Agent Skills: A Data-Driven Analysis of Claude Skills for Extending Large Language Model Functionality
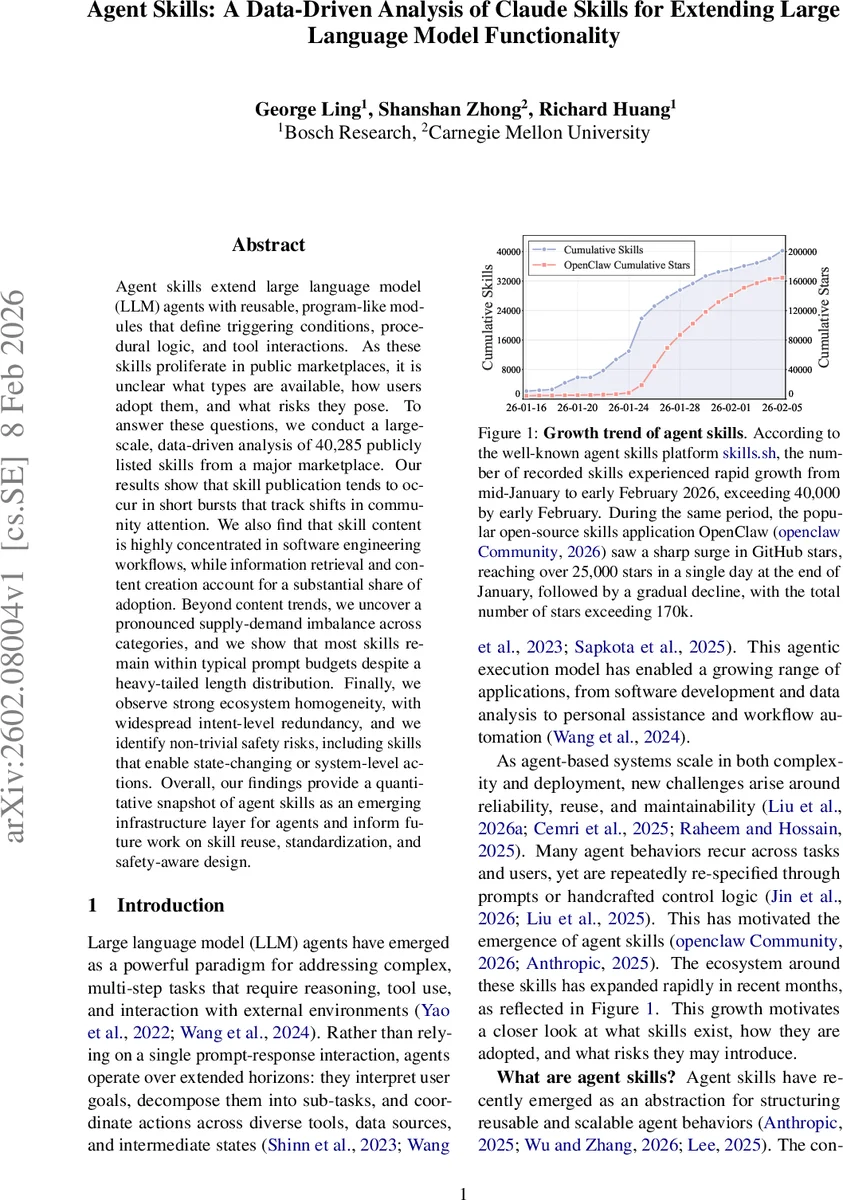
Agent skills extend large language model (LLM) agents with reusable, program-like modules that define triggering conditions, procedural logic, and tool interactions. As these skills proliferate in public marketplaces, it is unclear what types are available, how users adopt them, and what risks they pose. To answer these questions, we conduct a large-scale, data-driven analysis of 40,285 publicly listed skills from a major marketplace. Our results show that skill publication tends to occur in short bursts that track shifts in community attention. We also find that skill content is highly concentrated in software engineering workflows, while information retrieval and content creation account for a substantial share of adoption. Beyond content trends, we uncover a pronounced supply-demand imbalance across categories, and we show that most skills remain within typical prompt budgets despite a heavy-tailed length distribution. Finally, we observe strong ecosystem homogeneity, with widespread intent-level redundancy, and we identify non-trivial safety risks, including skills that enable state-changing or system-level actions. Overall, our findings provide a quantitative snapshot of agent skills as an emerging infrastructure layer for agents and inform future work on skill reuse, standardization, and safety-aware design.
💡 Research Summary
The paper presents a large‑scale, data‑driven measurement of the emerging “agent skill” ecosystem that augments large language model (LLM) agents with reusable, program‑like modules. The authors crawled the public marketplace skills.sh on February 5 2026 and collected metadata for 40,285 publicly listed Claude skills, including name, repository link, first‑seen date, and per‑platform install counts.
Growth analysis shows an explosive, bursty pattern: the catalog grew from 2,179 skills on 16 Jan 2026 to 40,285 on 5 Feb 2026, an 18.5× increase in just 20 days. The average daily influx was 1,918 skills, with a single peak of 8,857 new listings on 25 Jan 2026 (23 % of all new skills). This burst aligns tightly with a parallel surge in GitHub stars for the OpenClaw project, suggesting that heightened community attention drives both skill publication and exploration.
Token‑length measurement (using tiktoken’s o200k_base encoding) reveals a heavy‑tailed distribution. The median skill contains 1,414 tokens, the mean 1,895 tokens; 90 % are ≤ 3,935 tokens and 99 % ≤ 9,253 tokens. A small tail of outliers reaches up to 116,239 tokens, typically because a single file bundles multiple components (large documentation, code libraries, templates). While most skills comfortably fit within typical prompt budgets, the ultra‑long skills would consume the entire context and hinder reliable selection and auditing.
Redundancy is pronounced. The authors apply two methods: (1) exact name matching after lower‑casing and stripping punctuation, and (2) semantic similarity using the BAAI/bge‑m3 embedding model. Because descriptions are short and often templated, semantic matching does not reliably separate true duplicates, so the main results rely on name‑based grouping. Under exact matching, 53.7 % of skills appear only once, while 46.3 % share a normalized name with at least one other listing. Two‑fold duplicates account for 18.7 % of the corpus; 5‑ to 9‑fold groups cover 14.3 %; 10‑ to 49‑fold groups cover 8.8 %; a handful of names appear > 100 times, indicating repeated reposting or automated template generation. High redundancy inflates search costs, fragments feedback signals, and makes it harder for high‑quality implementations to become de‑facto defaults.
Functional taxonomy: the authors define a two‑level taxonomy with six major categories and twenty sub‑categories (Software Engineering, Information Retrieval, Productivity Tools, Data & Analytics, Content Creation, Utilities & Other). They automatically label each skill using Qwen2.5‑32B‑Instruct, feeding the skill’s name and description to a classifier that outputs a strict JSON record. The distribution is heavily skewed toward Software Engineering (≈ 50 % of skills), especially Code Generation, Debug & Analysis, Version Control, and Infrastructure. Information Retrieval (web/academic search, live data streams) and Productivity Tools (team communication, document systems, task management) also hold sizable shares. Data & Analytics and Content Creation categories contain fewer skills but exhibit longer average token lengths, reflecting more complex procedural logic.
Supply‑demand mismatch: by comparing the number of skills in each sub‑category with average install counts, the authors find that Software Engineering suffers from oversupply (many skills, relatively low installs), whereas Information Retrieval and Content Creation show undersupply (few skills, high installs). This suggests developers are over‑packaging well‑known engineering workflows, while end‑users primarily seek data‑search and content‑generation capabilities.
Safety audit: each skill’s code and metadata were examined for potentially hazardous actions. The majority (≈ 93 %) are classified as low risk, but about 7 % enable state‑changing or system‑level operations such as file deletion, command execution, network calls, or memory manipulation. These “medium/high” risk skills cluster in the Command Execution, Local File Control, and Memory & Cognition sub‑categories. Without robust permission models, sandboxing, or explicit risk labeling, such skills could be abused to compromise host environments.
The paper concludes that the agent‑skill ecosystem is growing rapidly but is already plagued by redundancy, quality fragmentation, supply‑demand imbalance, and non‑trivial safety hazards. The authors recommend (1) standardized skill registries with versioning, (2) automated de‑duplication and quality‑signal mechanisms, (3) clearer canonical skill definitions to reduce superficial reposts, and (4) stronger safety‑aware design practices—including permission scopes, sandboxed execution, and transparent risk labels. These steps are essential for maturing agent skills into a reliable infrastructure layer for LLM agents.
Comments & Academic Discussion
Loading comments...
Leave a Comment