressed Memory via End-to-End Reinforcement Learning
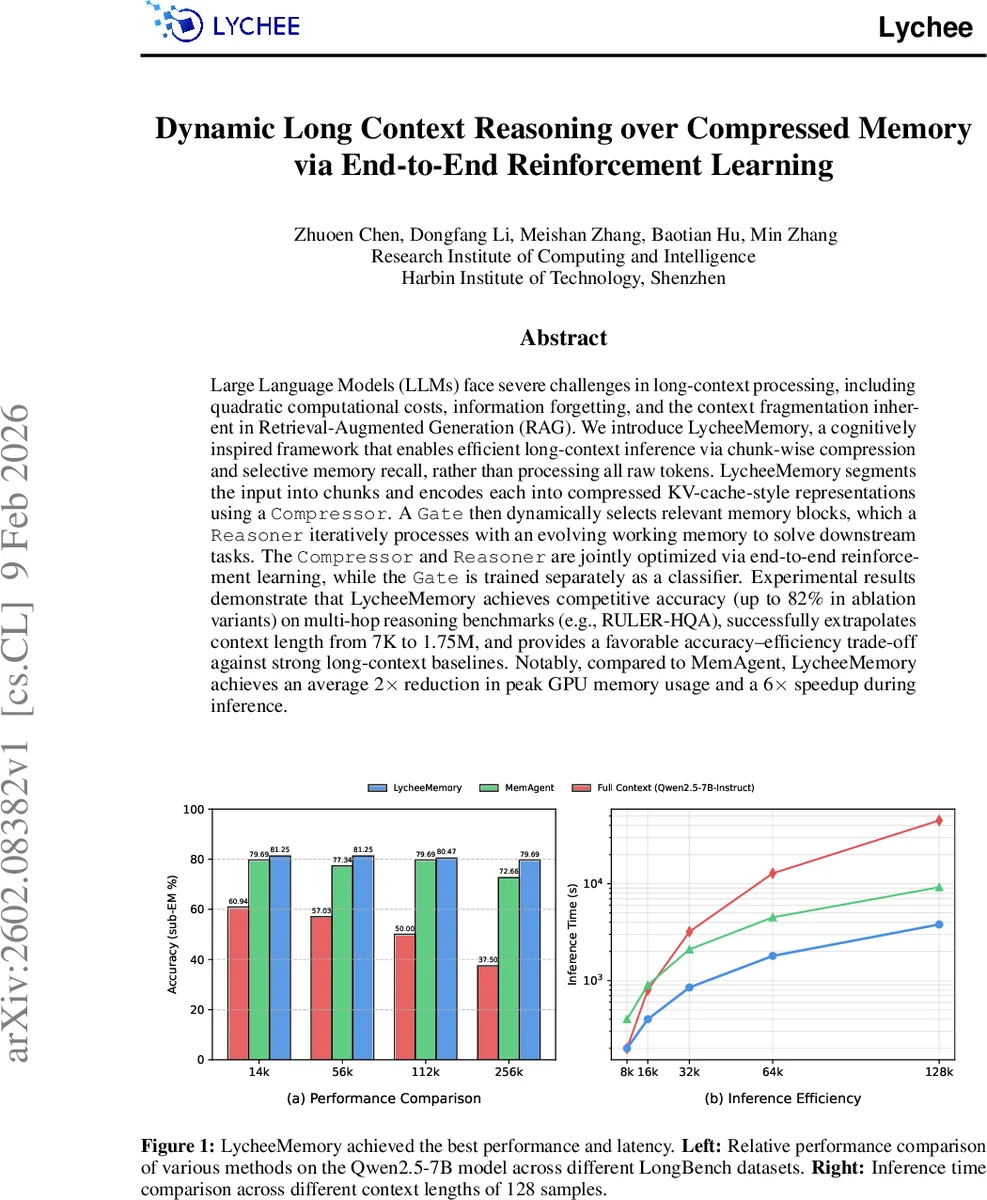
Large Language Models (LLMs) face significant challenges in long-context processing, including quadratic computational costs, information forgetting, and the context fragmentation inherent in retrieval-augmented generation (RAG). We propose a cognitively inspired framework for efficient long-context inference based on chunk-wise compression and selective memory recall, rather than processing all raw tokens. The framework segments long inputs into chunks and encodes each chunk into compressed memory representations using a learned compressor. A gating module dynamically selects relevant memory blocks, which are then iteratively processed by a reasoning module with an evolving working memory to solve downstream tasks. The compressor and reasoner are jointly optimized via end-to-end reinforcement learning, while the gating module is trained separately as a classifier. Experimental results show that the proposed method achieves competitive accuracy on multi-hop reasoning benchmarks such as RULER-HQA, extrapolates context length from 7K to 1.75M tokens, and offers a favorable accuracy-efficiency trade-off compared to strong long-context baselines. In particular, it achieves up to a 2 times reduction in peak GPU memory usage and a 6 times inference speedup over MemAgent.
💡 Research Summary
The paper tackles the fundamental bottleneck of processing ultra‑long contexts with large language models (LLMs), namely the quadratic cost of self‑attention, catastrophic forgetting, and the fragmentation caused by Retrieval‑Augmented Generation (RAG). Inspired by human memory architecture, the authors propose LycheeMemory, a dual‑system framework that separates long‑term compressed storage from a short‑term working memory and orchestrates their interaction through a learned gating mechanism and a reasoning module.
Compressed Memory Construction
The input document D is split into equal‑sized chunks (default 4096 tokens). For each chunk C_i, a compression ratio α_i is chosen, and a set of trainable “memory tokens” V_i of size z_i = |C_i|/α_i is interleaved after every α_i original tokens, forming an interleaved sequence C′_i. This sequence is passed once through a base LLM Φ augmented with a LoRA compression module Ψ_comp. The hidden states of the memory tokens become the compact KV‑cache representation θ_i, which is stored in the compressed memory bank Θ = {θ_1,…,θ_K}. The compression module is pre‑trained on three auxiliary tasks—text reconstruction, question‑answer generation, and creative generation—while the base model Φ remains frozen. This ensures that θ_i retains essential semantics despite aggressive compression (up to 1/64 of the original token count).
Dynamic Recall and Reasoning
During inference, a query Q is given and an empty working memory m_0 (a plain‑text token window) is initialized. The system scans the compressed memory bank sequentially. At step i, a gating module Φ_gate (a LoRA‑enhanced classifier) evaluates the relevance of θ_i conditioned on the current working memory m_t and the query Q, producing a score s_i. If s_i exceeds a threshold τ, the reasoning module Φ_reason (another LoRA‑enhanced LLM) is invoked:
m_{t+1} = Φ_reason(m_t, θ_i, Q)
Otherwise the chunk is skipped and m_t is unchanged. The working memory is always represented as actual tokens, allowing the model to generate interpretable intermediate states and to perform multi‑hop reasoning where later evidence becomes relevant only after earlier hops have been integrated. After scanning, the final answer A is generated conditioned on the final working memory m_T and Q.
Training Strategy
The compressor and reasoner are jointly optimized as a single policy π_θ in a reinforcement‑learning (RL) framework. The reward combines downstream QA accuracy with a penalty for memory usage, encouraging the model to both retrieve the right evidence and keep the compressed representations compact. Policy gradients (e.g., REINFORCE or PPO) are used to update Ψ_comp and Ψ_reason while the base model Φ stays frozen. The gate is trained separately as a binary classifier on synthetic (chunk, query) relevance labels, which simplifies credit assignment and stabilizes training. This staged optimization mitigates the mismatch between compression objectives and downstream reasoning objectives.
Complexity and Empirical Results
The authors provide a FLOPs analysis showing that total computation scales as O(K·sz·α^{-1}), a dramatic reduction compared to processing the full sequence. Peak GPU memory is proportional to the size of the compressed KV‑cache, yielding up to a 2× reduction versus the MemAgent baseline. Experiments are conducted on Qwen2.5‑7B‑Instruct and evaluated on multi‑hop benchmarks: RULER‑HQA, WikiMultihopQA, and StreamingQA. LycheeMemory achieves competitive exact‑match scores (up to 82% in ablation variants) while scaling context length from 7 K to 1.75 M tokens with minimal accuracy loss. Inference speed is improved by up to 6×, and memory consumption is halved relative to MemAgent.
Error Analysis and Limitations
A detailed failure‑mode analysis reveals four dominant error categories: (1) Unidirectional dependency mismatch (35 % of errors) where the model fails to propagate information across hops; (2) Premature inference anchoring (21 %) where early evidence overly dominates the reasoning; (3) Compression‑induced hallucination (17 %) caused by overly aggressive token reduction; and (4) Miscellaneous errors (27 %). The authors suggest adaptive compression ratios, richer gating conditioning, and curriculum‑based RL as future mitigations.
Conclusion
LycheeMemory demonstrates that compressing long documents into KV‑cache style memory, combined with a reinforcement‑learned policy for selective recall and iterative reasoning, can dramatically improve the efficiency‑accuracy trade‑off for ultra‑long context tasks. The framework bridges explicit (retrievable) and implicit (latent) memory paradigms, offering both scalability and interpretability. Its design is modular, allowing integration with other LLM backbones, and opens avenues for applications such as long‑form question answering, continuous dialogue, and multimodal long‑term memory systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment