TAAM:Inductive Graph-Class Incremental Learning with Task-Aware Adaptive Modulation
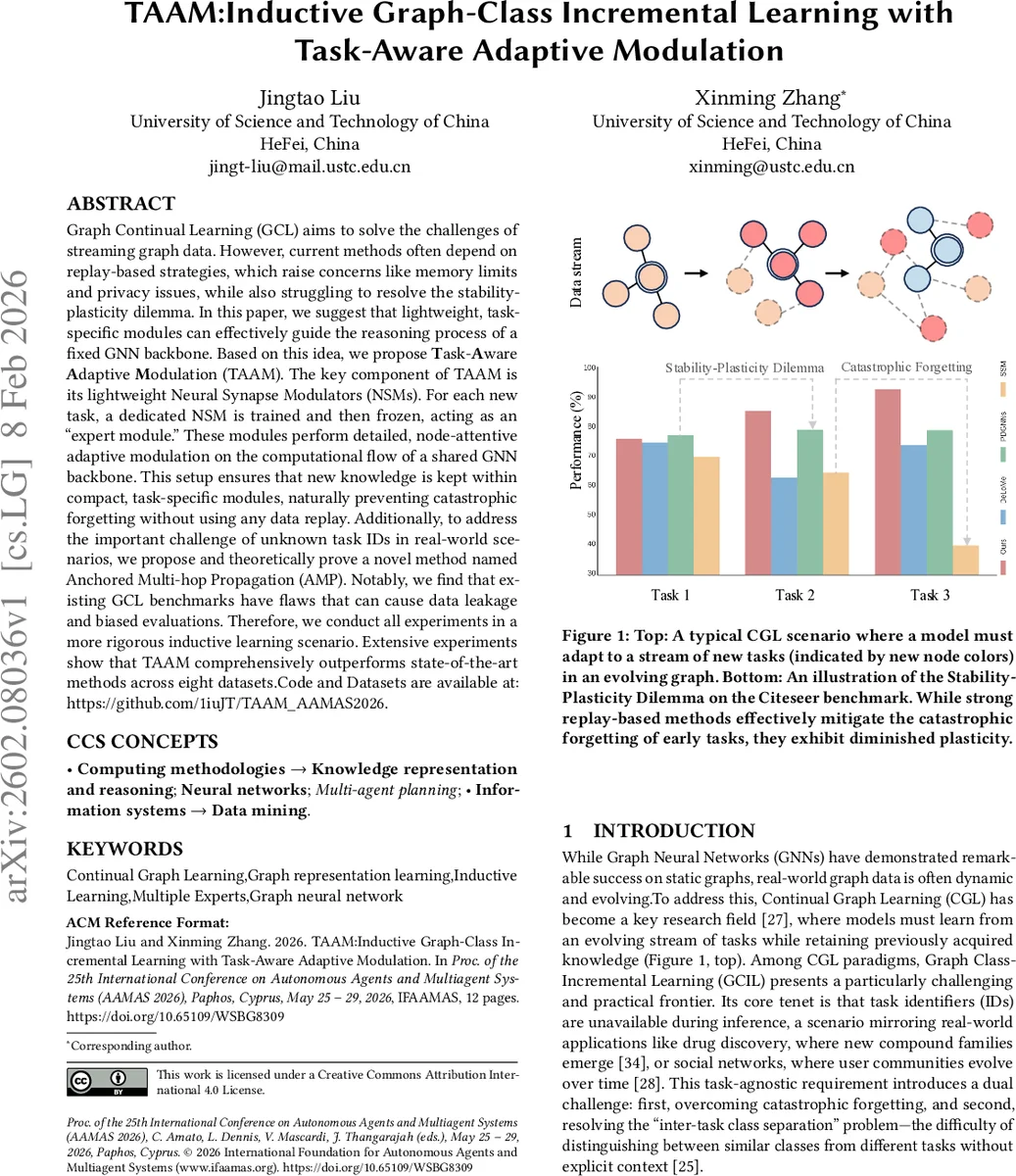
Graph Continual Learning (GCL) aims to solve the challenges of streaming graph data. However, current methods often depend on replay-based strategies, which raise concerns like memory limits and privacy issues, while also struggling to resolve the stability-plasticity dilemma. In this paper, we suggest that lightweight, task-specific modules can effectively guide the reasoning process of a fixed GNN backbone. Based on this idea, we propose Task-Aware Adaptive Modulation (TAAM). The key component of TAAM is its lightweight Neural Synapse Modulators (NSMs). For each new task, a dedicated NSM is trained and then frozen, acting as an “expert module.” These modules perform detailed, node-attentive adaptive modulation on the computational flow of a shared GNN backbone. This setup ensures that new knowledge is kept within compact, task-specific modules, naturally preventing catastrophic forgetting without using any data replay. Additionally, to address the important challenge of unknown task IDs in real-world scenarios, we propose and theoretically prove a novel method named Anchored Multi-hop Propagation (AMP). Notably, we find that existing GCL benchmarks have flaws that can cause data leakage and biased evaluations. Therefore, we conduct all experiments in a more rigorous inductive learning scenario. Extensive experiments show that TAAM comprehensively outperforms state-of-the-art methods across eight datasets. Code and Datasets are available at: https://github.com/1iuJT/TAAM_AAMAS2026.
💡 Research Summary
Graph continual learning (GCL) faces two fundamental challenges: catastrophic forgetting when learning a stream of tasks, and the lack of task identifiers at inference time, especially in graph class‑incremental learning (GCIL) where each task introduces a disjoint set of node classes. Existing solutions fall into three categories. Replay‑based methods store a memory buffer of past examples and rehearse them together with new data; while effective, they incur high memory, computational, and privacy costs. Parameter‑isolation approaches allocate separate parameters per task but typically rely on a large pre‑trained backbone to transfer knowledge, which is rarely available for graphs. Prompt‑based PETL (parameter‑efficient transfer learning) inserts lightweight prompts into a frozen model, yet its performance also depends heavily on a strong pre‑trained GNN and often provides only coarse control over the network’s internal flow.
The paper proposes TAAM (Task‑Aware Adaptive Modulation), a replay‑free framework that eliminates the need for any pre‑trained model while preserving both stability and plasticity. TAAM consists of two core components: (1) a frozen Simple Graph Convolution (SGC) backbone that serves as a stable feature extractor, and (2) a set of task‑specific Neural Synapse Modulators (NSMs). For each new task τ_k, a fresh NSM_k is instantiated and trained; after training it is frozen, becoming an “expert module.” Each NSM generates node‑wise FiLM (Feature‑wise Linear Modulation) parameters (γ_i, β_i) that adapt the SGC’s output. The modulation parameters are produced efficiently via low‑rank factorization: a task embedding e_k is projected to H base modulation vectors M_k, and per‑node attention weights a_i (computed from the node’s feature) weight‑combine these bases to obtain the final FiLM coefficients. This design yields fine‑grained, node‑attentive control with only a few hundred additional parameters per task.
Because task IDs are unavailable during inference, TAAM introduces Anchored Multi‑hop Propagation (AMP) to infer the correct expert. AMP runs an APPNP‑style propagation (Z^{(i+1)} = (1‑α)SZ^{(i)} + αH^{(0)}) for multiple hop depths ℎ_1 … ℎ_m, concatenates the resulting representations, and averages them over the training nodes of a task to obtain a prototype vector p_k. At test time, a prototype for the incoming graph is generated in the same way, and the most similar stored prototype (cosine similarity) determines which NSM to apply. The authors provide a theoretical justification for AMP’s discriminative power and demonstrate empirically that it reliably distinguishes tasks even when class distributions overlap.
A major methodological contribution is the shift from the usual transductive benchmarks (where training and test nodes belong to the same graph) to a fully inductive setting: each task’s training graphs G_train^k are completely disjoint from its test graphs G_test^k. This eliminates data leakage and better reflects real‑world scenarios such as emerging drug families or evolving social communities.
Experiments on eight public graph datasets (including Cora, Citeseer, Pubmed, Amazon‑Computers, etc.) show that TAAM consistently outperforms state‑of‑the‑art replay‑based, prompt‑based, and parameter‑isolation methods. The gains are especially pronounced in low‑memory regimes, where TAAM uses only the frozen backbone plus a handful of NSMs, achieving up to an order of magnitude reduction in memory footprint compared to replay baselines. Training time per task remains comparable, and inference overhead is modest (prototype similarity search plus a forward pass through the selected NSM).
The paper also discusses limitations. The number of NSMs grows linearly with the number of tasks, which could become a scalability bottleneck for very long task streams. The current implementation uses a simple SGC backbone; extending TAAM to deeper, attention‑based GNNs may further improve performance but requires additional investigation. Moreover, AMP relies on mean‑based prototypes; tasks with highly similar structural patterns could cause prototype confusion, suggesting future work on prototype regularization or meta‑learning‑based task discrimination.
In summary, TAAM introduces a novel paradigm—task‑specific lightweight modulators combined with multi‑scale prototype inference—that achieves replay‑free graph continual learning with strong stability‑plasticity trade‑offs. It sets a new benchmark for inductive GCIL and opens avenues for scalable, privacy‑preserving continual learning on graph data.
Comments & Academic Discussion
Loading comments...
Leave a Comment