Filtered Approximate Nearest Neighbor Search Cost Estimation
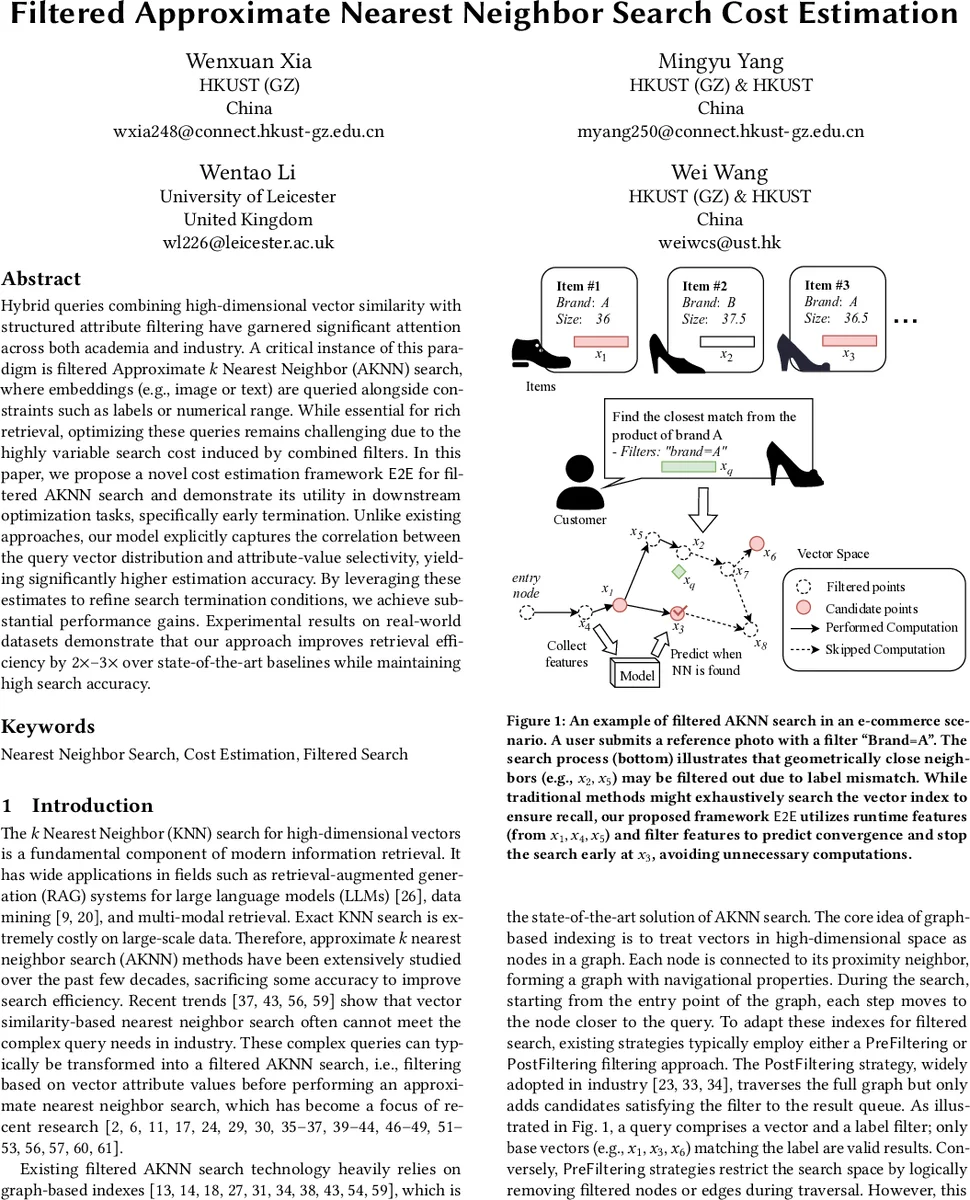
Hybrid queries combining high-dimensional vector similarity with structured attribute filtering have garnered significant attention across both academia and industry. A critical instance of this paradigm is filtered Approximate k Nearest Neighbor (AKNN) search, where embeddings (e.g., image or text) are queried alongside constraints such as labels or numerical range. While essential for rich retrieval, optimizing these queries remains challenging due to the highly variable search cost induced by combined filters. In this paper, we propose a novel cost estimation framework, E2E, for filtered AKNN search and demonstrate its utility in downstream optimization tasks, specifically early termination. Unlike existing approaches, our model explicitly captures the correlation between the query vector distribution and attribute-value selectivity, yielding significantly higher estimation accuracy. By leveraging these estimates to refine search termination conditions, we achieve substantial performance gains. Experimental results on real-world datasets demonstrate that our approach improves retrieval efficiency by 2x-3x over state-of-the-art baselines while maintaining high search accuracy.
💡 Research Summary
The paper addresses the problem of estimating and reducing the computational cost of filtered approximate k‑nearest neighbor (AKNN) search, where a high‑dimensional query vector is combined with attribute‑based filters (e.g., labels or numeric ranges). Existing graph‑based indexes such as HNSW provide efficient vector search, but when filters are applied the cost becomes highly variable: pre‑filtering can disconnect the graph and cause insufficient results, while post‑filtering forces the algorithm to compute distances for many vectors that later fail the filter. Moreover, prior cost‑estimation methods (e.g., LAET, DARTH) rely solely on distance‑based runtime signals and ignore the correlation between the query vector distribution and filter selectivity, leading to inaccurate budget allocation especially for “hard” queries where vector similarity and filter constraints are misaligned.
To solve this, the authors propose E2E (Early probe‑to‑early termination), a two‑stage framework that actively gathers filter‑aware runtime features during an initial “Early Probing” phase. This phase consists of a few normal graph traversals; the distances computed are later reused, so no extra overhead is introduced. From these traversals the system extracts:
- Local Valid Ratio – the proportion of visited nodes that satisfy the filter,
- Filter‑Vector Density – a measure of how densely filter‑compatible points are distributed around the query,
- Distance Gradient – the rate at which distances decrease during expansion.
These dynamic signals are combined with static statistics (global selectivity, average node degree, etc.) and fed into a calibrated regression model that predicts the total number of expansions (or the efsearch parameter) required to achieve a target recall. The predicted budget is then applied immediately within the main search loop, allowing the algorithm to terminate as soon as convergence is expected, thereby avoiding unnecessary distance calculations.
Key contributions include:
- Formal definition of the Feature‑Filter Misalignment problem and introduction of Local Correlation (ρ_local) to capture query‑filter interaction.
- Design of a zero‑overhead early probing mechanism that yields high‑quality, filter‑aware features.
- Integration of the cost predictor into an Adaptive Termination algorithm that dynamically sets per‑query search budgets.
- Extensive experiments on large‑scale real‑world e‑commerce datasets (image and text embeddings with label and price range filters) and public multimodal benchmarks. Compared with state‑of‑the‑art adaptive methods (LAET, DARTH), E2E achieves 2×–3× lower latency while preserving recall ≥ 0.9, with up to 4× improvement on the hardest queries. Prediction error for search budget is reduced by more than 30 % relative to baselines.
The approach requires no changes to the underlying graph index structure, incurs no extra storage, and the early probing steps are fully compatible with existing traversal pipelines. The authors release code and trained models, ensuring reproducibility. Overall, E2E demonstrates that explicitly modeling the interplay between vector similarity and attribute filters enables accurate cost estimation and effective early termination, substantially improving the efficiency of filtered AKNN search in production‑grade retrieval systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment