MemPot: Defending Against Memory Extraction Attack with Optimized Honeypots
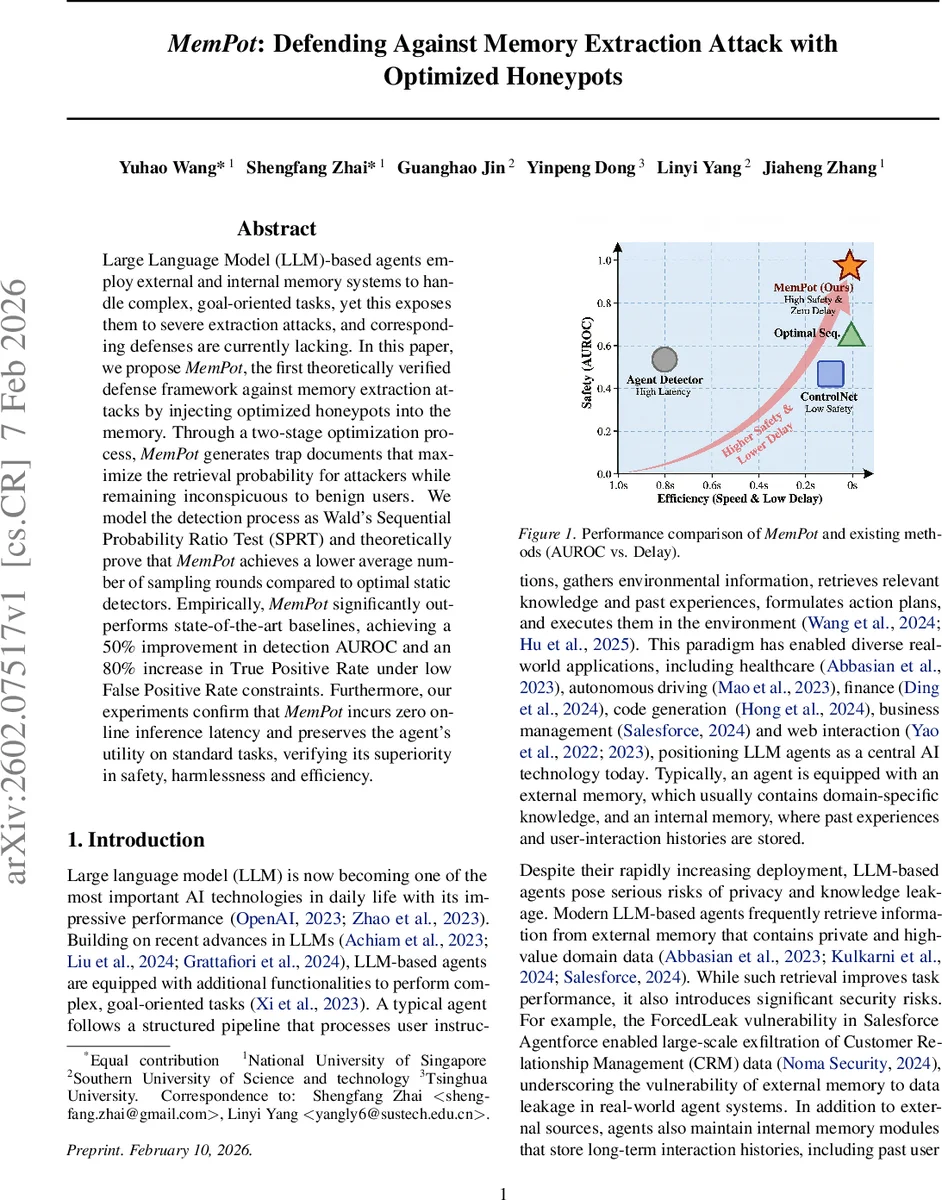
Large Language Model (LLM)-based agents employ external and internal memory systems to handle complex, goal-oriented tasks, yet this exposes them to severe extraction attacks, and effective defenses remain lacking. In this paper, we propose MemPot, the first theoretically verified defense framework against memory extraction attacks by injecting optimized honeypots into the memory. Through a two-stage optimization process, MemPot generates trap documents that maximize the retrieval probability for attackers while remaining inconspicuous to benign users. We model the detection process as Wald’s Sequential Probability Ratio Test (SPRT) and theoretically prove that MemPot achieves a lower average number of sampling rounds compared to optimal static detectors. Empirically, MemPot significantly outperforms state-of-the-art baselines, achieving a 50% improvement in detection AUROC and an 80% increase in True Positive Rate under low False Positive Rate constraints. Furthermore, our experiments confirm that MemPot incurs zero additional online inference latency and preserves the agent’s utility on standard tasks, verifying its superiority in safety, harmlessness, and efficiency.
💡 Research Summary
The paper tackles the pressing problem of memory extraction attacks on large‑language‑model (LLM) based agents, which rely on external knowledge bases and internal interaction histories. Existing defenses focus on per‑query detection using real‑time LLM inference or embedding‑based anomaly detectors, but they struggle with stealthy attacks that mimic benign queries and incur substantial latency.
MemPot introduces a fundamentally different approach: it injects “honeypot” documents directly into the agent’s memory and uses the retrieval process itself as a zero‑cost signal. By designing these honeypots to be highly attractive to attackers yet invisible to ordinary users, the system can accumulate evidence over multiple retrieval steps. Detection is formalized as a sequential hypothesis‑testing problem and solved with Wald’s Sequential Probability Ratio Test (SPRT), which minimizes the expected number of observation rounds (ASN) while respecting prescribed Type‑I/II error budgets (α, β).
The methodology consists of two optimization stages.
- Vector‑level honeypot design – The authors train embeddings for the honeypot set using a contrastive (InfoNCE) loss that maximizes statistical separability between attacker‑generated and benign query retrieval patterns. They prove (Theorem 1) that minimizing the InfoNCE loss raises the information drift µ₁ (the KL divergence between the two observation distributions) and thus reduces the ASN bound from Eq. (7). A diversity regularizer prevents the honeypots from collapsing onto each other, and a top‑k masked similarity score aligns the loss with realistic retrieval pipelines.
- Safety‑constrained text generation – Optimized embeddings are inverted back into natural‑language documents under safety constraints, ensuring that the resulting texts are harmless, semantically coherent, and do not mislead legitimate users.
Theoretical contributions include:
- Theorem 2, which shows that any SPRT equipped with the optimal honeypot parameters (θ*) achieves a strictly lower expected stopping time than any static, fixed‑length detector under the same (α, β) constraints.
- A formal connection between the contrastive loss and the SPRT’s information drift, establishing that the two‑stage pipeline is provably optimal for minimizing detection latency.
Empirical evaluation spans two datasets (a Retrieval‑Augmented Generation knowledge base and an internal dialogue archive) and two agent configurations (web‑interaction and conversational). MemPot is benchmarked against state‑of‑the‑art baselines such as ControlNet (distribution‑shift detection) and LLM‑based text‑level detectors. Results demonstrate:
- AUROC improvement of roughly 50 % over the best baseline.
- TPR increase of about 80 % at a strict FPR ≤ 1 %.
- Zero online inference overhead, because detection relies on the existing retrieval pipeline rather than extra model calls.
- Negligible impact on normal‑user utility, confirmed by unchanged task performance metrics and user satisfaction scores.
The paper’s contributions are threefold: (1) a novel defense framework that proactively reshapes the memory distribution with optimized honeypots; (2) a rigorous sequential‑testing formulation that yields provably faster detection than any static method; (3) a practical two‑stage training pipeline that preserves service quality while delivering superior security.
Limitations and future work are acknowledged. The safety of generated honeypot texts must be validated across diverse domains to avoid inadvertent leakage of sensitive information. Adaptive attackers could learn to recognize and avoid honeypots, suggesting a need for dynamic or adversarially‑trained honeypot updates. Finally, the embedding‑inversion step may sometimes produce low‑quality text, motivating research into more robust text synthesis under safety constraints.
Overall, MemPot represents a significant step forward in protecting LLM agents’ memory stores, offering a theoretically grounded, low‑cost, and highly effective shield against sophisticated extraction attacks.
Comments & Academic Discussion
Loading comments...
Leave a Comment