SeeUPO: Sequence-Level Agentic-RL with Convergence Guarantees
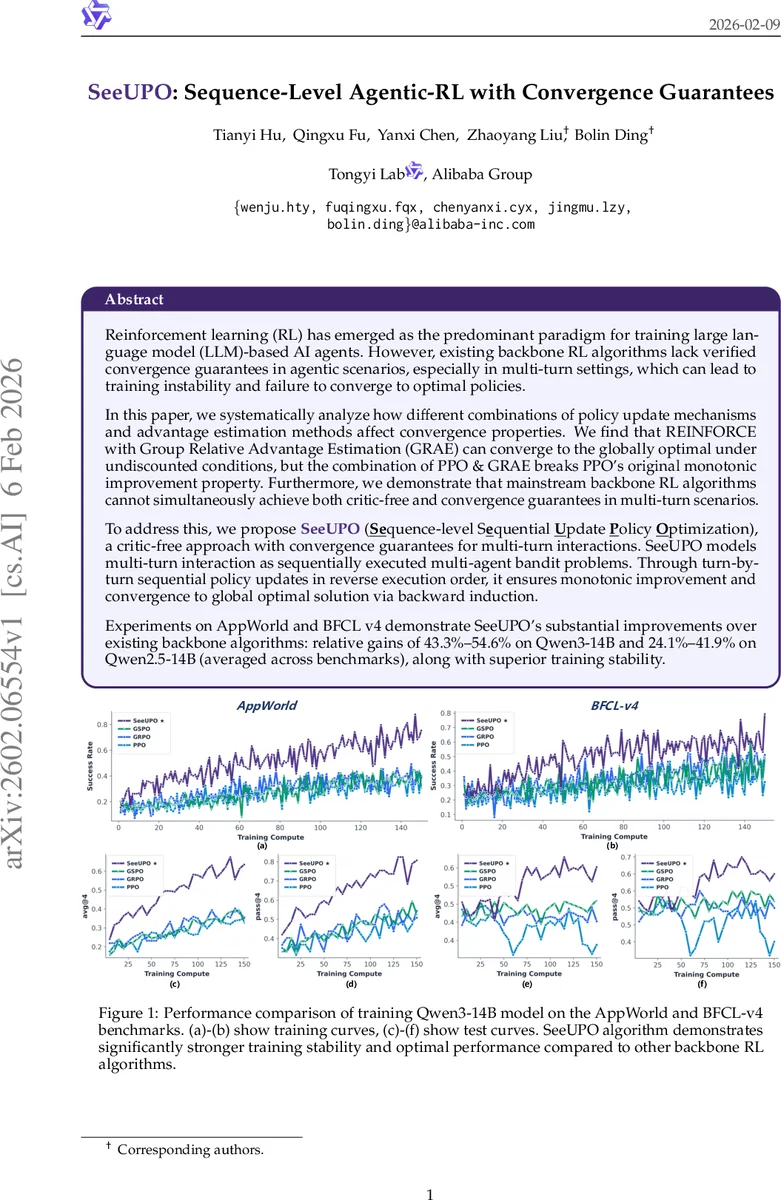
Reinforcement learning (RL) has emerged as the predominant paradigm for training large language model (LLM)-based AI agents. However, existing backbone RL algorithms lack verified convergence guarantees in agentic scenarios, especially in multi-turn settings, which can lead to training instability and failure to converge to optimal policies. In this paper, we systematically analyze how different combinations of policy update mechanisms and advantage estimation methods affect convergence properties in single/multi-turn scenarios. We find that REINFORCE with Group Relative Advantage Estimation (GRAE) can converge to the globally optimal under undiscounted conditions, but the combination of PPO & GRAE breaks PPO’s original monotonic improvement property. Furthermore, we demonstrate that mainstream backbone RL algorithms cannot simultaneously achieve both critic-free and convergence guarantees in multi-turn scenarios. To address this, we propose SeeUPO (Sequence-level Sequential Update Policy Optimization), a critic-free approach with convergence guarantees for multi-turn interactions. SeeUPO models multi-turn interaction as sequentially executed multi-agent bandit problems. Through turn-by-turn sequential policy updates in reverse execution order, it ensures monotonic improvement and convergence to global optimal solution via backward induction. Experiments on AppWorld and BFCL v4 demonstrate SeeUPO’s substantial improvements over existing backbone algorithms: relative gains of 43.3%-54.6% on Qwen3-14B and 24.1%-41.9% on Qwen2.5-14B (averaged across benchmarks), along with superior training stability.
💡 Research Summary
The paper tackles a fundamental gap in the reinforcement‑learning (RL) methods used to train large language model (LLM) agents: while RL—especially policy‑gradient approaches such as PPO—has become the de‑facto backbone for “agentic” training, none of the existing algorithms provide provable convergence guarantees when the agent must interact over multiple turns. The authors first dissect the design space of current backbone algorithms along two orthogonal axes: (1) advantage estimation (Generalized Advantage Estimation, GAE, which relies on a critic, versus Group‑Relative Advantage Estimation, GRAE, a critic‑free method) and (2) policy‑update mechanism (pure REINFORCE versus the proximal policy update (PPU) used in PPO).
Through rigorous theoretical analysis they show:
- REINFORCE + GRAE (the RLOO style) converges to the globally optimal policy only in undiscounted (γ = 1) settings. In multi‑turn Markov Decision Processes (MDPs) the method lacks sample efficiency because it treats each turn as independent.
- PPO + GAE (the classic PPO pipeline) can guarantee monotonic improvement and convergence only when the critic perfectly approximates the true value function—a condition rarely met in practice, especially with massive LLMs.
- PPO + GRAE (embodied in GRPO, GSPO, etc.) breaks the monotonic improvement property in multi‑turn scenarios. The group‑variance normalization introduced in many implementations adds bias that violates the drift‑function conditions required by Mirror‑Learning proofs. The algorithm retains convergence only in contextual‑bandit (single‑turn) settings.
Consequently, the authors identify a fundamental trade‑off: existing backbone RL algorithms cannot be both critic‑free and provably convergent in multi‑turn environments.
To resolve this, they propose SeeUPO (Sequence‑level Sequential Update Policy Optimization). The key insight is to reinterpret a multi‑turn interaction as a sequence of single‑turn bandit problems, each associated with a virtual “agent” representing a turn. SeeUPO then performs reverse‑order sequential policy updates (starting from the last turn and moving backward to the first). This reverse update enables a backward‑induction argument: when later turns have already been optimized to optimality, the current turn can be optimized against a fixed optimal future, guaranteeing that the joint return improves monotonically.
The theoretical foundation rests on Heterogeneous‑Agent Mirror Learning (HAML), an extension of Mirror Learning to multi‑agent settings. By defining a per‑turn drift function (essentially a KL‑divergence between old and new turn policies) and decomposing the joint advantage into conditional advantages, SeeUPO satisfies the HAML conditions. The authors prove that each reverse update yields a non‑decreasing joint objective and that the entire procedure converges to the globally optimal multi‑turn policy, even without any critic.
Empirically, SeeUPO is evaluated on two challenging multi‑turn benchmarks: AppWorld (tool‑use and web navigation) and BFCL‑v4 (complex code‑generation tasks). Experiments are conducted with two LLM families, Qwen3‑14B and Qwen2.5‑14B, comparing against PPO‑GAE, PPO‑GRAE, REINFORCE‑GRAE (RLOO), GRPO, and GSPO. Results show:
- On Qwen3‑14B, SeeUPO attains avg@4 = 60.80 % and pass@4 = 72.85 %, representing 43.3 %–54.6 % relative improvement over baselines.
- On Qwen2.5‑14B, it reaches avg@4 = 53.07 % and pass@4 = 63.59 %, a 24.1 %–41.9 % gain.
- Training curves demonstrate markedly higher stability: no catastrophic performance drops are observed, unlike PPO‑based methods that sometimes diverge.
- Ablation studies confirm that the reverse‑order update is essential; a forward‑order variant leads to significantly worse performance, validating the backward‑induction theory.
The paper’s contributions are threefold: (1) a comprehensive convergence analysis of mainstream RL backbones for LLM agents, exposing the critic‑free vs. convergence trade‑off; (2) the novel SeeUPO algorithm that simultaneously achieves critic‑free operation and provable convergence in multi‑turn settings via a multi‑agent bandit formulation and HAML‑based reverse updates; (3) extensive empirical validation showing substantial performance lifts and improved training stability.
Limitations are acknowledged: SeeUPO assumes a known, fixed number of turns, which may require padding or masking for variable‑length dialogues; it currently relies solely on policy networks, leaving open the question of whether hybrid critic‑augmented variants could further boost sample efficiency; and experiments are confined to text‑based benchmarks, so future work should test the method in multimodal or embodied environments.
In summary, SeeUPO introduces a theoretically sound and practically effective paradigm for training LLM‑based agents in multi‑turn contexts, breaking the long‑standing barrier that forced researchers to choose between critic‑free simplicity and convergence guarantees. This work paves the way for more reliable, scalable, and autonomous AI agents across a broad spectrum of real‑world applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment