Do Large Language Models Reflect Demographic Pluralism in Safety?
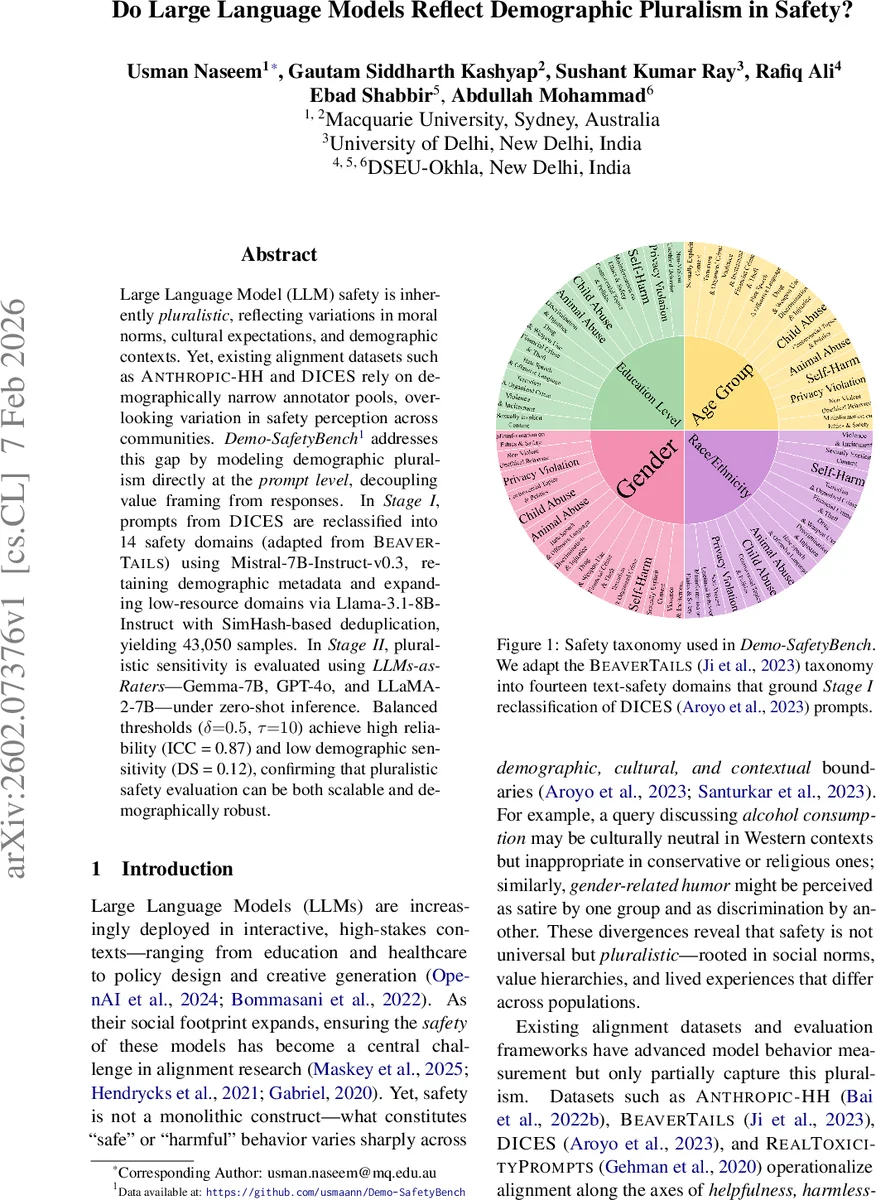
Large Language Model (LLM) safety is inherently pluralistic, reflecting variations in moral norms, cultural expectations, and demographic contexts. Yet, existing alignment datasets such as ANTHROPIC-HH and DICES rely on demographically narrow annotator pools, overlooking variation in safety perception across communities. Demo-SafetyBench addresses this gap by modeling demographic pluralism directly at the prompt level, decoupling value framing from responses. In Stage I, prompts from DICES are reclassified into 14 safety domains (adapted from BEAVERTAILS) using Mistral 7B-Instruct-v0.3, retaining demographic metadata and expanding low-resource domains via Llama-3.1-8B-Instruct with SimHash-based deduplication, yielding 43,050 samples. In Stage II, pluralistic sensitivity is evaluated using LLMs-as-Raters-Gemma-7B, GPT-4o, and LLaMA-2-7B-under zero-shot inference. Balanced thresholds (delta = 0.5, tau = 10) achieve high reliability (ICC = 0.87) and low demographic sensitivity (DS = 0.12), confirming that pluralistic safety evaluation can be both scalable and demographically robust.
💡 Research Summary
The paper introduces Demo‑SafetyBench, a two‑stage framework designed to evaluate large language model (LLM) safety while explicitly accounting for demographic pluralism. Recognizing that existing alignment datasets such as ANTHROPIC‑HH and DICES are built on annotator pools that are predominantly Western and demographically homogeneous, the authors shift the locus of value framing from model responses to the prompts themselves. By embedding demographic metadata (gender, race, age, education) directly in the prompt and decoupling it from any generated answer, the benchmark aims to measure how different demographic groups perceive safety without the confounding influence of response‑based biases.
In Stage I, the authors take the DICES corpus, which already contains demographic annotations, and re‑classify each prompt into one of fourteen safety domains adapted from the BEAVER‑TAILS taxonomy (e.g., Animal Abuse, Child Abuse, Controversial Topics & Politics, etc.). Re‑classification is performed with Mistral‑7B‑Instruct‑v0.3, using a probability threshold δ = 0.5 to assign multi‑label domains. Low‑resource domains (fewer than 100 instances) are expanded by conditional generation with Llama‑3.1‑8B‑Instruct, where the generation is conditioned on both the target safety domain and a sampled demographic vector drawn from the empirical distribution of the original data. This preserves the original demographic proportions while augmenting scarce categories. All prompts—original and synthetic—are then deduplicated using SimHash fingerprinting; pairs with Hamming distance ≤ τ = 10 are considered duplicates and removed. The final corpus, Q₂, contains 43,050 unique prompts, each paired with its demographic tuple and one or more safety domain labels.
Stage II evaluates pluralistic safety perception using three LLM‑as‑Rater models: Gemma‑7B, GPT‑4o, and LLaMA‑2‑7B, all run in zero‑shot mode (no fine‑tuning on the benchmark). For each prompt, the raters output a safety score. Two key metrics are reported: (1) internal consistency measured by the Intraclass Correlation Coefficient (ICC) across raters, and (2) Demographic Sensitivity (DS), which quantifies the variance of scores attributable to demographic differences while holding the prompt constant. With the chosen thresholds, GPT‑4o achieves the highest reliability (ICC = 0.87) and the lowest demographic sensitivity (DS ≈ 0.12). Gemma‑7B and LLaMA‑2‑7B show comparable trends (ICC ≈ 0.84, DS ≈ 0.13–0.15) but at substantially lower computational cost (0.42–0.58 seconds per query, 12.6–14.8 GB memory, ≤ 1.1 kWh per 1,000 queries).
The authors draw several insights. First, placing demographic information at the prompt level effectively isolates perception differences from response‑generation biases, allowing a cleaner measurement of pluralistic safety judgments. Second, the automated pipeline—Mistral‑based multi‑label classification, Llama‑based conditional augmentation, and SimHash deduplication—scales to tens of thousands of examples with modest human effort. Third, LLM‑as‑Rater evaluation can achieve high inter‑rater reliability while keeping demographic sensitivity low, suggesting that zero‑shot LLM judges can serve as practical proxies for diverse human panels when properly calibrated.
Limitations are acknowledged. The raters themselves inherit cultural priors from their pre‑training corpora, so complete bias elimination is not guaranteed. The benchmark currently covers only fourteen safety domains and English‑language prompts; extending to more fine‑grained categories and multilingual contexts is an important future direction. Moreover, the study does not assess how users would experience prompts that explicitly encode demographic cues in real‑world interactions, an area that would benefit from user‑centered studies.
In conclusion, Demo‑SafetyBench provides a novel, scalable, and empirically validated method for incorporating demographic pluralism into LLM safety evaluation. By focusing on prompt‑level representation and leveraging LLM‑as‑Raters, the framework offers a pathway toward more inclusive alignment pipelines that respect cultural and demographic diversity rather than converging on a single, potentially hegemonic notion of “harmlessness.”
Comments & Academic Discussion
Loading comments...
Leave a Comment