Vision Transformer Finetuning Benefits from Non-Smooth Components
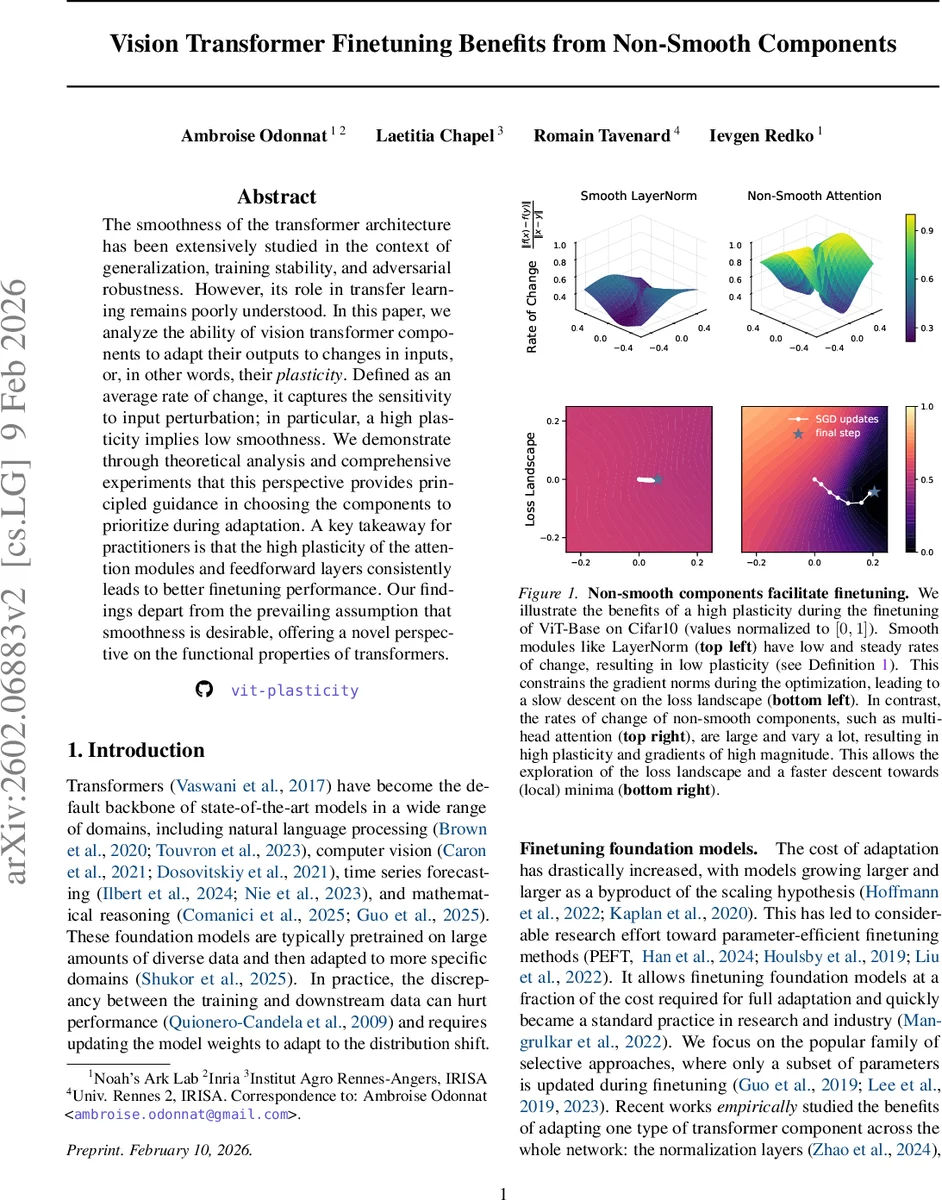
The smoothness of the transformer architecture has been extensively studied in the context of generalization, training stability, and adversarial robustness. However, its role in transfer learning remains poorly understood. In this paper, we analyze the ability of vision transformer components to adapt their outputs to changes in inputs, or, in other words, their plasticity. Defined as an average rate of change, it captures the sensitivity to input perturbation; in particular, a high plasticity implies low smoothness. We demonstrate through theoretical analysis and comprehensive experiments that this perspective provides principled guidance in choosing the components to prioritize during adaptation. A key takeaway for practitioners is that the high plasticity of the attention modules and feedforward layers consistently leads to better finetuning performance. Our findings depart from the prevailing assumption that smoothness is desirable, offering a novel perspective on the functional properties of transformers. The code is available at https://github.com/ambroiseodt/vit-plasticity.
💡 Research Summary
The paper investigates how the intrinsic functional properties of individual components in Vision Transformers (ViTs) affect fine‑tuning performance. The authors introduce a quantitative measure called “plasticity,” defined as the expected average rate of change of a module’s output with respect to perturbations in its input:
P(f) = E_{(x,y)}
Comments & Academic Discussion
Loading comments...
Leave a Comment