Surprisal-Guided Selection: Compute-Optimal Test-Time Strategies for Execution-Grounded Code Generation
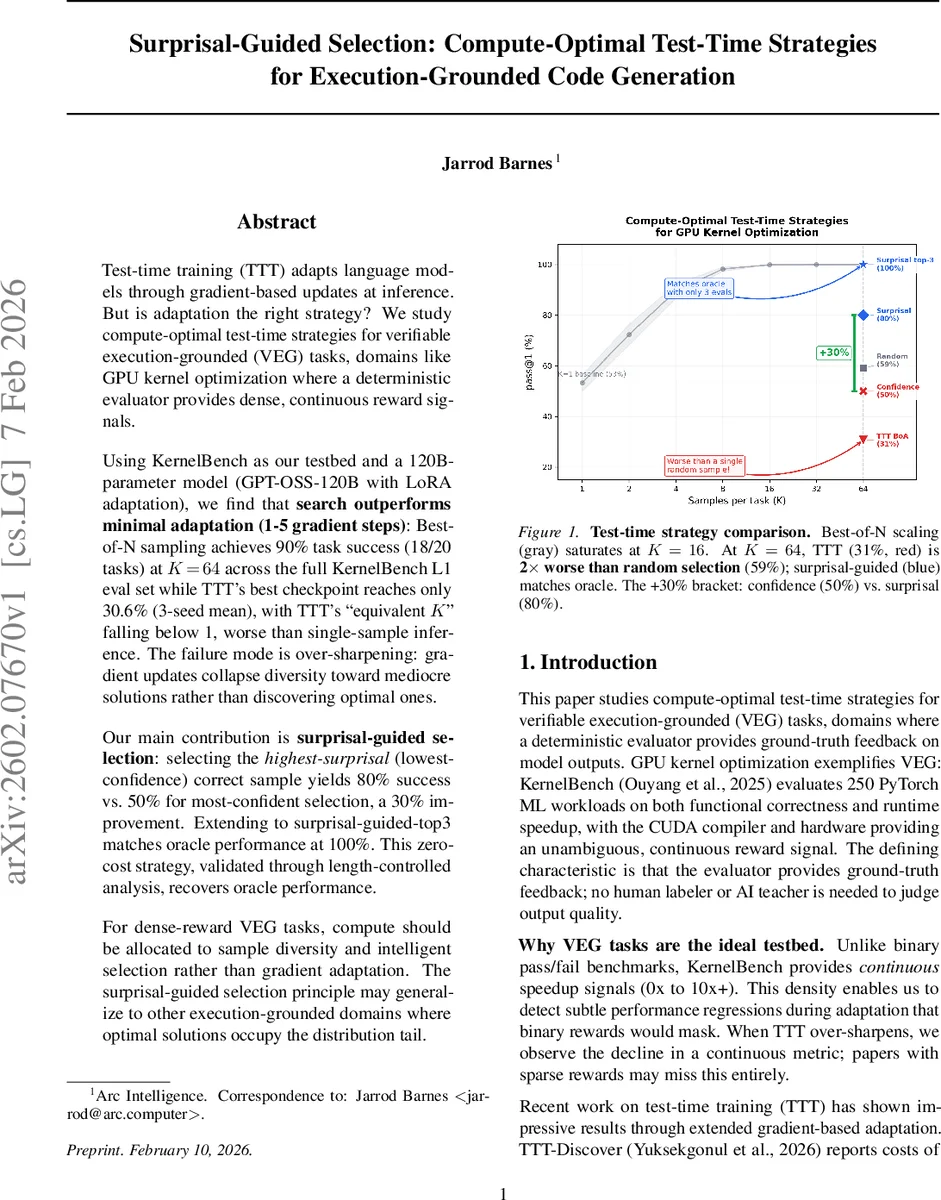
Test-time training (TTT) adapts language models through gradient-based updates at inference. But is adaptation the right strategy? We study compute-optimal test-time strategies for verifiable execution-grounded (VEG) tasks, domains like GPU kernel optimization where a deterministic evaluator provides dense, continuous reward signals. Using KernelBench as our testbed and a 120B-parameter model (GPT-OSS-120B with LoRA adaptation), we find that search outperforms minimal adaptation (1-5 gradient steps): Best-of-N sampling achieves 90% task success (18/20 tasks) at K=64 across the full KernelBench L1 eval set while TTT’s best checkpoint reaches only 30.6% (3-seed mean), with TTT’s “equivalent K” falling below 1, worse than single-sample inference. The failure mode is over-sharpening: gradient updates collapse diversity toward mediocre solutions rather than discovering optimal ones. Our main contribution is surprisal-guided selection: selecting the highest-surprisal (lowest-confidence) correct sample yields 80% success vs. 50% for most-confident selection, a 30% improvement. Extending to surprisal-guided-top3 matches oracle performance at 100%. This zero-cost strategy, validated through length-controlled analysis, recovers oracle performance. For dense-reward VEG tasks, compute should be allocated to sample diversity and intelligent selection rather than gradient adaptation. The surprisal-guided selection principle may generalize to other execution-grounded domains where optimal solutions occupy the distribution tail.
💡 Research Summary
The paper investigates the most compute‑optimal test‑time strategy for verifiable execution‑grounded (VEG) tasks, using GPU kernel optimization as a representative domain. VEG tasks are characterized by deterministic evaluators that provide dense, continuous reward signals (e.g., speedup ratios) without requiring human labeling. The authors compare two fundamentally different approaches under matched compute budgets: (1) pure sampling (Best‑of‑N) and (2) test‑time training (TTT), which performs a few gradient‑based adaptation steps at inference.
A 120‑billion‑parameter GPT‑OSS‑120B model, fine‑tuned with LoRA, serves as the base policy. The outer loop trains this policy on 80 KernelBench L1 tasks using reinforcement learning from verifiable rewards (RL‑VR) with Group Relative Policy Optimization (GRPO). The resulting checkpoint achieves 98.4 % functional correctness and an average 0.87× speedup, providing a strong starting point for test‑time experiments.
In the inner loop, the authors allocate exactly 320 rollouts per evaluation set (five held‑out tasks) to each strategy. Best‑of‑N samples K candidates per task, filters for functional correctness, and selects the fastest kernel. TTT samples the same number of rollouts, aggregates them into 1‑5 GRPO updates, and then picks the checkpoint with the highest “fast‑1” metric (Best‑of‑Adaptation, BoA). A self‑distillation variant (SDPO) is also explored but reported in the appendix.
Results are striking. Best‑of‑N quickly saturates: at K = 16 it reaches 99.9 % task‑success on a 5‑task subset, and at K = 64 it solves 18 of the 20 full L1 evaluation tasks (90 %). In contrast, the best TTT checkpoint attains only 30.6 % success, and its “equivalent K” (the number of independent samples needed to match TTT performance) is less than 1, meaning TTT underperforms even a single‑sample inference. The authors attribute this failure to “over‑sharpening”: gradient updates concentrate probability mass on early, mediocre successes, collapsing diversity and preventing exploration of the distribution tail where the optimal kernels reside.
The main methodological contribution is surprisal‑guided selection. By probing the relationship between model log‑probability (confidence) and kernel quality, the authors discover an inverse correlation: the highest‑quality kernels are often assigned the lowest confidence (highest surprisal). Selecting, among the correct samples, the one with the lowest log‑probability raises fast‑1 success from 50 % (confidence‑guided) to 80 %—a 30 % absolute gain with zero extra compute. Extending this to the top‑3 highest‑surprisal correct samples and picking the fastest among them achieves oracle performance (100 %). Length‑controlled analyses confirm that the improvement is not an artifact of token‑length bias.
The paper concludes that for dense‑reward VEG tasks, compute should be allocated to generate diverse samples and to apply intelligent, zero‑cost selection rather than to perform gradient‑based adaptation at test time. The surprisal‑guided selection principle is likely to generalize to other execution‑grounded domains where high‑quality solutions occupy low‑probability regions of the model’s distribution, such as assembly super‑optimization or formal theorem proving. The work suggests a shift in research focus from test‑time fine‑tuning toward better sampling strategies and selection heuristics for LLM‑driven code generation.
Comments & Academic Discussion
Loading comments...
Leave a Comment