CauCLIP: Bridging the Sim-to-Real Gap in Surgical Video Understanding via Causality-Inspired Vision-Language Modeling
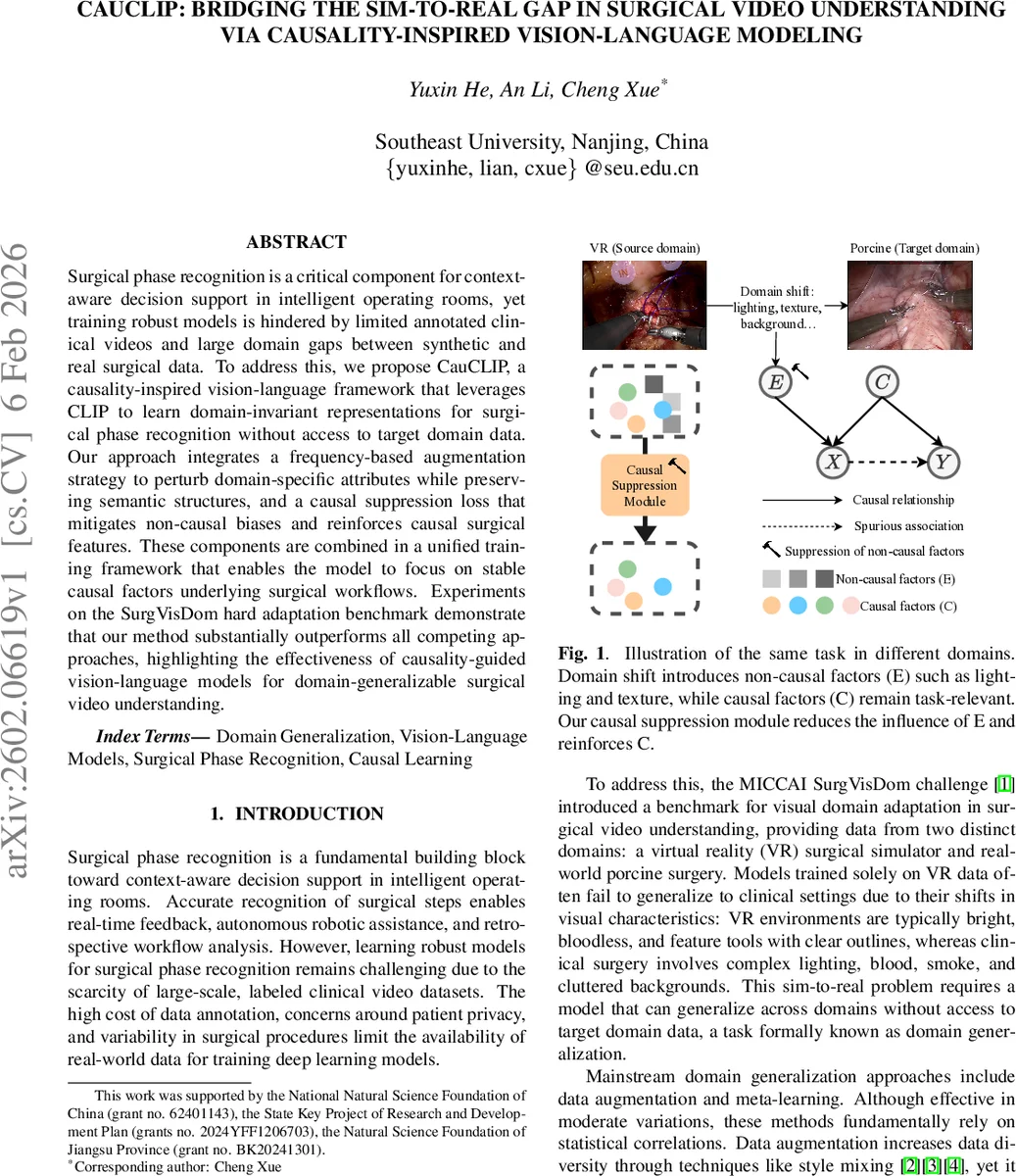
Surgical phase recognition is a critical component for context-aware decision support in intelligent operating rooms, yet training robust models is hindered by limited annotated clinical videos and large domain gaps between synthetic and real surgical data. To address this, we propose CauCLIP, a causality-inspired vision-language framework that leverages CLIP to learn domain-invariant representations for surgical phase recognition without access to target domain data. Our approach integrates a frequency-based augmentation strategy to perturb domain-specific attributes while preserving semantic structures, and a causal suppression loss that mitigates non-causal biases and reinforces causal surgical features. These components are combined in a unified training framework that enables the model to focus on stable causal factors underlying surgical workflows. Experiments on the SurgVisDom hard adaptation benchmark demonstrate that our method substantially outperforms all competing approaches, highlighting the effectiveness of causality-guided vision-language models for domain-generalizable surgical video understanding.
💡 Research Summary
CauCLIP tackles the challenging problem of surgical phase recognition under severe domain shift, where only synthetic (virtual‑reality) videos are available for training but the model must operate on real‑world porcine surgery footage. The authors build upon the CLIP vision‑language paradigm, specifically adapting the ActionCLIP framework, to treat phase recognition as a video‑text matching task. A ViT‑B/16 video encoder extracts spatio‑temporal features from each clip, while a text encoder maps predefined phase prompts into embeddings. Similarities between video and text embeddings are turned into probability distributions via a softmax with a learnable temperature, and the standard CLIP loss (average KL divergence) aligns the two modalities.
Recognizing that conventional domain‑generalization techniques (data augmentation, meta‑learning) rely on superficial statistical correlations, the authors introduce a causality‑inspired perspective: domain‑specific visual attributes (lighting, texture, background clutter) are treated as non‑causal factors (E), whereas the true surgical semantics (tool‑tissue interactions, motion patterns) are causal factors (C). To suppress E and amplify C, two complementary mechanisms are proposed.
First, a frequency‑domain augmentation perturbs only the amplitude component of the Fourier transform while preserving phase. Given an image x₀, its Fourier representation A(x₀)·e^{-jP(x₀)} is mixed with the amplitude of a second image x′₀ (sampled from a different background) using a mixing coefficient β drawn from U(0,α). The phase is left untouched, and the inverse FFT reconstructs an augmented view x_a. Because amplitude encodes style (color, texture) and phase encodes high‑level structure, this operation injects style variability without destroying semantic content. Empirically, α=0.5 yields the best trade‑off.
Second, a causal suppression loss enforces invariance between original and augmented views while decorrelating different samples. For a batch of N clips, the original embeddings z_o and augmented embeddings z_a are concatenated, and an N×N cosine similarity matrix C is computed. The loss L_sup = ‖C – I‖_F² (Frobenius norm) pushes diagonal entries (matching original‑augmented pairs) toward 1 and off‑diagonal entries toward 0, encouraging the encoder to produce view‑invariant, causally relevant features.
An additional alignment loss L_aug, identical to the original CLIP loss but applied to the augmented videos, further ensures that the textual prompts remain aligned with the perturbed visual inputs. The total training objective combines these terms: L_total = L_orig + λ_aug·L_aug + λ_sup·L_sup, with λ_aug=0.8 and λ_sup=0.4 selected via validation.
Experiments use the SurgVisDom hard adaptation benchmark from the MICCAI 2020 EndoVis challenge. Training utilizes only 450 VR clips (three tasks: dissection, knot‑tying, needle‑driving). Testing involves 16 long clinical‑like porcine videos containing mixed tasks. Evaluation metrics include weighted F1, unweighted F1, global F1, and balanced accuracy, which together assess performance under class imbalance and overall correctness.
CauCLIP outperforms all baselines, including the prior state‑of‑the‑art SD‑A‑CLIP (weighted F1 0.632, balanced accuracy 0.468). CauCLIP achieves weighted F1 0.642, unweighted F1 0.487, global F1 0.708, and balanced accuracy 0.651. An ablation study shows that the vanilla CLIP loss alone yields balanced accuracy 0.480; adding only L_sup raises it to 0.544, adding only L_aug to 0.533, and combining both reaches the full 0.651. This demonstrates that frequency‑domain style perturbation improves robustness to visual shifts, while the suppression loss forces the model to rely on causal surgical cues rather than spurious domain artifacts.
In summary, the paper makes three key contributions: (1) a vision‑language framework that explicitly separates causal from non‑causal visual factors for surgical phase recognition; (2) a novel frequency‑domain augmentation that manipulates style without harming semantics; and (3) a causal suppression loss that enforces invariance across augmented views while decorrelating unrelated samples. The combined approach yields state‑of‑the‑art domain‑generalizable performance without any target‑domain data. The work opens avenues for extending causality‑guided vision‑language models to other medical imaging tasks, potentially integrating richer causal graphs, multimodal sensor data, or more complex surgical workflows.
Comments & Academic Discussion
Loading comments...
Leave a Comment