DSL: Understanding and Improving Softmax Recommender Systems with Competition-Aware Scaling
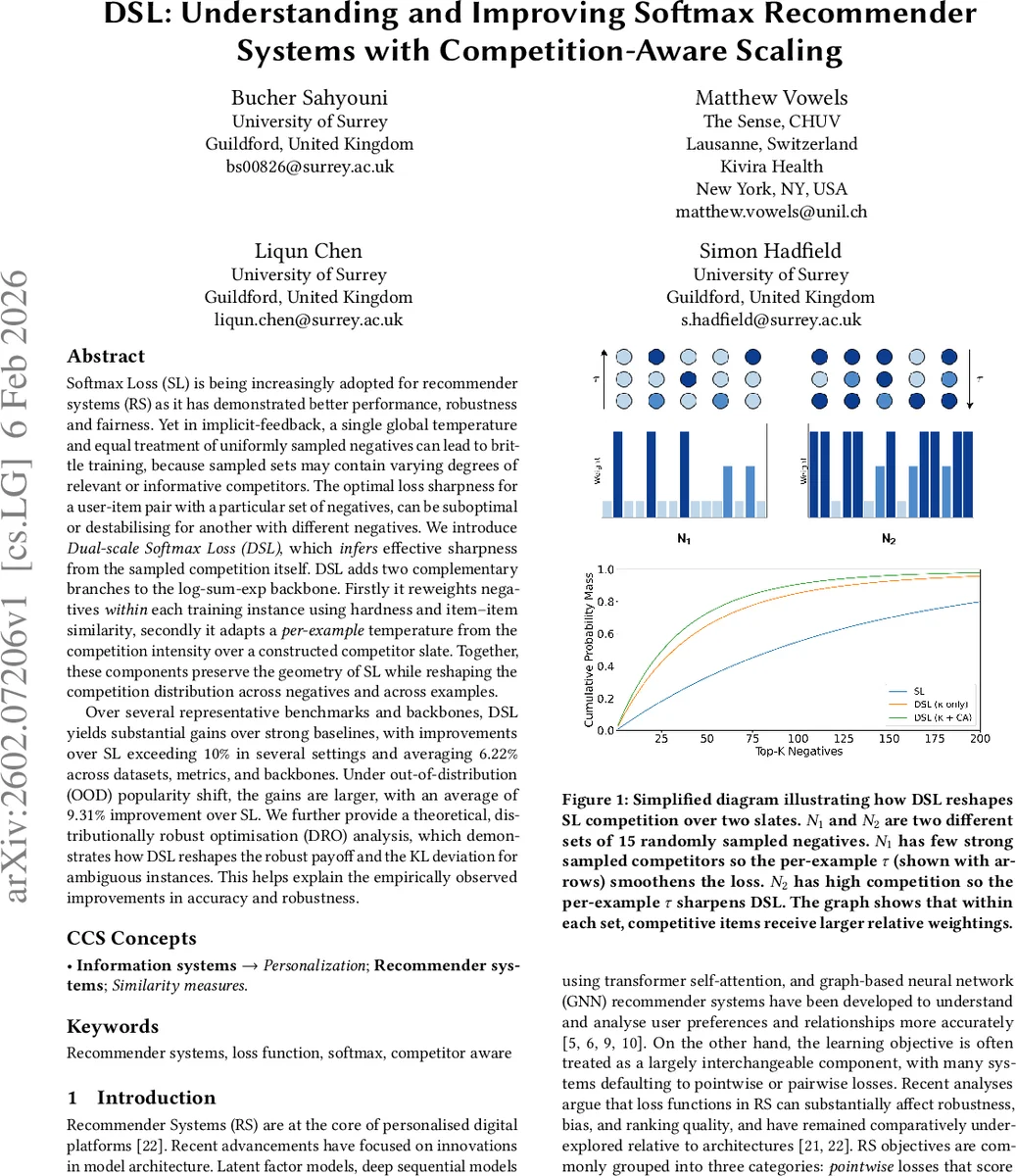
Softmax Loss (SL) is being increasingly adopted for recommender systems (RS) as it has demonstrated better performance, robustness and fairness. Yet in implicit-feedback, a single global temperature and equal treatment of uniformly sampled negatives can lead to brittle training, because sampled sets may contain varying degrees of relevant or informative competitors. The optimal loss sharpness for a user-item pair with a particular set of negatives, can be suboptimal or destabilising for another with different negatives. We introduce Dual-scale Softmax Loss (DSL), which infers effective sharpness from the sampled competition itself. DSL adds two complementary branches to the log-sum-exp backbone. Firstly it reweights negatives within each training instance using hardness and item–item similarity, secondly it adapts a per-example temperature from the competition intensity over a constructed competitor slate. Together, these components preserve the geometry of SL while reshaping the competition distribution across negatives and across examples. Over several representative benchmarks and backbones, DSL yields substantial gains over strong baselines, with improvements over SL exceeding $10%$ in several settings and averaging $6.22%$ across datasets, metrics, and backbones. Under out-of-distribution (OOD) popularity shift, the gains are larger, with an average of $9.31%$ improvement over SL. We further provide a theoretical, distributionally robust optimisation (DRO) analysis, which demonstrates how DSL reshapes the robust payoff and the KL deviation for ambiguous instances. This helps explain the empirically observed improvements in accuracy and robustness.
💡 Research Summary
The paper addresses a critical limitation of the widely used Softmax Loss (SL) in implicit‑feedback recommender systems: the reliance on a single global temperature and the uniform treatment of all sampled negative items. In practice, each user‑item pair is accompanied by a set of sampled negatives that varies widely in relevance and competitiveness. A fixed temperature may be too sharp for instances with few strong competitors, causing instability, or too smooth for instances with many hard competitors, diluting useful gradient signals.
To overcome this, the authors propose Dual‑scale Softmax Loss (DSL), which dynamically infers an effective sharpness from the competition present in each training example. DSL augments the standard log‑sum‑exp backbone with two lightweight branches.
- Within‑example reweighting (κ‑branch). For each negative j, the model’s current score f(u, j) serves as a hardness proxy, while the cosine similarity between the positive item i and negative j (shifted to
Comments & Academic Discussion
Loading comments...
Leave a Comment