HypRAG: Hyperbolic Dense Retrieval for Retrieval Augmented Generation
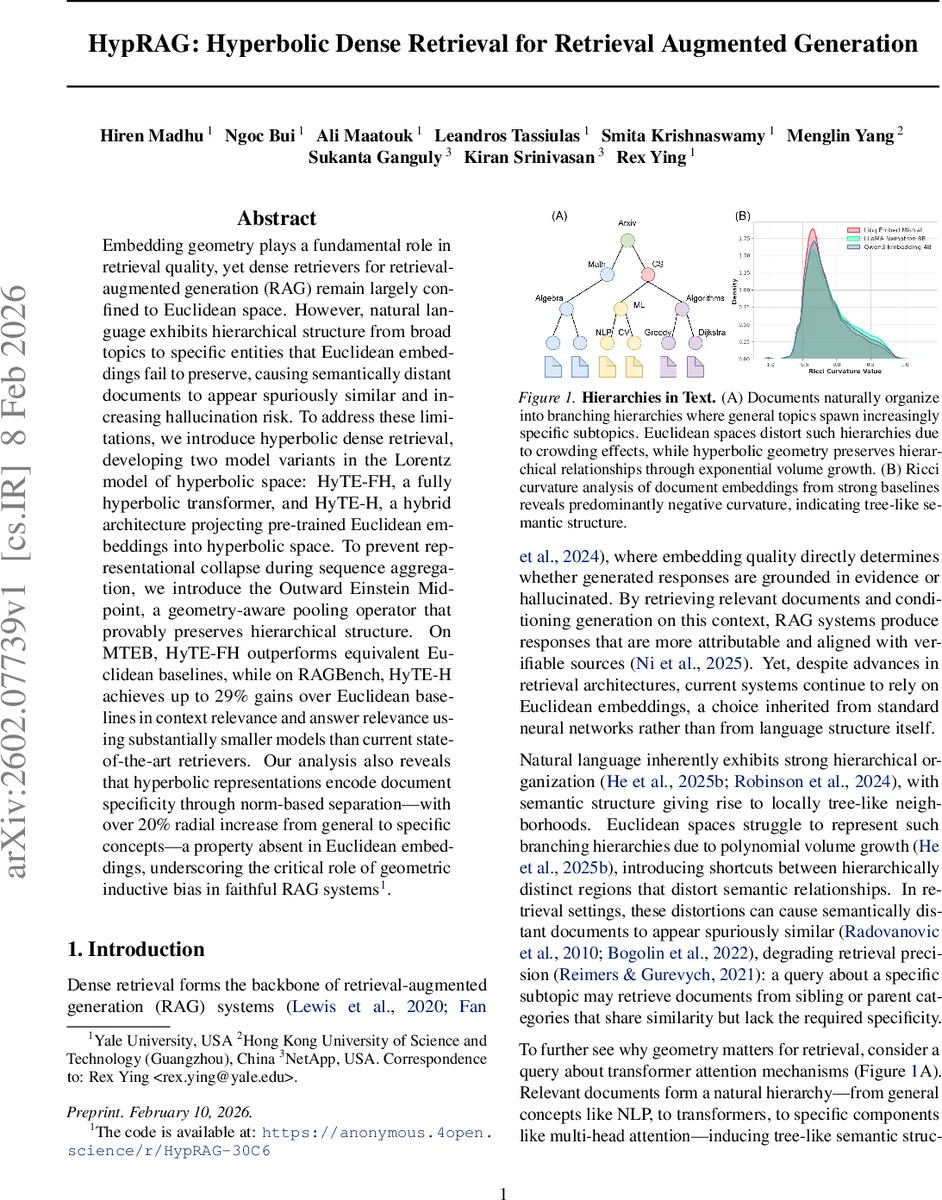
Embedding geometry plays a fundamental role in retrieval quality, yet dense retrievers for retrieval-augmented generation (RAG) remain largely confined to Euclidean space. However, natural language exhibits hierarchical structure from broad topics to specific entities that Euclidean embeddings fail to preserve, causing semantically distant documents to appear spuriously similar and increasing hallucination risk. To address these limitations, we introduce hyperbolic dense retrieval, developing two model variants in the Lorentz model of hyperbolic space: HyTE-FH, a fully hyperbolic transformer, and HyTE-H, a hybrid architecture projecting pre-trained Euclidean embeddings into hyperbolic space. To prevent representational collapse during sequence aggregation, we introduce the Outward Einstein Midpoint, a geometry-aware pooling operator that provably preserves hierarchical structure. On MTEB, HyTE-FH outperforms equivalent Euclidean baselines, while on RAGBench, HyTE-H achieves up to 29% gains over Euclidean baselines in context relevance and answer relevance using substantially smaller models than current state-of-the-art retrievers. Our analysis also reveals that hyperbolic representations encode document specificity through norm-based separation, with over 20% radial increase from general to specific concepts, a property absent in Euclidean embeddings, underscoring the critical role of geometric inductive bias in faithful RAG systems.
💡 Research Summary
The paper tackles a fundamental mismatch in Retrieval‑Augmented Generation (RAG) systems: dense retrievers embed queries and documents in Euclidean space, while natural language exhibits a hierarchical, tree‑like organization that Euclidean geometry cannot faithfully represent. The authors argue that this geometric mismatch leads to “crowding” effects where semantically distant documents appear spuriously similar, degrading retrieval precision and increasing the risk of hallucinations in downstream generation.
To address this, they introduce hyperbolic dense retrieval, operating in the Lorentz (hyperboloid) model of constant negative curvature. Two architectures are proposed:
-
HyTE‑FH (Fully Hyperbolic) – a transformer whose every component (linear layers, layer‑norm, residual connections, self‑attention) is reformulated to work directly on the Lorentz manifold. Attention scores are computed from squared hyperbolic geodesic distances, and the attended representation is obtained via a Lorentzian weighted midpoint, preserving the manifold constraints.
-
HyTE‑H (Hybrid) – a lighter variant that projects pretrained Euclidean embeddings (e.g., from BERT, LLaMA) onto the hyperboloid using a curvature‑aware scaling. This allows the model to benefit from strong Euclidean initializations while still exploiting hyperbolic geometry, and it reduces parameter count by 2‑3× compared with fully hyperbolic counterparts.
A central technical challenge is aggregating variable‑length token sequences into fixed‑size document embeddings. Naïve strategies (average in ambient space then re‑project) contract representations toward the origin because of hyperbolic convexity, erasing the radial depth that encodes concept specificity. The authors formalize this contraction (Proposition 4.3) and propose the Outward Einstein Midpoint pooling operator. This operator weights each token proportionally to its distance from the origin before computing a hyperbolic midpoint, thereby preserving or even amplifying radial separation during pooling.
Empirical evaluation proceeds on two fronts:
-
MTEB (Multi‑Task Embedding Benchmark) – HyTE‑FH surpasses Euclidean baselines across standard retrieval metrics (NDCG, Recall) despite identical dimensionality, confirming that hyperbolic embeddings improve generic dense retrieval.
-
RAGBench – When integrated into a full RAG pipeline, HyTE‑H delivers up to 29 % relative gains in both context relevance and answer relevance over strong Euclidean retrievers, while using substantially smaller models.
Additional analysis shows that hyperbolic embeddings naturally encode hierarchical depth: the average radial coordinate (the time‑like component) of embeddings for general topics is ~20 % smaller than for fine‑grained entities, a pattern absent in Euclidean spaces. This provides quantitative evidence that the curvature‑induced inductive bias captures the latent tree‑structure of language.
In summary, the work demonstrates that choosing a hyperbolic embedding space, together with a geometry‑aware pooling mechanism, yields measurable improvements in retrieval quality and downstream generation fidelity. It opens a promising research direction: building larger‑scale hyperbolic language models and extending hyperbolic representations to multimodal or knowledge‑graph‑enhanced RAG systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment