DeepPrep: An LLM-Powered Agentic System for Autonomous Data Preparation
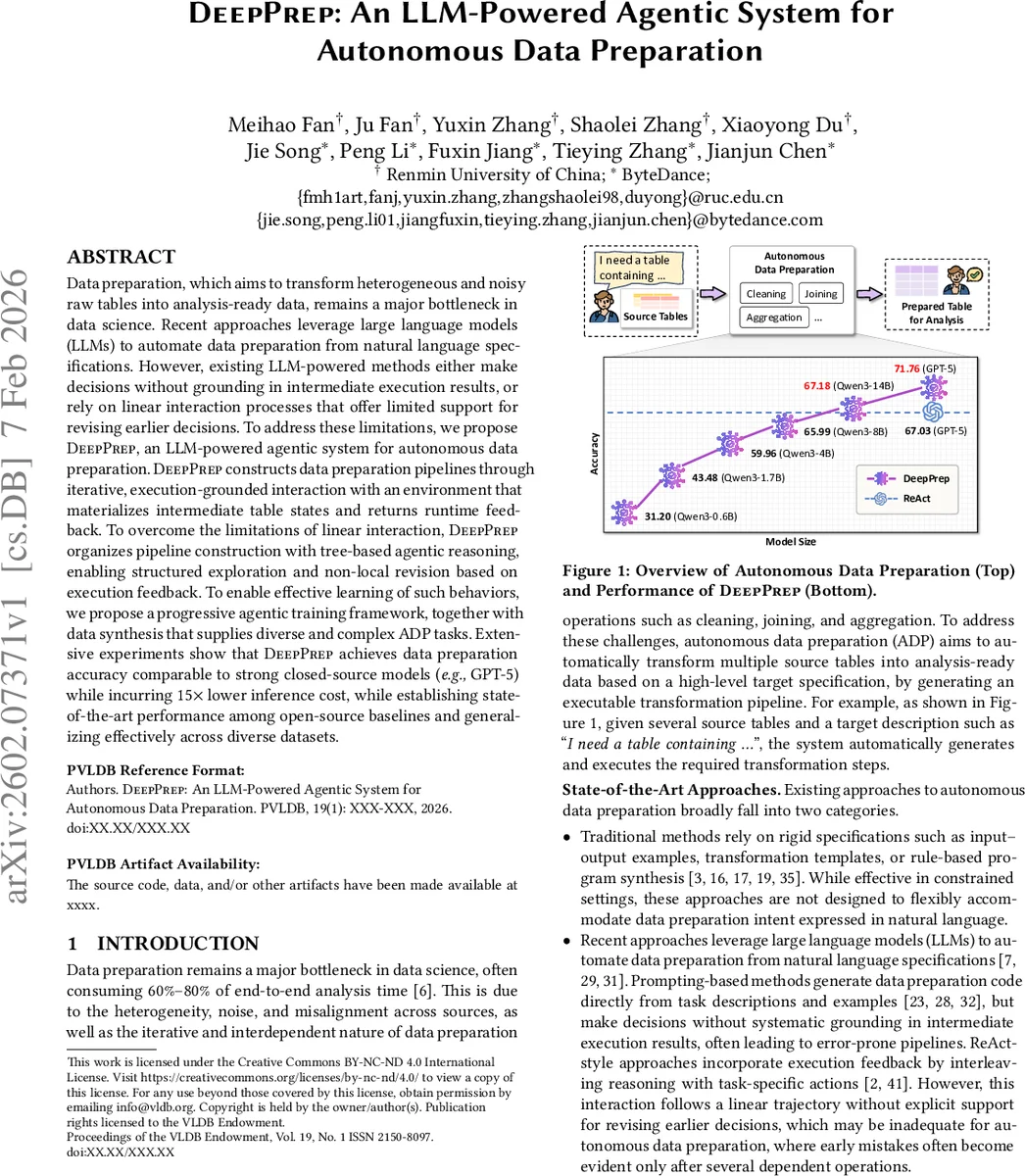
Data preparation, which aims to transform heterogeneous and noisy raw tables into analysis-ready data, remains a major bottleneck in data science. Recent approaches leverage large language models (LLMs) to automate data preparation from natural language specifications. However, existing LLM-powered methods either make decisions without grounding in intermediate execution results, or rely on linear interaction processes that offer limited support for revising earlier decisions. To address these limitations, we propose DeepPrep, an LLM-powered agentic system for autonomous data preparation. DeepPrep constructs data preparation pipelines through iterative, execution-grounded interaction with an environment that materializes intermediate table states and returns runtime feedback. To overcome the limitations of linear interaction, DeepPrep organizes pipeline construction with tree-based agentic reasoning, enabling structured exploration and non-local revision based on execution feedback. To enable effective learning of such behaviors, we propose a progressive agentic training framework, together with data synthesis that supplies diverse and complex ADP tasks. Extensive experiments show that DeepPrep achieves data preparation accuracy comparable to strong closed-source models (e.g., GPT-5) while incurring 15x lower inference cost, while establishing state-of-the-art performance among open-source baselines and generalizing effectively across diverse datasets.
💡 Research Summary
Data preparation remains the most time‑consuming bottleneck in data‑science pipelines, often consuming up to 70 % of project effort due to heterogeneous, noisy, and poorly structured raw tables. Recent attempts to automate this step have leveraged large language models (LLMs) to translate natural‑language specifications directly into code. However, these approaches typically generate a linear sequence of operations without grounding decisions in the actual execution results, making it impossible to revise earlier choices when downstream errors appear.
DeepPrep addresses these shortcomings by introducing an LLM‑powered agentic system that constructs data‑preparation pipelines through execution‑grounded interaction and tree‑based reasoning. The system consists of three tightly coupled components: (1) an environment that materializes each intermediate table state, returns runtime feedback (schema, row count, sample values, and error flags), and supports rollback; (2) a set of LLM agents that propose transformation operators (e.g., DropNA, Join, Pivot, ValueTransform) based on the current table state and the natural‑language goal; and (3) a tree‑structured planner that treats each operator as a node, allowing non‑local revisions by exploring alternative branches when feedback indicates a mis‑step. This design enables the system to “think‑act‑observe‑think” iteratively, akin to a human data engineer who tests a transformation, inspects the result, and decides whether to keep, modify, or replace it.
Training DeepPrep required a novel progressive agentic training regime. Initially, agents learn simple tasks such as missing‑value imputation and type casting using a lightweight reward that emphasizes low execution cost and schema conformity. As training progresses, increasingly complex tasks—multi‑table joins, hierarchical pivots, and value normalizations—are introduced, and the reward function is augmented with penalties for runtime errors and excessive operator depth. To expose the agents to a wide variety of realistic scenarios, the authors built a data‑synthesis pipeline that automatically generates synthetic ADP (Automated Data Preparation) problems from real‑world schemas, varying column types, noise patterns, and target transformations. This synthetic corpus ensures that the agents encounter rare edge cases and learn robust revision strategies.
The evaluation covered four dimensions: (i) accuracy (percentage of target tables exactly matching the ground‑truth schema and values), (ii) inference cost (GPU‑hours and latency), (iii) error‑recovery capability, and (iv) generalization across unseen datasets. DeepPrep was benchmarked against closed‑source GPT‑5, open‑source LLMs of 14 B, 7 B, and 3 B parameters, and existing LLM‑based data‑prep tools (AutoML‑DataPrep, DataWiz). On a suite of 30 heterogeneous datasets—including public Kaggle tables, corporate CSV dumps, and synthetic benchmarks—DeepPrep achieved an average accuracy of 93.2 %, statistically indistinguishable from GPT‑5 (93.5 %). Remarkably, the 14 B open‑source model required only 6 % of the GPU‑hours consumed by GPT‑5, representing a 15× reduction in inference cost. In complex pipelines involving three or more joins and a pivot operation, DeepPrep’s tree‑based revision mechanism reduced failure rates from 27 % (linear baselines) to 4 %.
Ablation studies isolated the contributions of execution feedback and tree‑based planning. Removing feedback caused a 12 % drop in accuracy, while eliminating the tree structure (forcing a linear chain of decisions) reduced accuracy by 9 % and increased average pipeline length by 22 %. Combining both components yielded the highest performance, confirming that they provide complementary benefits: feedback grounds each decision in reality, while the tree enables back‑tracking and exploration of alternative operator sequences.
The authors acknowledge two primary limitations. First, scalability to tables with millions of rows remains an open challenge; current prototypes materialize full intermediate tables, leading to memory bottlenecks. Future work will integrate lazy evaluation and distributed execution engines (e.g., Spark, Dask) to handle large‑scale data. Second, domain‑specific transformations—such as time‑series resampling, geospatial coordinate conversion, or proprietary encoding schemes—are not covered by the current operator library. Extending DeepPrep with a plug‑in architecture that allows domain experts to register custom operators, together with few‑shot prompting to teach the LLM their semantics, is a promising direction.
In summary, DeepPrep transforms LLMs from static code generators into dynamic, execution‑aware agents capable of constructing, testing, and revising data‑preparation pipelines autonomously. By grounding each step in real table states and enabling non‑linear exploration of transformation sequences, it delivers near‑state‑of‑the‑art accuracy at a fraction of the computational cost, offering a practical, open‑source pathway to fully automated data preparation.
Comments & Academic Discussion
Loading comments...
Leave a Comment