InfiCoEvalChain: A Blockchain-Based Decentralized Framework for Collaborative LLM Evaluation
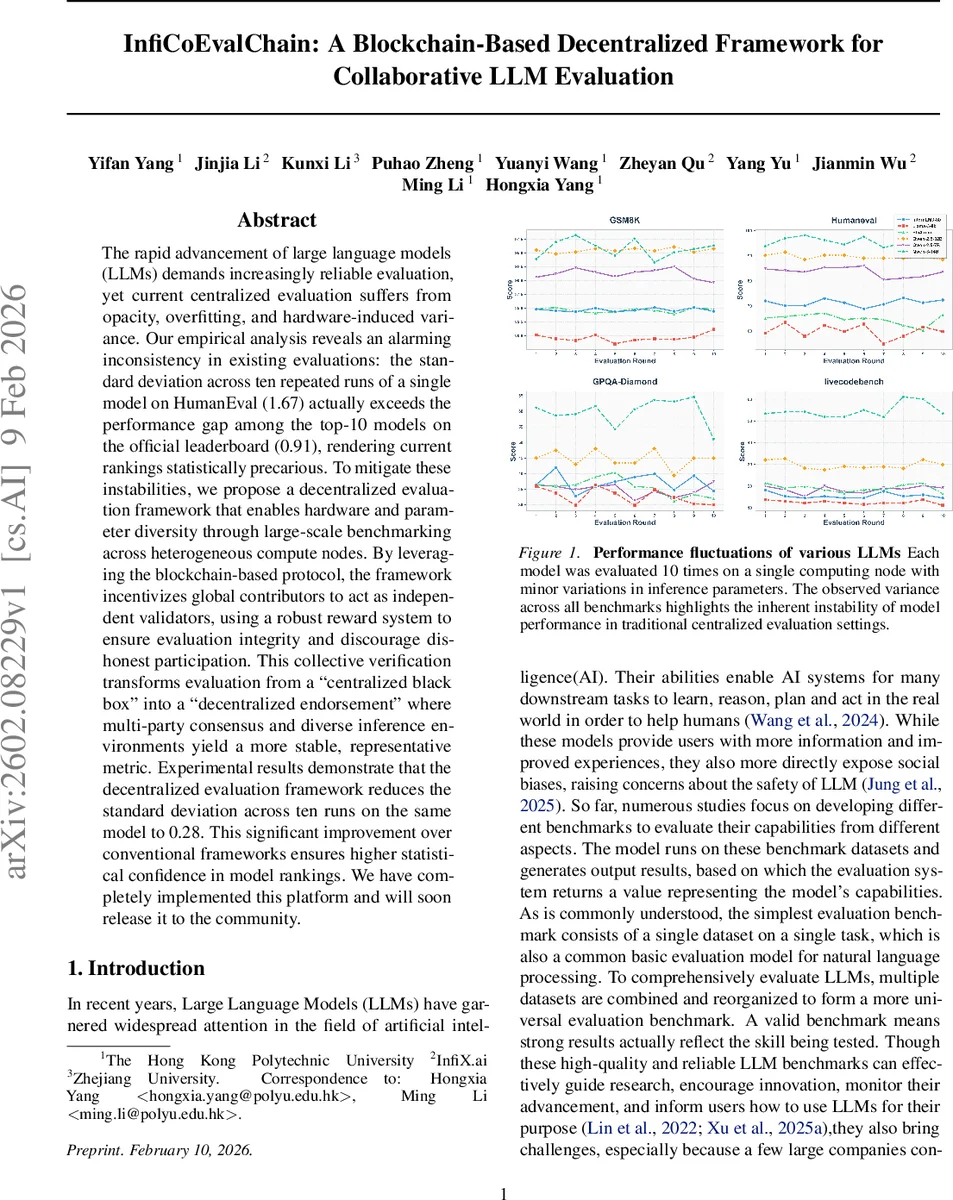
The rapid advancement of large language models (LLMs) demands increasingly reliable evaluation, yet current centralized evaluation suffers from opacity, overfitting, and hardware-induced variance. Our empirical analysis reveals an alarming inconsistency in existing evaluations: the standard deviation across ten repeated runs of a single model on HumanEval (1.67) actually exceeds the performance gap among the top-10 models on the official leaderboard (0.91), rendering current rankings statistically precarious. To mitigate these instabilities, we propose a decentralized evaluation framework that enables hardware and parameter diversity through large-scale benchmarking across heterogeneous compute nodes. By leveraging the blockchain-based protocol, the framework incentivizes global contributors to act as independent validators, using a robust reward system to ensure evaluation integrity and discourage dishonest participation. This collective verification transforms evaluation from a “centralized black box” into a “decentralized endorsement” where multi-party consensus and diverse inference environments yield a more stable, representative metric. Experimental results demonstrate that the decentralized evaluation framework reduces the standard deviation across ten runs on the same model to 0.28. This significant improvement over conventional frameworks ensures higher statistical confidence in model rankings. We have completely implemented this platform and will soon release it to the community.
💡 Research Summary
The paper begins by diagnosing a fundamental problem in the current evaluation of large language models (LLMs): the scores reported on popular benchmarks are highly sensitive to stochastic sampling, hardware differences, and minor inference‑parameter changes. The authors demonstrate this instability empirically: a single model run ten times on HumanEval yields a standard deviation of 1.67, which exceeds the performance gap among the top‑10 models on the official leaderboard (0.91). Consequently, existing rankings are statistically fragile and may reflect environmental noise rather than true capability differences.
To address these issues, the authors propose InfiCoEvalChain (also called CoEvalChain), a decentralized evaluation framework built on blockchain technology. The system consists of two synergistic layers. The upper “collaborative” layer aggregates heterogeneous compute resources—from individual GPUs to institutional clusters—allowing the same model to be evaluated across a wide spectrum of hardware architectures, GPU models, and inference settings (temperature, top‑k, etc.). The lower “blockchain” layer provides a peer‑to‑peer ledger that records every evaluation run immutably, enforces fair participation through token staking, and distributes rewards and penalties via smart contracts.
A rigorous statistical analysis underpins the design. Modeling the output space as |Y| = T^L, the authors define the expected output and quantify deviation using binary cross‑entropy loss. By invoking the Central Limit Theorem, they derive a lower bound on the number of independent evaluations needed to achieve a desired confidence level: for a confidence of 80 % and a margin of error ε = 0.04, at least 28 independent runs are required. This calculation justifies the need for a large, diverse pool of evaluators to neutralize stochastic noise.
Consensus is achieved through a game‑theoretic Schelling point mechanism combined with a cryptographic commit‑reveal protocol. Participants first submit a hash of their score and a random salt (commit phase), then later reveal the actual score and salt. The smart contract verifies the commitment and aggregates all revealed scores. The “focal point” score that maximizes salience across participants is selected as the final consensus value. Token staking serves as a Sybil‑resistance barrier, ensuring that evaluators have “skin in the game.” Honest behavior is incentivized with token rewards proportional to evaluation quality, while dishonest or duplicated submissions incur penalties.
The experimental evaluation spans four representative benchmarks—GSM8K, HumanEval, GPQA‑Diamond, and LiveCodeBench—and multiple hardware configurations (e.g., RTX 3090, A100). Across 1,200 evaluation instances, the decentralized framework reduces the standard deviation of repeated runs from an average of 1.67 (centralized baseline) to 0.28. This dramatic reduction stabilizes leaderboard rankings, making performance gaps statistically distinguishable. The authors also report that the system successfully records all runs on-chain, prevents result tampering, and fairly distributes incentives.
A functional prototype has been fully implemented on a public blockchain, and the authors plan to release the codebase to the community. Future work includes optimizing evaluation cost, extending the framework to multimodal tasks, and refining governance mechanisms. In summary, InfiCoEvalChain offers a transparent, reproducible, and statistically robust alternative to traditional centralized LLM evaluation, promising more reliable model comparison for both research and industry applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment