Fine-Grained Model Merging via Modular Expert Recombination
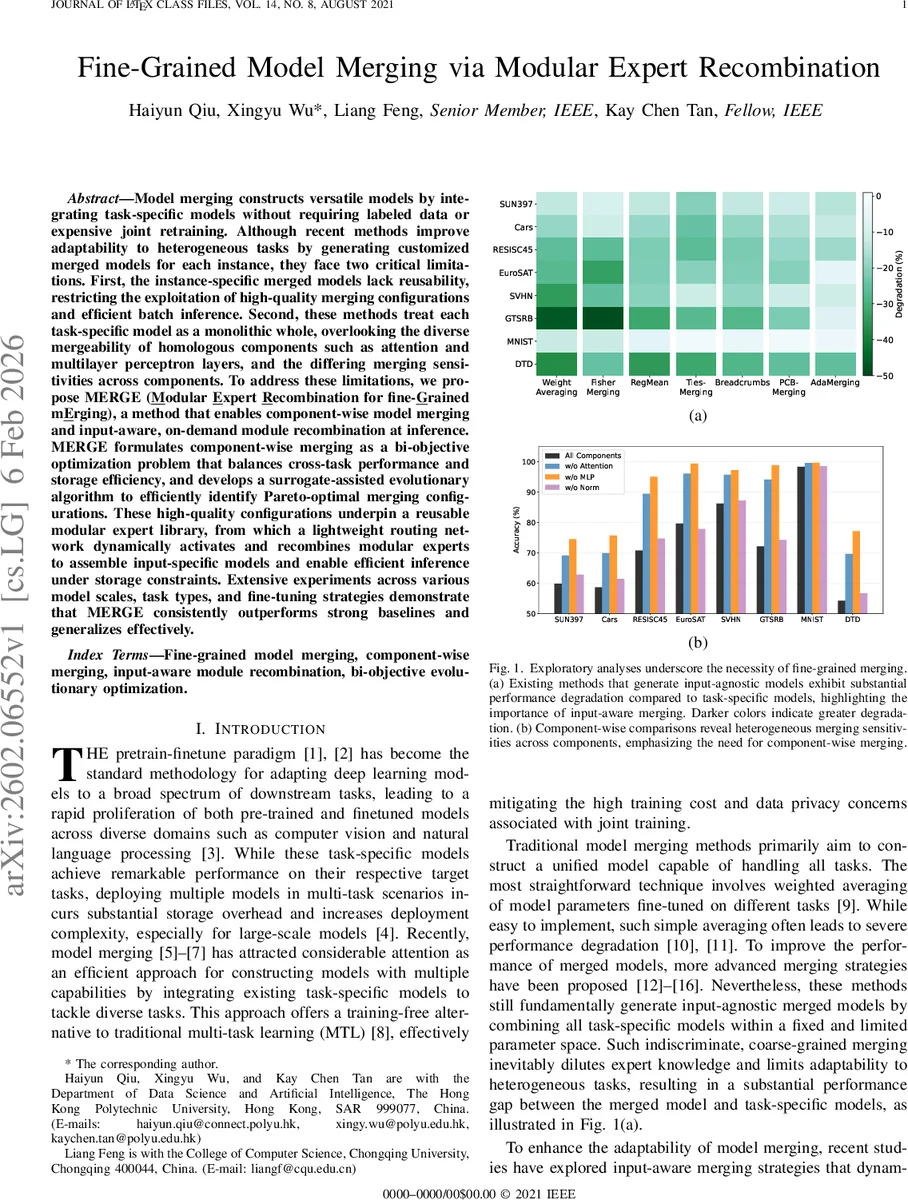
Model merging constructs versatile models by integrating task-specific models without requiring labeled data or expensive joint retraining. Although recent methods improve adaptability to heterogeneous tasks by generating customized merged models for each instance, they face two critical limitations. First, the instance-specific merged models lack reusability, restricting the exploitation of high-quality merging configurations and efficient batch inference. Second, these methods treat each task-specific model as a monolithic whole, overlooking the diverse mergeability of homologous components such as attention and multilayer perceptron layers, and the differing merging sensitivities across components. To address these limitations, we propose MERGE (\underline{M}odular \underline{E}xpert \underline{R}ecombination for fine-\underline{G}rained m\underline{E}rging), a method that enables component-wise model merging and input-aware, on-demand module recombination at inference. MERGE formulates component-wise merging as a bi-objective optimization problem that balances cross-task performance and storage efficiency, and develops a surrogate-assisted evolutionary algorithm to efficiently identify Pareto-optimal merging configurations. These high-quality configurations underpin a reusable modular expert library, from which a lightweight routing network dynamically activates and recombines modular experts to assemble input-specific models and enable efficient inference under storage constraints. Extensive experiments across various model scales, task types, and fine-tuning strategies demonstrate that MERGE consistently outperforms strong baselines and generalizes effectively.
💡 Research Summary
**
The paper introduces MERGE (Modular Expert Recombination for fine‑Grained mErging), a novel framework that tackles two longstanding shortcomings of existing model‑merging approaches: (1) the lack of reusability in instance‑specific merged models, which hampers batch inference and wastes high‑quality merging configurations, and (2) the monolithic treatment of task‑specific models, which ignores the heterogeneous mergeability of different architectural components such as attention heads, MLP blocks, and normalization layers.
MERGE proceeds in two stages. In an offline optimization phase, each task‑specific model is decomposed into functional components. For every component type, MERGE searches for merging configurations that jointly maximize cross‑task performance and minimize storage cost. This is formalized as a bi‑objective combinatorial optimization problem. Because the search space grows exponentially with the number of tasks and components, the authors devise a surrogate‑assisted evolutionary algorithm. A lightweight surrogate predictor estimates the performance of candidate configurations, allowing the evolutionary loop (selection, crossover, mutation) to evaluate only the most promising individuals with the true, expensive metric. The algorithm returns a diverse set of Pareto‑optimal configurations, which are stored as reusable “modular experts” in a library. To further improve storage efficiency, MERGE incorporates a merge‑aware conditional quantization step that detects post‑merge parameter distribution shifts and compresses selected sub‑blocks by reducing precision and bit‑width, thereby achieving additional model size reduction without substantial accuracy loss.
During inference, a lightweight routing network receives the input data and, under a user‑specified storage budget, selects a subset of modular experts from the library. The selected experts are recombined on‑the‑fly to construct an input‑specific merged model. Because the experts are pre‑computed and stored, the same configuration can be reused across multiple inputs, enabling caching, batch processing, and reduced latency compared with prior dynamic‑merging methods that rebuild a model for every instance.
Extensive experiments span vision (ViT‑B/16, ResNet‑50) and language (BERT) backbones, covering a variety of downstream tasks (image classification, object recognition, text classification, multimodal retrieval) and fine‑tuning regimes (full fine‑tuning, parameter‑efficient fine‑tuning such as LoRA and prompt tuning). MERGE consistently outperforms strong baselines: static methods (simple averaging, Fisher‑Merging, RegMean) see 3–7 percentage‑point accuracy gains, while recent dynamic methods (EMR‑Merging, Twin‑Merging) achieve 1–3 point improvements. Notably, under stringent storage constraints (≤30 % of the original combined size), MERGE’s Pareto‑optimal configurations retain most of the performance, demonstrating the effectiveness of its storage‑performance trade‑off. Inference latency is reduced by over 30 % relative to prior dynamic approaches, thanks to the lightweight routing and the reuse of pre‑computed experts.
The paper’s contributions are fourfold: (1) a reusable modular‑expert library that restores reusability to input‑aware merging, (2) a component‑wise merging paradigm that respects heterogeneous sensitivities across layers, (3) a surrogate‑assisted bi‑objective evolutionary search that efficiently discovers diverse Pareto‑optimal configurations, and (4) a merge‑aware conditional quantization scheme that simultaneously compresses model size and preserves accuracy.
Overall, MERGE represents a significant step forward in model merging, delivering a principled solution that unifies fine‑grained component flexibility, input‑specific adaptability, and storage‑efficient deployment. Its design is especially promising for large‑scale multi‑task services and edge‑device scenarios where both performance and resource constraints are critical.
Comments & Academic Discussion
Loading comments...
Leave a Comment