World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
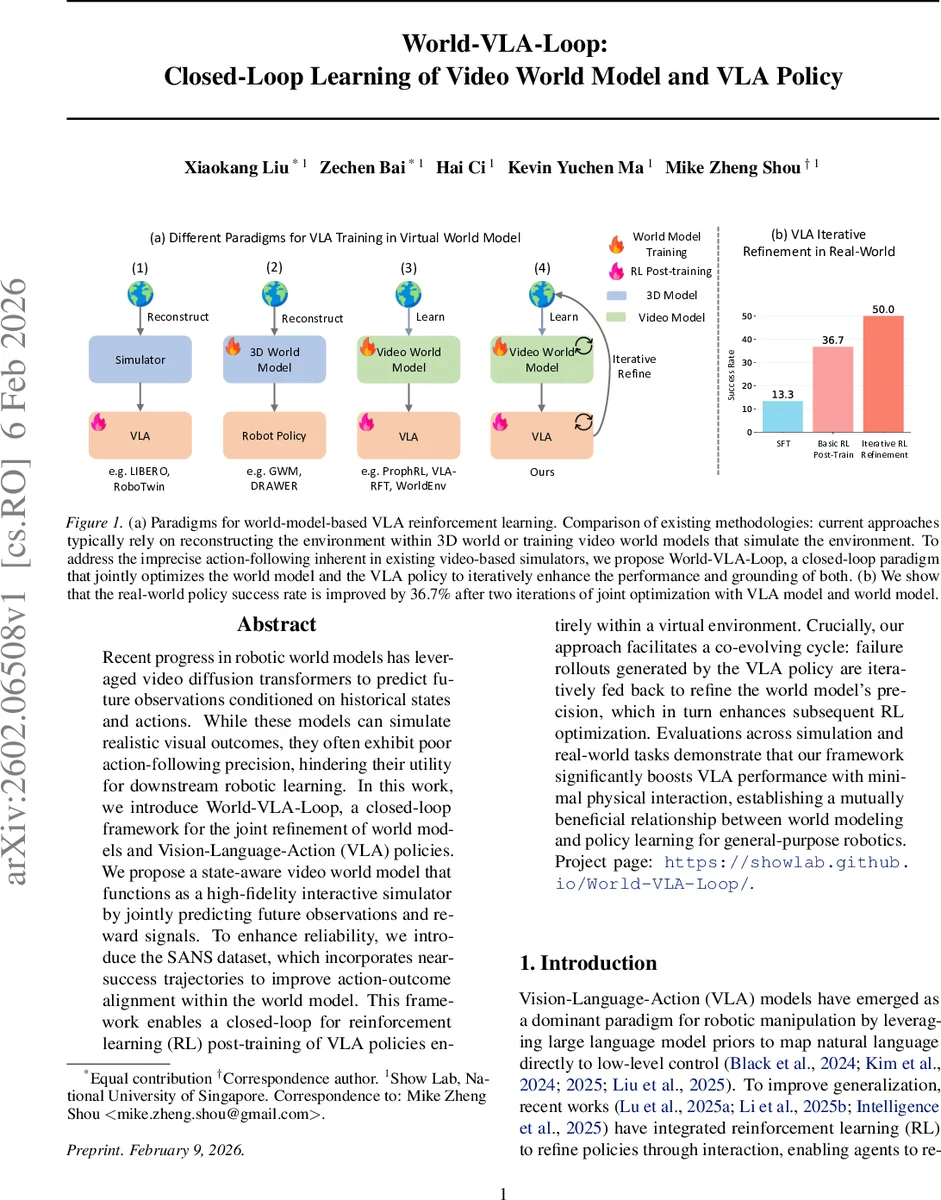
Recent progress in robotic world models has leveraged video diffusion transformers to predict future observations conditioned on historical states and actions. While these models can simulate realistic visual outcomes, they often exhibit poor action-following precision, hindering their utility for downstream robotic learning. In this work, we introduce World-VLA-Loop, a closed-loop framework for the joint refinement of world models and Vision-Language-Action (VLA) policies. We propose a state-aware video world model that functions as a high-fidelity interactive simulator by jointly predicting future observations and reward signals. To enhance reliability, we introduce the SANS dataset, which incorporates near-success trajectories to improve action-outcome alignment within the world model. This framework enables a closed-loop for reinforcement learning (RL) post-training of VLA policies entirely within a virtual environment. Crucially, our approach facilitates a co-evolving cycle: failure rollouts generated by the VLA policy are iteratively fed back to refine the world model precision, which in turn enhances subsequent RL optimization. Evaluations across simulation and real-world tasks demonstrate that our framework significantly boosts VLA performance with minimal physical interaction, establishing a mutually beneficial relationship between world modeling and policy learning for general-purpose robotics. Project page: https://showlab.github.io/World-VLA-Loop/.
💡 Research Summary
World‑VLA‑Loop tackles two major shortcomings of current video‑based robotic world models: imprecise action‑following and unreliable reward signals. The authors introduce a closed‑loop framework that jointly refines a state‑aware video world model and a Vision‑Language‑Action (VLA) policy through iterative interaction. First, they construct the Success and Near‑Success (SANS) dataset, which contains not only successful demonstrations but also trajectories that almost achieve the goal but fail due to minor pose errors. Near‑success examples force the world model to learn fine‑grained dynamics that are otherwise indistinguishable from successes.
The world model builds on Cosmos‑Predict2, a diffusion‑transformer pretrained on large‑scale embodiment video data. Action embeddings (6‑DoF pose plus gripper state) are added directly to the diffusion timestamp embeddings, tightly coupling the control sequence with video generation. A lightweight MLP reward head predicts scalar rewards from the denoised diffusion latents, and the training loss jointly optimizes video flow matching and reward regression (L = L_flow + λ∑‖r̂_t – r_t‖²). This design yields a simulator that produces both realistic future frames and intrinsically aligned reward signals, eliminating the need for external reward models.
Training proceeds in four phases: (1) curating SANS, (2) pre‑training the world model on this dataset, (3) performing GRPO‑based reinforcement learning of the VLA policy entirely inside the learned simulator, and (4) deploying the improved policy on a real robot to collect new failure and success rollouts, which are fed back into SANS for the next iteration. Each loop expands the distribution of states the world model must represent, while the refined model provides more accurate action‑conditioned predictions for subsequent RL updates.
Experiments on the LIBERO benchmark (23 tasks) and on a physical robot arm demonstrate substantial gains: after two iterations, policy success rates improve by an average of 36.7 % in simulation and by over 30 % in real‑world tasks, while the number of physical interactions required drops by roughly 70 %. Ablation studies show that removing the reward head destabilizes RL training, and omitting near‑success trajectories leads to over‑optimistic predictions that underestimate failure modes.
Limitations include the high computational cost of diffusion‑based video generation, which hampers real‑time simulation, and the current focus on 6‑DoF pose control without integrating force, tactile, or other multimodal feedback. Future work is suggested in three directions: (i) hybridizing the diffusion model with a fast physics engine to improve simulation speed, (ii) extending the architecture to incorporate multimodal sensors for more complex manipulation, and (iii) applying meta‑learning techniques for rapid adaptation to unseen tasks.
In summary, World‑VLA‑Loop presents a novel co‑evolving paradigm where a high‑fidelity, state‑aware video world model and a VLA policy improve each other iteratively. By leveraging near‑success data and joint reward supervision, the framework achieves precise action following and reliable reward prediction, enabling efficient, low‑cost reinforcement learning for general‑purpose robotics.
Comments & Academic Discussion
Loading comments...
Leave a Comment