The Relative Instability of Model Comparison with Cross-validation
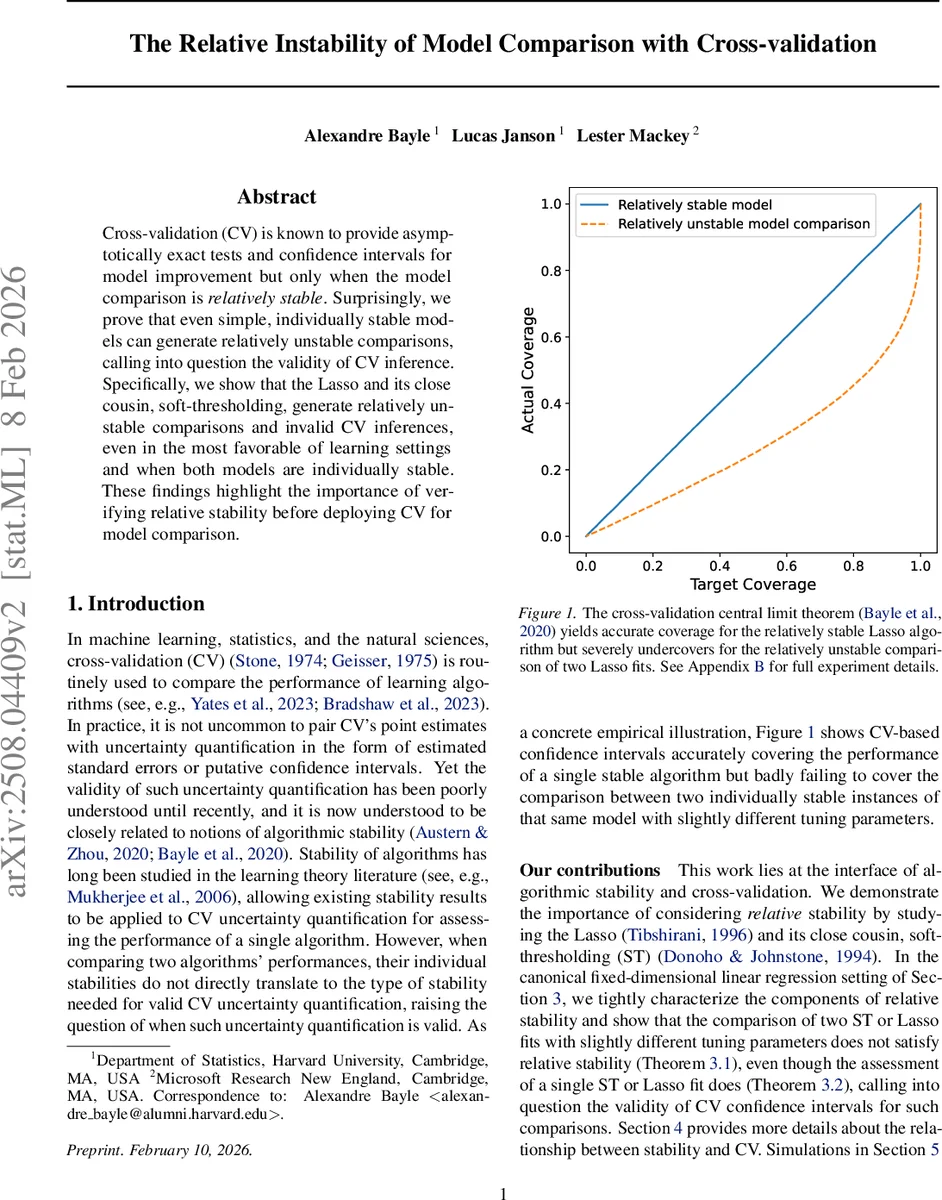
Cross-validation (CV) is known to provide asymptotically exact tests and confidence intervals for model improvement but only when the model comparison is relatively stable. Surprisingly, we prove that even simple, individually stable models can generate relatively unstable comparisons, calling into question the validity of CV inference. Specifically, we show that the Lasso and its close cousin, soft-thresholding, generate relatively unstable comparisons and invalid CV inferences, even in the most favorable of learning settings and when both models are individually stable. These findings highlight the importance of verifying relative stability before deploying CV for model comparison.
💡 Research Summary
The paper investigates a subtle but critical limitation of cross‑validation (CV) when it is used to compare the predictive performance of two learning algorithms. While recent work has shown that CV can provide asymptotically exact hypothesis tests and confidence intervals for a single algorithm under appropriate stability conditions, the authors demonstrate that these conditions do not automatically extend to the comparison of two algorithms. They introduce the notion of relative loss stability r(hₙ) = n·γ(hₙ)/σ²(hₙ), where γ(hₙ) measures the variability of the loss when a single training observation is replaced, and σ²(hₙ) is the variance of the loss itself. The key requirement for CV‑based inference to be valid is that r(hₙ) → 0 (i.e., r(hₙ)=o(1)).
The authors focus on the canonical fixed‑dimensional linear regression model Y = Xᵀβ* + ε with Gaussian covariates and noise. They study two closely related ℓ₁‑regularized estimators: Soft‑Thresholding (ST), defined as element‑wise thresholding of the ordinary least‑squares coefficients, and the Lasso. Lemma 2.3 shows that the Lasso and ST estimators are close in Euclidean norm when the design matrix is approximately orthogonal, which allows the authors to transfer results between the two methods.
Main theoretical contributions
- Theorem 3.1 (Relative instability of ST comparisons). For tuning parameters λₙ = O(√n) (growing but sub‑linear) and a fixed offset δₙ = Θ(1), the loss‑difference function h_diffₙ that compares ST(λₙ) and ST(λₙ + δₙ) satisfies
- n²δₙ² σ²(h_diffₙ) → 4τ²‖β*‖₀,
- γ(h_diffₙ) = Ω(1/(n²√n)).
Consequently, r(h_diffₙ) = Ω(√n) ≫ o(1), so the relative stability condition fails.
- Theorem 3.2 (Relative stability of a single ST estimator). For the same λₙ, the single‑algorithm loss h_singₙ has σ²(h_singₙ) → 2τ⁴ and γ(h_singₙ) ∼ C/n², yielding r(h_singₙ) = O(1/n) = o(1). Thus a single ST estimator is relatively stable.
These two results together show that even though each ST estimator individually satisfies the stability condition required for valid CV inference, the difference of two such estimators does not.
- Theorem 3.3 and 3.4 (Lasso analogues). By exploiting the proximity bound of Lemma 2.3, the authors prove that the same phenomenon holds for the Lasso: the comparison of Lasso(λₙ) and Lasso(λₙ + δₙ) is relatively unstable (r = Ω(√n)), while a single Lasso estimator is relatively stable (r = o(1)).
Connection to cross‑validation. Section 4 translates relative stability into the language of k‑fold CV. The CV estimator \hat Rₙ is an average of fold‑wise validation losses; its asymptotic normality and the consistency of its variance estimator rely precisely on the condition r(hₙ)=o(1). When this condition is violated, the CLT no longer holds, and confidence intervals derived from the usual CV variance estimate become severely miscalibrated.
Empirical validation. In Section 5 the authors conduct Monte‑Carlo simulations under the same Gaussian linear model. They generate data, select λₙ via an inner CV (which typically yields a value of order √n), and then evaluate three quantities: (i) the test error of a single ST/Lasso fit, (ii) the test error of a second fit with λₙ + δₙ, and (iii) the difference of the two test errors. Using 5‑fold CV to construct 95 % confidence intervals, they find that intervals for (i) and (ii) achieve the nominal coverage even for moderate sample sizes, whereas intervals for (iii) dramatically under‑cover, confirming the theoretical prediction of relative instability.
Implications and recommendations. The paper’s findings overturn the common intuition that if each algorithm is stable, then any comparison between them will inherit that stability. Instead, practitioners must explicitly verify the relative stability of the difference of losses before trusting CV‑based inference for model comparison. This is especially important when the two models differ only by a small hyper‑parameter change (e.g., tuning λ in Lasso), a scenario that occurs frequently in practice. The authors suggest that new diagnostic tools or alternative inference methods (e.g., bootstrap procedures tailored to the difference of estimators) are needed to address this gap.
In summary, the work provides a rigorous negative result: cross‑validation can yield invalid confidence intervals for model comparisons even in the simplest, well‑behaved regression settings, unless the relative loss stability condition is explicitly satisfied. This insight calls for a reassessment of standard CV practices in model selection and comparative studies.
Comments & Academic Discussion
Loading comments...
Leave a Comment