Sample-Efficient Policy Space Response Oracles with Joint Experience Best Response
Multi-agent reinforcement learning (MARL) offers a scalable alternative to exact game-theoretic analysis but suffers from non-stationarity and the need to maintain diverse populations of strategies that capture non-transitive interactions. Policy Space Response Oracles (PSRO) address these issues by iteratively expanding a restricted game with approximate best responses (BRs), yet per-agent BR training makes it prohibitively expensive in many-agent or simulator-expensive settings. We introduce Joint Experience Best Response (JBR), a drop-in modification to PSRO that collects trajectories once under the current meta-strategy profile and reuses this joint dataset to compute BRs for all agents simultaneously. This amortizes environment interaction and improves the sample efficiency of best-response computation. Because JBR converts BR computation into an offline RL problem, we propose three remedies for distribution-shift bias: (i) Conservative JBR with safe policy improvement, (ii) Exploration-Augmented JBR that perturbs data collection and admits theoretical guarantees, and (iii) Hybrid BR that interleaves JBR with periodic independent BR updates. Across benchmark multi-agent environments, Exploration-Augmented JBR achieves the best accuracy-efficiency trade-off, while Hybrid BR attains near-PSRO performance at a fraction of the sample cost. Overall, JBR makes PSRO substantially more practical for large-scale strategic learning while preserving equilibrium robustness.
💡 Research Summary
The paper tackles a fundamental scalability bottleneck in Policy Space Response Oracles (PSRO), a popular framework for approximating equilibria in multi‑agent reinforcement learning (MARL). Standard PSRO iteratively expands a restricted game by computing a best‑response (BR) for each agent against the current meta‑strategy. This requires a separate reinforcement‑learning (RL) training process for every agent at every iteration, leading to a sample cost that grows linearly with the number of agents and can become prohibitive when the environment simulator is expensive.
To address this, the authors introduce Joint Experience Best Response (JBR), a “drop‑in” modification that reuses a single set of trajectories collected under the joint meta‑strategy profile. Instead of running n independent simulations, the environment is stepped once while all agents act according to their mixed strategies; the resulting joint dataset Dσ is then used to train BR policies for all agents offline. Consequently, the number of environment interactions per PSRO iteration collapses from O(n) to O(1), dramatically improving sample efficiency.
However, converting BR computation into an offline RL problem introduces distribution‑shift bias because Dσ reflects only the current meta‑strategy distribution. The authors propose three complementary remedies:
-
Conservative JBR – incorporates Safe Policy Improvement (SPI) guarantees, ensuring that any new BR policy does not perform worse than the existing meta‑strategy. This is achieved by estimating a lower bound on the offline value function and only accepting updates that improve this bound.
-
Exploration‑Augmented JBR – deliberately perturbs data collection to increase coverage. Two variants are studied: δR (perturbations applied at the data level) and δT (perturbations applied to the policy before rollout). The authors provide theoretical bounds showing that, under appropriate perturbation magnitudes, the offline learning bias remains controlled while exploration improves the quality of the learned BR.
-
Hybrid BR – interleaves JBR with periodic independent online BR updates (e.g., every k iterations). This hybrid scheme combines the sample‑saving benefits of JBR with the accuracy of fresh online learning, mitigating residual bias without a large increase in sample cost.
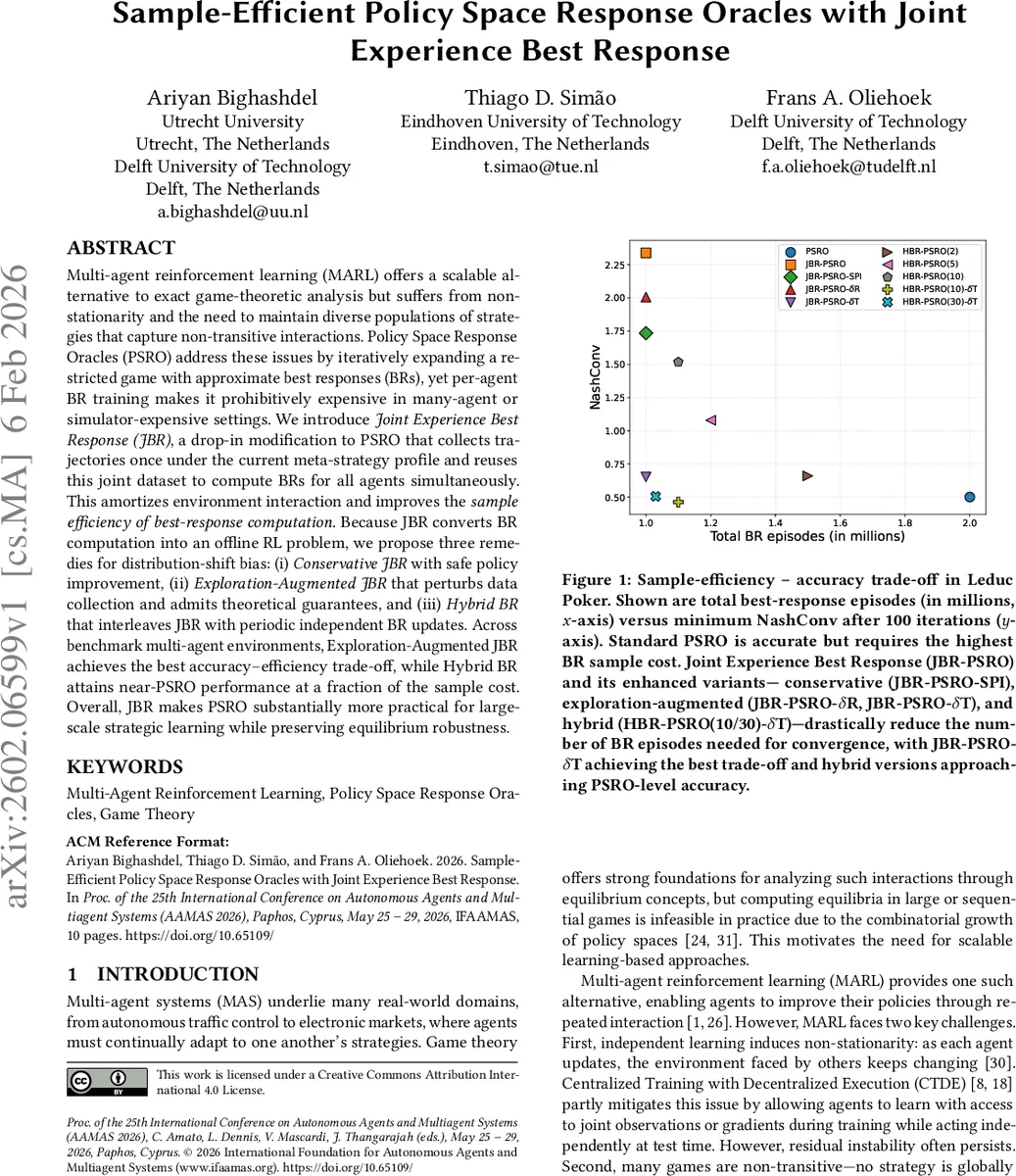
Empirical evaluation is performed on both discrete (Leduc Poker) and continuous (cooperative robot control, electronic market) benchmark environments. Performance is measured using NashConv (aggregate regret) and total BR episodes (sample budget). Results show that Exploration‑Augmented JBR (especially the δT variant) achieves near‑optimal NashConv while reducing total BR episodes by roughly 70 % compared to vanilla PSRO. Hybrid BR variants (k = 10, 30) attain PSRO‑level convergence with only a marginal additional sample overhead. Conservative JBR guarantees safety but converges more slowly due to its restrictive update rule.
Overall, the contributions are threefold: (1) a novel JBR framework that reuses joint experience to compute all agents’ BRs simultaneously, (2) a systematic treatment of offline‑RL bias with three practical remedies, and (3) a thorough empirical study demonstrating that PSRO can be made substantially more practical for large‑scale strategic learning without sacrificing equilibrium robustness. The work opens avenues for extending JBR to meta‑learning, transfer learning, and partially observable settings, and suggests that similar joint‑experience ideas could benefit other multi‑agent algorithms that suffer from per‑agent sample inefficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment