Revisiting the Shape Convention of Transformer Language Models
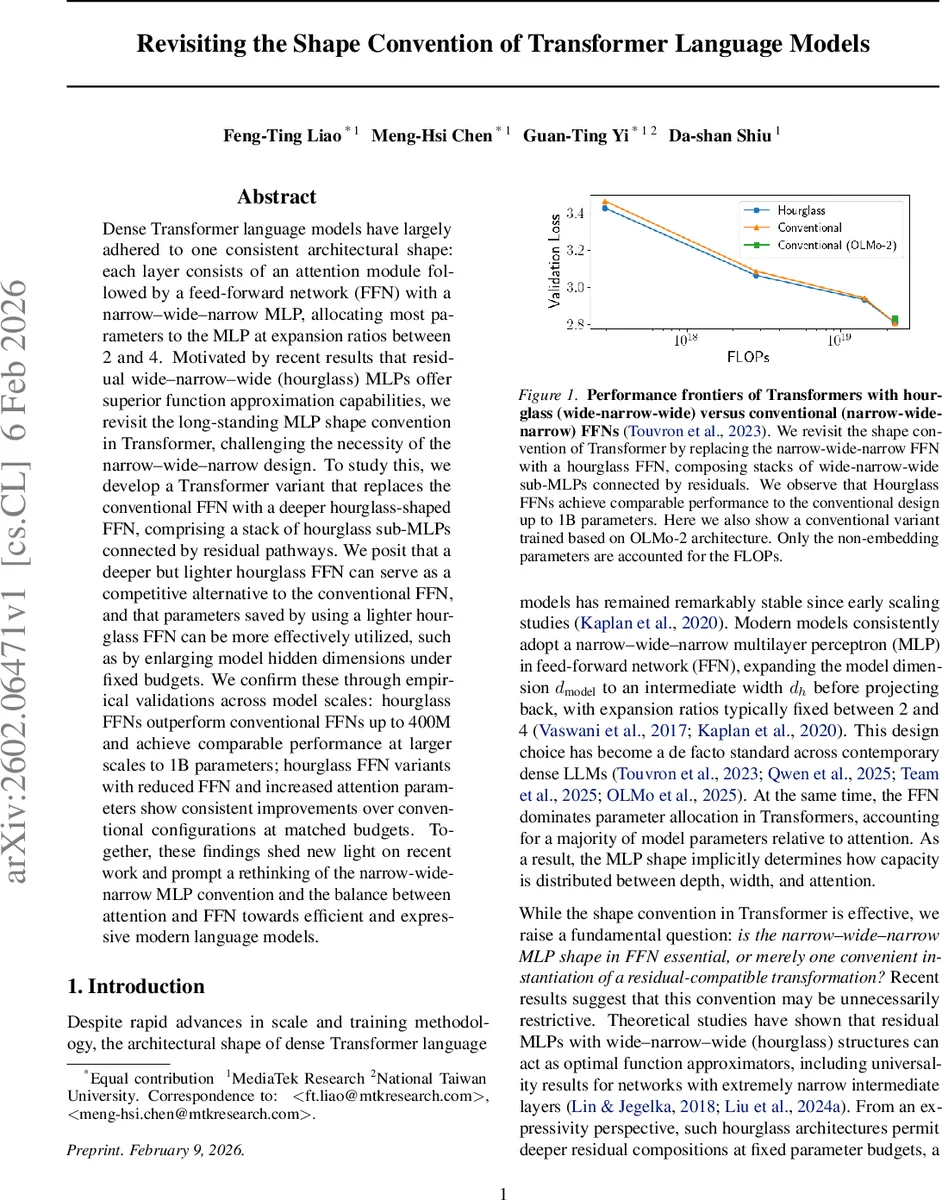
Dense Transformer language models have largely adhered to one consistent architectural shape: each layer consists of an attention module followed by a feed-forward network (FFN) with a narrow-wide-narrow MLP, allocating most parameters to the MLP at expansion ratios between 2 and 4. Motivated by recent results that residual wide-narrow-wide (hourglass) MLPs offer superior function approximation capabilities, we revisit the long-standing MLP shape convention in Transformer, challenging the necessity of the narrow-wide-narrow design. To study this, we develop a Transformer variant that replaces the conventional FFN with a deeper hourglass-shaped FFN, comprising a stack of hourglass sub-MLPs connected by residual pathways. We posit that a deeper but lighter hourglass FFN can serve as a competitive alternative to the conventional FFN, and that parameters saved by using a lighter hourglass FFN can be more effectively utilized, such as by enlarging model hidden dimensions under fixed budgets. We confirm these through empirical validations across model scales: hourglass FFNs outperform conventional FFNs up to 400M and achieve comparable performance at larger scales to 1B parameters; hourglass FFN variants with reduced FFN and increased attention parameters show consistent improvements over conventional configurations at matched budgets. Together, these findings shed new light on recent work and prompt a rethinking of the narrow-wide-narrow MLP convention and the balance between attention and FFN towards efficient and expressive modern language models.
💡 Research Summary
This paper revisits the long‑standing design of the feed‑forward network (FFN) in dense Transformer language models. The conventional architecture uses a “narrow‑wide‑narrow” multilayer perceptron (MLP) that expands the model dimension d_model to an intermediate width d_h (typically 2–4× larger) and then projects back, allocating the majority of parameters to the FFN. Recent theoretical work has shown that residual MLPs with a “wide‑narrow‑wide” (hourglass) shape can achieve universal approximation with fewer parameters, especially when depth is increased. Motivated by these findings, the authors replace the standard FFN with a deeper hourglass‑shaped FFN composed of K stacked hourglass sub‑MLPs, each featuring a down‑projection to a bottleneck dimension d_h < d_model, a non‑linear activation (SwiGLU), and an up‑projection back to d_model. The overall parameter count becomes L · (Attn(d_model) + K · 3 · d_h · d_model), allowing the model to trade FFN width for depth without exploding the parameter budget.
The experimental program is three‑fold. First, with fixed model dimension (d_model = 768) and layer count (L = 12), the authors vary d_h and K to explore the width‑vs‑depth trade‑off. They find that reducing d_h to roughly one‑quarter of the conventional size (e.g., 384) while increasing K to 8–10 yields the lowest validation loss and perplexity. Second, keeping the total non‑embedding parameter budget constant, they reallocate the saved FFN parameters to either enlarge the attention dimension or add more Transformer layers. On a 113 M‑parameter model, increasing the attention size from 28 M to 30 M or raising the layer count from 12 to 14 improves perplexity by 0.3–0.5 % relative to the baseline narrow‑wide‑narrow model. Third, they scale the approach across four model sizes (≈113 M, 400 M, 800 M, and 1 B parameters). Hourglass FFNs consistently outperform the baseline up to 400 M, achieving 0.2–0.4 % lower perplexity; at 1 B the performance gap closes, indicating that the hourglass design is competitive even at large scale.
A notable insight is the “U‑shaped” width‑depth trade‑off: keeping d_model moderate while increasing the number of layers yields the best efficiency, and the optimal hourglass configuration typically uses K = 6–8 and a bottleneck ratio d_h ≈ 0.4 · d_model. This configuration maximizes the benefit of parameter reallocation from the FFN to the attention module, improving the model’s ability to capture pairwise token interactions without sacrificing the compositional depth provided by the stacked hourglass blocks.
In summary, the paper demonstrates that the narrow‑wide‑narrow FFN is not a strict necessity; a deeper but narrower hourglass FFN can achieve equal or better performance under the same parameter budget, especially for models under 400 M parameters. The findings suggest new avenues for efficient model design, particularly in resource‑constrained settings or when seeking to balance attention capacity against FFN depth. Future work may explore integrating hourglass FFNs with mixture‑of‑experts, applying them to different tokenization schemes, or extending the analysis to multilingual and instruction‑tuned settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment