Towards Stabilized and Efficient Diffusion Transformers through Long-Skip-Connections with Spectral Constraints
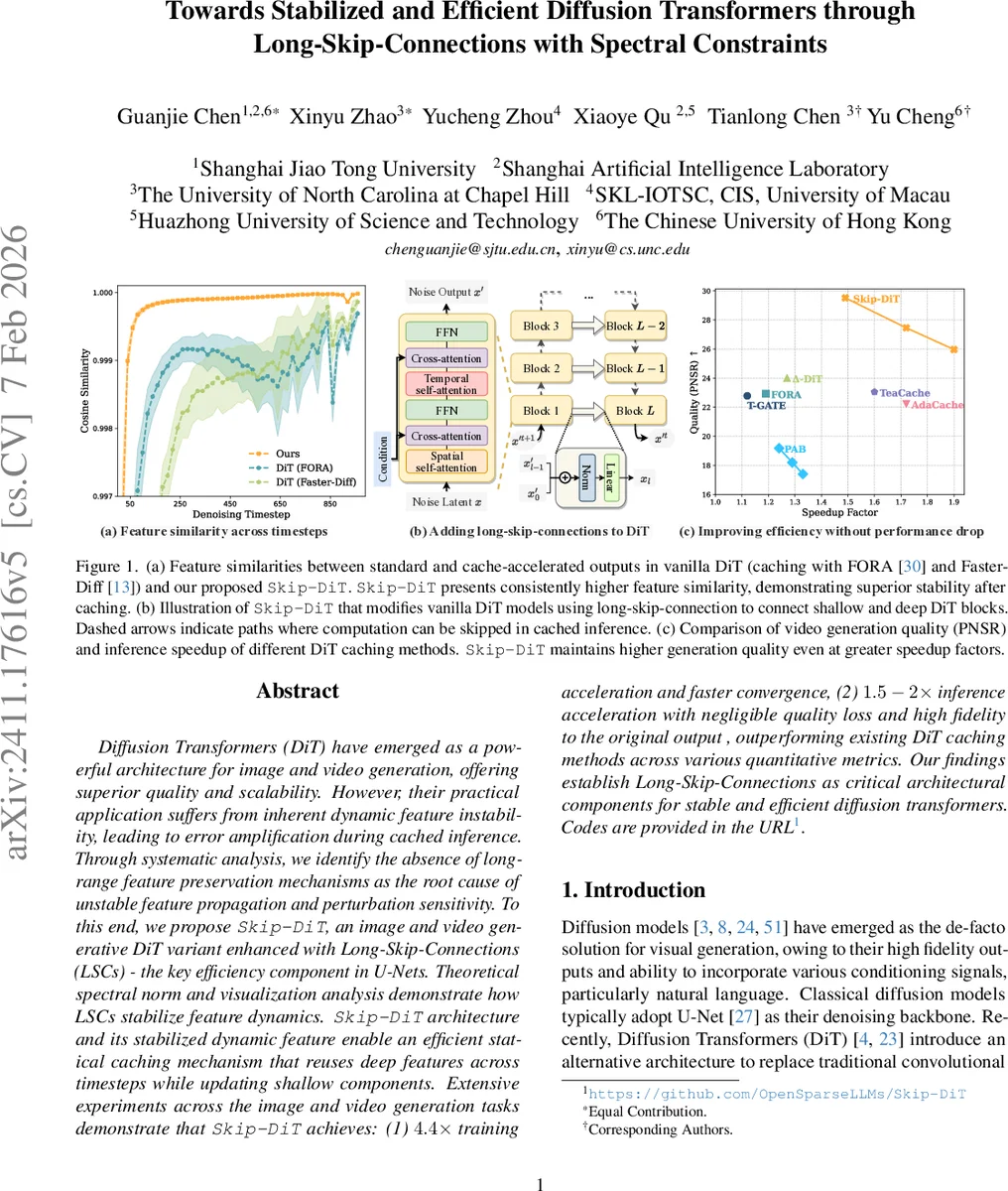
Diffusion Transformers (DiT) have emerged as a powerful architecture for image and video generation, offering superior quality and scalability. However, their practical application suffers from inherent dynamic feature instability, leading to error amplification during cached inference. Through systematic analysis, we identify the absence of long-range feature preservation mechanisms as the root cause of unstable feature propagation and perturbation sensitivity. To this end, we propose Skip-DiT, an image and video generative DiT variant enhanced with Long-Skip-Connections (LSCs) - the key efficiency component in U-Nets. Theoretical spectral norm and visualization analysis demonstrate how LSCs stabilize feature dynamics. Skip-DiT architecture and its stabilized dynamic feature enable an efficient statical caching mechanism that reuses deep features across timesteps while updating shallow components. Extensive experiments across the image and video generation tasks demonstrate that Skip-DiT achieves: (1) 4.4 times training acceleration and faster convergence, (2) 1.5-2 times inference acceleration with negligible quality loss and high fidelity to the original output, outperforming existing DiT caching methods across various quantitative metrics. Our findings establish Long-Skip-Connections as critical architectural components for stable and efficient diffusion transformers. Codes are provided in the https://github.com/OpenSparseLLMs/Skip-DiT.
💡 Research Summary
Diffusion Transformers (DiT) have become a leading architecture for high‑fidelity image and video synthesis, yet they suffer from two critical drawbacks: dynamic feature instability during training and inference, and consequently slow convergence and high computational cost. Existing acceleration techniques—such as reduced sampling, distillation, quantization, and various caching schemes (e.g., FORA, Faster‑Diff, Δ‑DiT, AdaCache)—either require per‑sample hyper‑parameter tuning, introduce noticeable artifacts when the caching interval is enlarged, or fail to address the underlying instability of the transformer blocks themselves.
The authors first identify the root cause of these problems as “Dynamic Feature Instability” (DFI). By injecting controlled perturbations into model parameters (θ′ = θ + αδ + βη) and inputs, they demonstrate that vanilla DiT exhibits large variance in cosine similarity across timesteps, indicating that small disturbances are exponentially amplified through the network. This behavior is linked to uncontrolled spectral norms (σ_max) of the Jacobians of each transformer block, a phenomenon previously observed in GAN training and in networks lacking spectral normalization.
To mitigate DFI, the paper introduces Skip‑DiT, a DiT variant that incorporates Long‑Skip‑Connections (LSCs) between shallow and deep transformer blocks, a design element traditionally used in U‑Net backbones for stable training and efficient feature reuse. Each LSC concatenates the output of an early block with the input of a later block, followed by layer normalization and a linear projection. This creates shortcut pathways that preserve early‑stage information, improve gradient flow, and, crucially, bound the overall spectral norm of the model.
Theoretical analysis shows that if each transformer block reduces noise magnitude (γ < 1) and shares the same reduction ratio, the spectral norm of the entire network without skips grows as γⁿ, where n is the number of blocks. With LSCs, the effective norm becomes γ·(1 + γ), dramatically lower, which prevents exponential amplification of perturbations. The authors formalize this in Theorem 1, proving that LSCs enforce a spectral constraint that stabilizes both forward feature propagation and backward gradient flow.
Beyond stability, LSCs enable a novel “statistical caching” strategy. During inference, the deep‑block outputs are cached at selected timesteps; only the shallow blocks need to be recomputed, while the cached deep features are directly added via the skips. This contrasts with prior DiT caching methods that must recompute all blocks or rely on adaptive per‑sample predictions. Empirical results show that Skip‑DiT maintains cosine similarity above 0.98 even when the caching interval is significantly increased, and video PSNR improves by up to 0.2 dB compared to baseline caches.
Training efficiency is also markedly improved. On ImageNet‑50K, Skip‑DiT reaches an FID of 8.37 after only 1.6 M training steps, whereas the vanilla DiT‑XL requires roughly 7 M steps to achieve comparable performance. Across three DiT backbones (DiT‑S, DiT‑B, DiT‑XL) and six image generation models, the method consistently yields 3–4.4× faster convergence. Inference speedups of 1.5–2× are reported on seven visual generation tasks (both class‑conditional and text‑conditional), with negligible quality loss.
In summary, the paper makes three major contributions: (1) a systematic diagnosis of Dynamic Feature Instability as the fundamental barrier to efficient DiT training and caching; (2) the design of Skip‑DiT, which integrates Long‑Skip‑Connections and spectral norm constraints to guarantee feature stability; and (3) extensive experimental validation showing substantial training and inference acceleration while preserving or even enhancing generation quality. The codebase is publicly released at https://github.com/OpenSparseLLMs/Skip-DiT, enabling the community to adopt stable and efficient diffusion transformers for a wide range of generative tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment