Training-Free Inference for High-Resolution Sinogram Completion
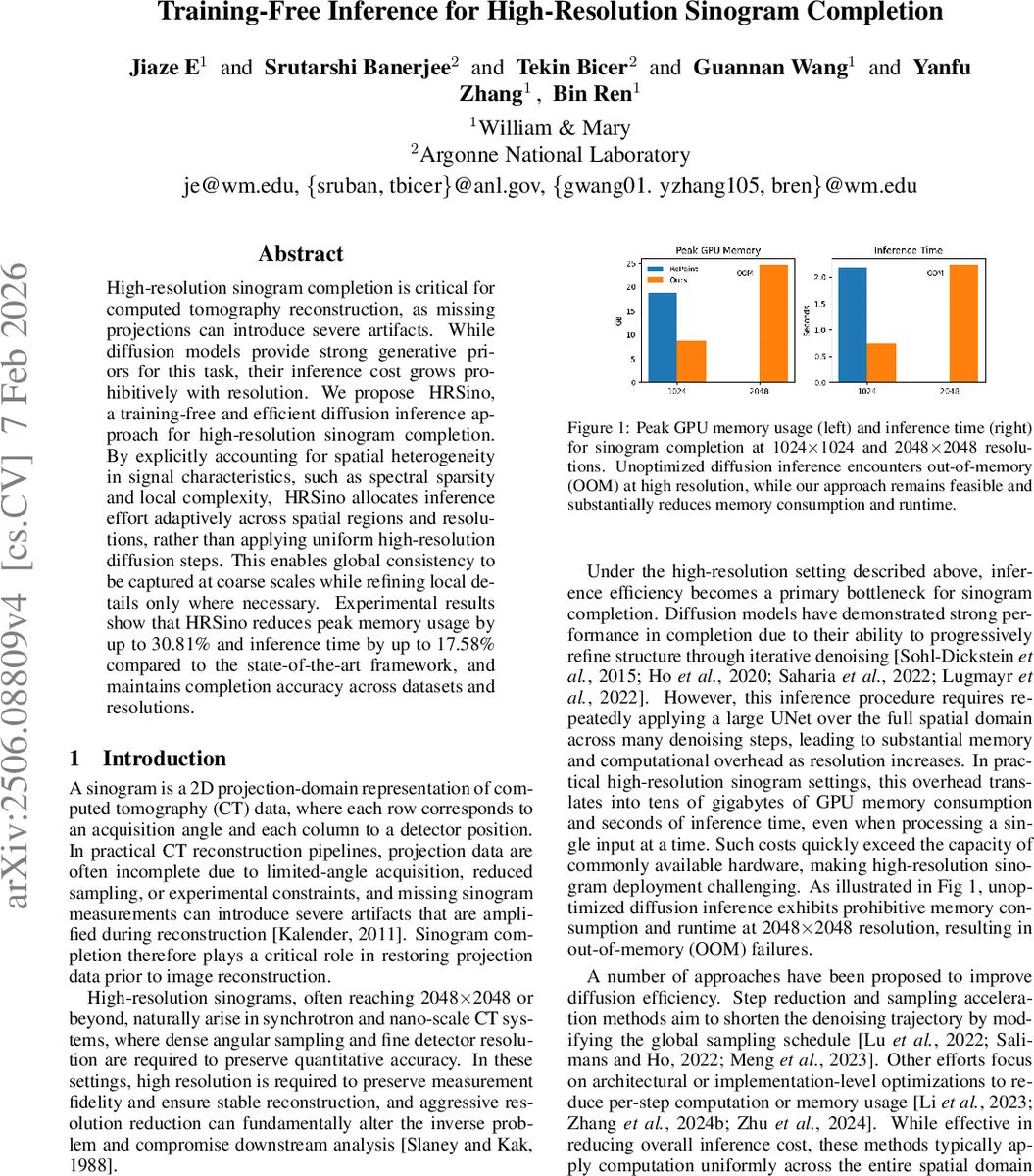
High-resolution sinogram completion is critical for computed tomography reconstruction, as missing projections can introduce severe artifacts. While diffusion models provide strong generative priors for this task, their inference cost grows prohibitively with resolution. We propose HRSino, a training-free and efficient diffusion inference approach for high-resolution sinogram completion. By explicitly accounting for spatial heterogeneity in signal characteristics, such as spectral sparsity and local complexity, HRSino allocates inference effort adaptively across spatial regions and resolutions, rather than applying uniform high-resolution diffusion steps. This enables global consistency to be captured at coarse scales while refining local details only where necessary. Experimental results show that HRSino reduces peak memory usage by up to 30.81% and inference time by up to 17.58% compared to the state-of-the-art framework, and maintains completion accuracy across datasets and resolutions.
💡 Research Summary
The paper addresses the prohibitive memory and runtime costs of diffusion‑based sinogram completion at high resolutions (e.g., 2048 × 2048). While diffusion models such as RePaint provide strong generative priors, their inference requires repeatedly applying a large UNet over the full image for many denoising steps, leading to tens of gigabytes of GPU memory consumption and long inference times. To overcome this, the authors propose HRSino, a training‑free inference framework that reorganizes diffusion computation along both spatial and temporal dimensions without any model retraining or architectural changes.
HRSino operates in three resolution‑guided stages. First, the original sinogram is down‑sampled to 0.25 × and fully denoised using DDIM, capturing global structure at minimal cost. Second, a 0.5 × version is fused with the up‑sampled low‑resolution result (simple averaging) and denoised again, refining mid‑scale geometry while preserving the global context. Finally, the full‑resolution sinogram is split into fixed‑size patches. For each patch, HRSino applies two novel inference‑time mechanisms:
-
Frequency‑aware patch skipping – each patch is transformed with a 2‑D FFT, and the ratio of high‑frequency energy γ(P) is computed. An adjusted score γ′(P) incorporates the mask ratio to avoid skipping heavily masked regions. Patches whose γ′ falls below a threshold are considered spectrally sparse; instead of running full DDIM steps, they are replaced by a synthetic patch filled with low‑amplitude Gaussian noise, effectively bypassing redundant computation.
-
Structure‑adaptive denoising – a complexity score κ(P) combines Shannon entropy of the intensity histogram and high‑frequency energy (L1 norm of the FFT). κ(P) determines how many DDIM steps are allocated to the patch: high‑complexity patches receive more steps, low‑complexity patches fewer. This dynamic depth allocation aligns computational effort with local content richness.
To avoid visual seams at patch boundaries, a cosine‑based blending is applied only when the Sobel‑derived gradient across the overlap exceeds a preset threshold; otherwise a hard stitch is used to save computation.
Experiments on datasets from William & Mary and Argonne National Laboratory demonstrate that HRSino can complete 2048 × 2048 sinograms on a single NVIDIA A100 GPU while reducing peak memory usage by up to 30.81 % and inference time by up to 17.58 % compared with the current state‑of‑the‑art diffusion framework. Quantitative metrics (PSNR, SSIM) show negligible degradation, and visual inspection confirms smooth transitions across patches. The method is evaluated across multiple mask types, ratios, and resolutions, confirming its robustness.
Key contributions are: (i) a purely inference‑time redesign of diffusion sampling that requires no retraining, (ii) a progressive, resolution‑guided pipeline that dramatically cuts memory footprints, (iii) two complementary mechanisms—frequency‑aware patch skipping and structure‑adaptive step allocation—that exploit the inherent spectral sparsity and local heterogeneity of sinograms, and (iv) extensive validation showing practical applicability to high‑resolution CT pipelines. The approach is orthogonal to existing diffusion acceleration techniques (e.g., step reduction, model pruning) and can be combined with them for further gains. Moreover, the concepts of spectral‑based computation pruning and content‑driven denoising depth are likely transferable to other high‑resolution image generation and restoration tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment