Emergent Search and Backtracking in Latent Reasoning Models
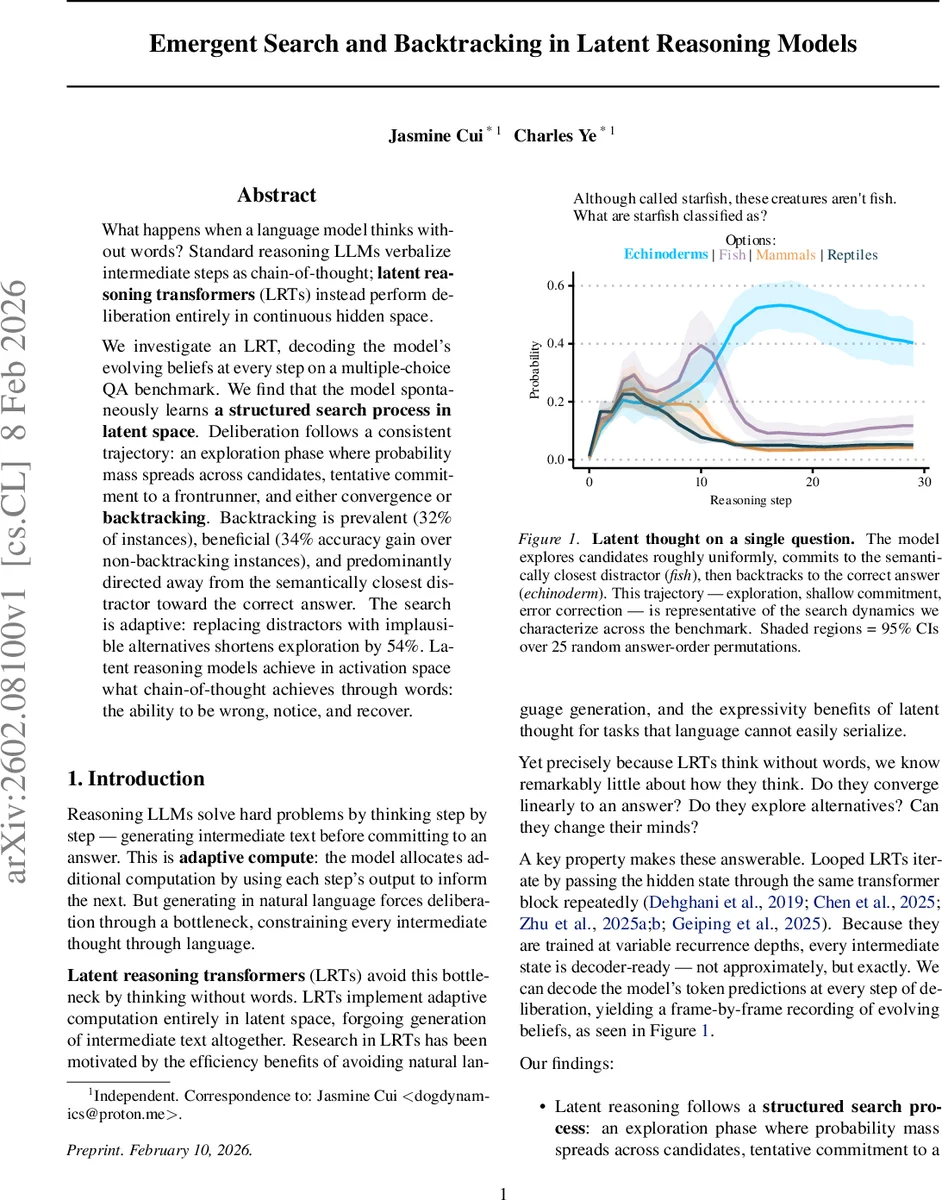
What happens when a language model thinks without words? Standard reasoning LLMs verbalize intermediate steps as chain-of-thought; latent reasoning transformers (LRTs) instead perform deliberation entirely in continuous hidden space. We investigate an LRT, decoding the model’s evolving beliefs at every step on a multiple-choice QA benchmark. We find that the model spontaneously learns a structured search process in latent space. Deliberation follows a consistent trajectory: an exploration phase where probability mass spreads across candidates, tentative commitment to a frontrunner, and either convergence or backtracking. Backtracking is prevalent (32% of instances), beneficial (34% accuracy gain over non-backtracking instances), and predominantly directed away from the semantically closest distractor toward the correct answer. The search is adaptive: replacing distractors with implausible alternatives shortens exploration by 54%. Latent reasoning models achieve in activation space what chain-of-thought achieves through words: the ability to be wrong, notice, and recover.
💡 Research Summary
This paper investigates the internal reasoning dynamics of a looped latent reasoning transformer (LRT), a class of language models that perform adaptive computation entirely in hidden space without generating intermediate text. The authors study a 3.5 B‑parameter model named HUGINN‑0125, which consists of a prelude (embedding + 2 transformer layers), a recurrent block (4 transformer layers iterated K = 30 times), and a coda (2 transformer layers plus the language‑model head). Because the model is trained with randomly sampled recurrence depths, every intermediate hidden state h_i is “decoder‑ready”: passing h_i through the coda yields an exact probability distribution p_i = softmax(C(h_i)) that the model would output if halted at that step. By decoding p_i at each iteration, the authors obtain a frame‑by‑frame record of the model’s evolving beliefs.
The experimental benchmark comprises 260 four‑choice questions covering factual recall, definitions, multi‑step logic, arithmetic, and adversarially misleading items. For each question three answer‑set variants are created: (1) Base – plausible distractors semantically related to the stem; (2) Easy – distractors that are clearly unrelated; (3) No correct answer – the true answer is replaced by an additional distractor. Each variant is evaluated under 25 random answer‑order permutations to control for position bias, and the model runs for 30 recurrent steps per permutation.
Analysis of the decoded belief trajectories reveals a consistent three‑phase search process. In the exploration phase, probability mass is spread roughly uniformly across the four options and the KL‑divergence between successive p_i is high, indicating active searching. In the shallow commitment phase, one option begins to dominate; this option is typically the distractor that is most semantically similar to the question stem, suggesting that early steps rely on surface‑level embedding similarity. Finally, in the convergence or backtracking phase, the model either solidifies its commitment or reverses it. A backtracking event is defined as a trajectory where the argmax answer stays constant for at least three consecutive steps, later switches to a different answer for at least three steps, and ends with the new answer.
Backtracking occurs in 32 % of Base‑variant instances. When it happens, the abandoned answer is the most semantically similar distractor 72 % of the time—far above the 25 % chance level for four options. Moreover, 52 % of backtracking events end with the correct answer, and overall accuracy on backtracking instances is 34 % higher than on non‑backtracking instances. This demonstrates that backtracking is not random noise but a systematic error‑correction mechanism that moves the model from a shallow semantic match to the true answer.
Task difficulty modulates the length of the exploration phase. Using KL‑divergence as a stopping criterion (exploration ends when D_KL(p_{i+1}‖p_i) ≤ 0.01 for three consecutive steps), Base questions explore for 54 % more steps than Easy questions. In the No‑correct‑answer condition, entropy remains high throughout all 30 steps, and the model never settles into a low‑entropy attractor, indicating that it recognizes persistent uncertainty when no valid option exists.
The authors argue that these dynamics constitute a latent form of the structured reasoning observed in chain‑of‑thought (CoT) prompting. CoT also exhibits iterative computation—each generated token feeds back into the model—but it couples reasoning with the additional objective of producing human‑readable text, which can introduce unfaithful rationales. By removing the language bottleneck, LRT reveals a pure search‑commit‑correct cycle: fast, approximate filtering based on surface similarity, followed by slower verification and, when needed, backtracking.
The paper highlights several implications. First, looped LRTs provide a uniquely transparent window into adaptive compute because every intermediate state can be decoded exactly, unlike black‑box iterative architectures where internal steps are inferred. Second, the emergence of backtracking suggests that models can discover efficient two‑timescale strategies without explicit supervision. Third, the difficulty‑adaptive behavior demonstrates that latent reasoning allocates compute proportionally to problem hardness.
Limitations include the focus on a single 3.5 B model and a relatively small synthetic benchmark; it remains open whether larger LRTs, open‑ended generation tasks, or non‑looped adaptive architectures exhibit the same search‑backtrack dynamics. Future work should explore scaling, generalization to real‑world datasets, and potential ways to harness backtracking for more reliable reasoning.
In summary, by decoding every recurrent step of a latent reasoning transformer, the authors uncover a spontaneous, structured search process: uniform exploration, shallow commitment to the most semantically similar distractor, and systematic backtracking that often restores the correct answer. This latent search mirrors the functional role of chain‑of‑thought reasoning but operates without the constraints of natural‑language generation, offering new insights into how large language models can think without words.
Comments & Academic Discussion
Loading comments...
Leave a Comment