VGAS: Value-Guided Action-Chunk Selection for Few-Shot Vision-Language-Action Adaptation
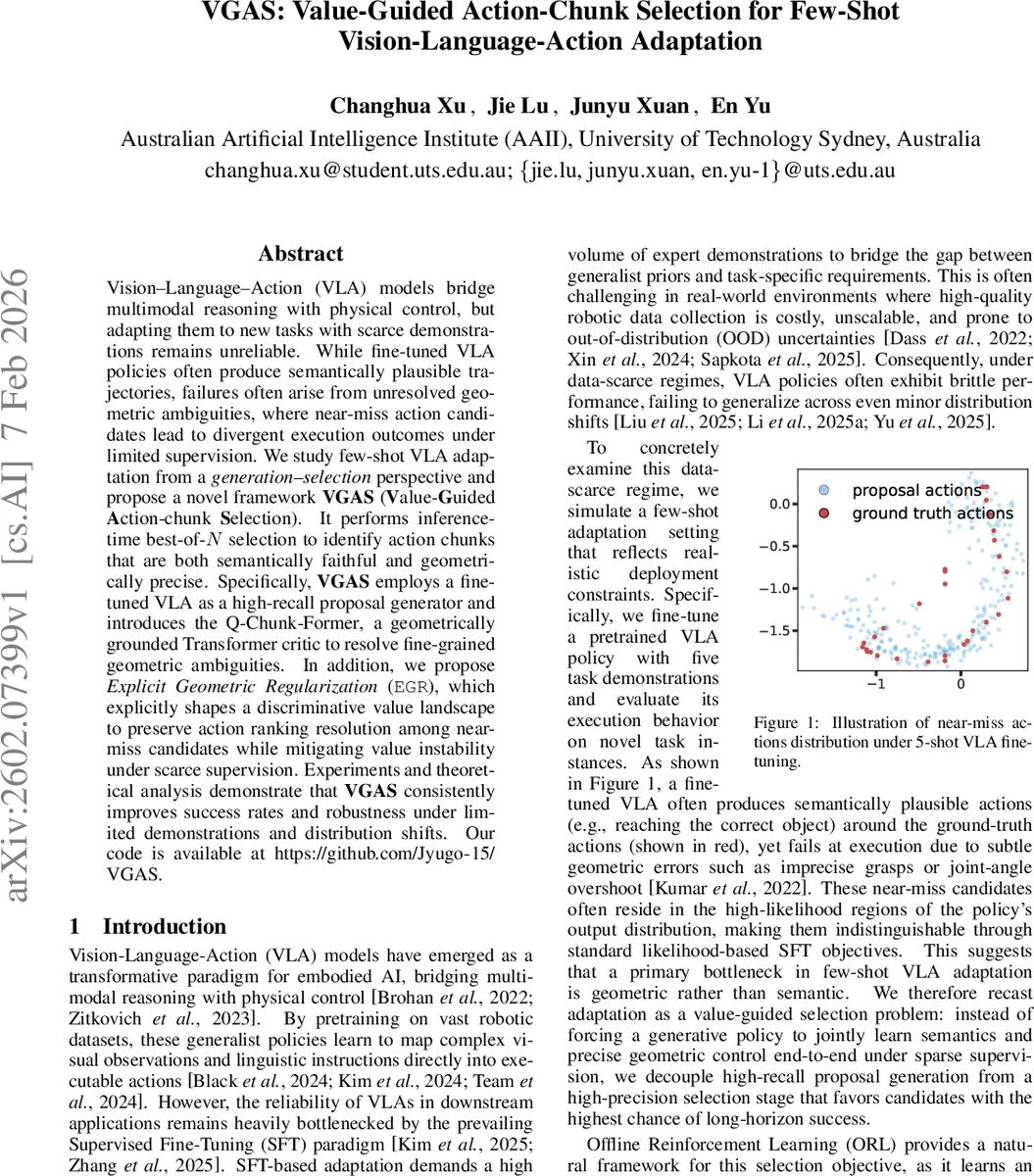
Vision–Language–Action (VLA) models bridge multimodal reasoning with physical control, but adapting them to new tasks with scarce demonstrations remains unreliable. While fine-tuned VLA policies often produce semantically plausible trajectories, failures often arise from unresolved geometric ambiguities, where near-miss action candidates lead to divergent execution outcomes under limited supervision. We study few-shot VLA adaptation from a \emph{generation–selection} perspective and propose a novel framework \textbf{VGAS} (\textbf{V}alue-\textbf{G}uided \textbf{A}ction-chunk \textbf{S}election). It performs inference-time best-of-$N$ selection to identify action chunks that are both semantically faithful and geometrically precise. Specifically, \textbf{VGAS} employs a finetuned VLA as a high-recall proposal generator and introduces the \textrm{Q-Chunk-Former}, a geometrically grounded Transformer critic to resolve fine-grained geometric ambiguities. In addition, we propose \textit{Explicit Geometric Regularization} (\texttt{EGR}), which explicitly shapes a discriminative value landscape to preserve action ranking resolution among near-miss candidates while mitigating value instability under scarce supervision. Experiments and theoretical analysis demonstrate that \textbf{VGAS} consistently improves success rates and robustness under limited demonstrations and distribution shifts. Our code is available at https://github.com/Jyugo-15/VGAS.
💡 Research Summary
Vision‑Language‑Action (VLA) models have emerged as a powerful paradigm for embodied AI, enabling agents to map high‑dimensional visual observations and natural‑language instructions directly to executable motor commands. However, adapting these models to new tasks when only a handful of expert demonstrations are available remains a major challenge. Standard supervised fine‑tuning (SFT) can learn the semantic intent of a task but often fails to resolve subtle geometric ambiguities such as precise grasp locations, joint‑angle limits, or collision‑free trajectories. These “near‑miss” actions lie in high‑probability regions of the policy’s output distribution, making them indistinguishable by likelihood‑based objectives alone.
The paper reframes few‑shot VLA adaptation as a generation‑selection problem. First, a fine‑tuned VLA serves as a high‑recall proposal generator, sampling a set of N temporally‑extended action chunks (each chunk contains h primitive actions) conditioned on the current multimodal state (visual tokens Iₜ, language tokens Lₜ, and proprioceptive vector pₜ). Second, a learned critic evaluates each (state, chunk) pair and selects the chunk with the highest estimated value. This best‑of‑N selection approximates a policy improvement step without any online interaction, thereby preserving safety while still exploiting the expressive power of the pretrained VLA.
The core technical contributions are twofold.
- Q‑Chunk‑Former – a Transformer‑based critic specifically designed for VLA inputs. A naïve concatenation of visual, linguistic, and proprioceptive tokens leads to attention domination by the high‑dimensional visual and language streams, causing the proprioceptive signal to be under‑utilized. To remedy this, the authors introduce a lightweight State‑Action Fusion (SAF) module that first fuses each action token with the robot’s proprioceptive state via learned linear projections and a fusion matrix. The resulting proprioception‑grounded action tokens (Aᵖₜ) are then fed together with frozen visual and language tokens into a Transformer decoder (the Q‑Former). A dedicated
Comments & Academic Discussion
Loading comments...
Leave a Comment