OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
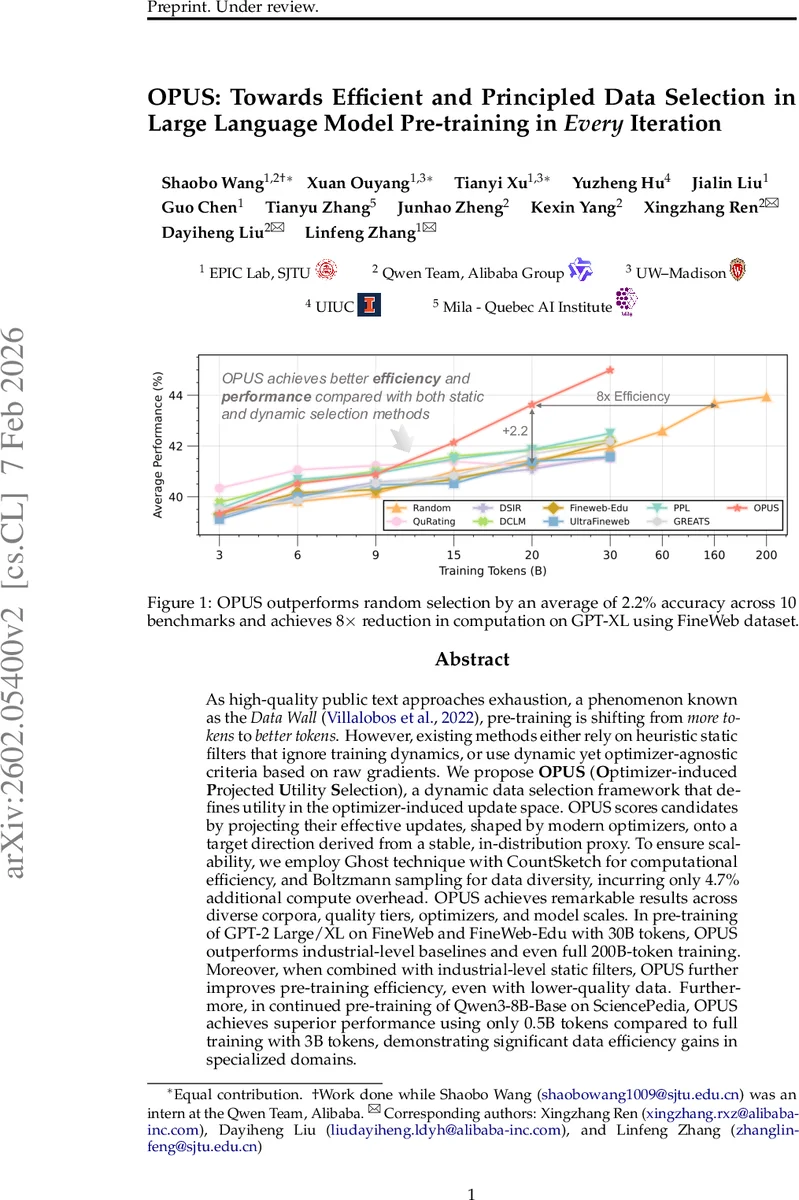
As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.
💡 Research Summary
The paper tackles the emerging “data wall” problem in large‑scale language model (LLM) pre‑training, where high‑quality public text is becoming scarce and the focus shifts from sheer token volume to token quality. Existing data‑selection approaches fall into two categories. Static filters (e.g., FineWeb, DCLM) prune the corpus once before training and ignore the evolving state of the model and optimizer. Dynamic selectors score samples using raw gradients or loss, implicitly assuming stochastic gradient descent (SGD) dynamics, which misaligns with modern adaptive optimizers such as AdamW and Muon that apply momentum and per‑parameter preconditioning.
OPUS (Optimizer‑induced Projected Utility Selection) introduces a principled, optimizer‑aware utility function. The key idea is to evaluate each candidate’s contribution in the optimizer‑induced update space rather than raw‑gradient space. Concretely, at training step t the effective update for a sample z is Δθₜ(z) = –ηₜ Pₜ ∇L(z;θₜ), where Pₜ denotes the optimizer’s preconditioner (e.g., AdamW’s first‑ and second‑moment estimates, Muon’s double‑smoothed direction). A stable, in‑distribution proxy pool is constructed (BENCH‑PROXY) by retrieving benchmark‑aligned documents from the raw corpus; the proxy’s loss gradient ∇L(𝔻_proxy;θₜ) defines a target descent direction. The utility of z is the inner product between its optimizer‑induced update and the proxy gradient, i.e., uₜ(z) = ⟨Δθₜ(z), ∇L(𝔻_proxy;θₜ)⟩ / ‖∇L(𝔻_proxy;θₜ)‖. A higher value indicates that training on z moves the model more directly toward reducing loss on high‑quality data.
Scoring every candidate with full per‑sample gradients would be prohibitive at web‑scale. OPUS solves this with two engineering tricks. First, the Ghost technique reuses intermediate activations to compute a lightweight approximation of per‑layer gradients without a full backward pass. Second, CountSketch projects high‑dimensional gradient vectors into a low‑dimensional hash space, allowing inner products to be computed in O(1) time and memory. This combination yields a scalable estimator that can operate on billions of tokens in real time.
To avoid the diversity collapse typical of greedy top‑k selection, OPUS employs Boltzmann sampling with a temperature τ and an in‑step redundancy penalty β. The sampling probability for a candidate becomes p(z) ∝ exp(uₜ(z)/τ)·exp(–β·Redundancy(z)), ensuring that high‑utility but overly similar samples are not over‑represented.
The authors evaluate OPUS across three major settings. (1) From‑scratch pre‑training of GPT‑2 Large and GPT‑2 XL on the FineWeb and FineWeb‑Edu corpora (30 B tokens). OPUS outperforms industrial static filters and prior dynamic selectors by an average of 2.2 % accuracy on ten downstream benchmarks, and matches or exceeds the performance of a full 200 B‑token training run while using only 30 B tokens. (2) When combined with static filters, OPUS further improves data efficiency even on lower‑quality corpora, demonstrating complementary benefits. (3) Continued pre‑training of Qwen3‑8B‑Base on a domain‑specific SciencePedia dataset: with just 0.5 B tokens, OPUS achieves comparable or superior results to training on the full 3 B tokens. Across all experiments the additional compute overhead is only 4.7 %, and an 8× reduction in total FLOPs is reported.
Ablation studies confirm that (a) using the optimizer‑induced preconditioner rather than raw gradients yields the bulk of the gain, (b) CountSketch dimensionality of 256 balances accuracy and speed, and (c) Boltzmann sampling mitigates redundancy without sacrificing utility. The method is robust across optimizers (AdamW, Muon), model sizes (hundreds of millions to tens of billions of parameters), and data quality tiers.
The paper’s contributions are threefold: (i) a theoretically grounded utility defined in the actual optimizer geometry, (ii) a scalable estimation pipeline (Ghost + CountSketch) that makes per‑sample utility feasible at LLM scale, and (iii) a diversity‑preserving sampling scheme. Limitations include the need to construct and periodically refresh the proxy pool, sensitivity to temperature and redundancy hyper‑parameters, and the current focus on language modeling pre‑training (extensions to instruction tuning or RL‑HF remain open).
In summary, OPUS demonstrates that aligning data selection with the optimizer’s true update direction can dramatically improve token efficiency in the data‑wall regime. By projecting optimizer‑induced updates onto a high‑quality proxy direction and estimating these projections efficiently, OPUS offers a practical, optimizer‑aware alternative to both static filtering and raw‑gradient dynamic selection, paving the way for more data‑efficient LLM training as public text resources become increasingly limited.
Comments & Academic Discussion
Loading comments...
Leave a Comment