Difficulty-Estimated Policy Optimization
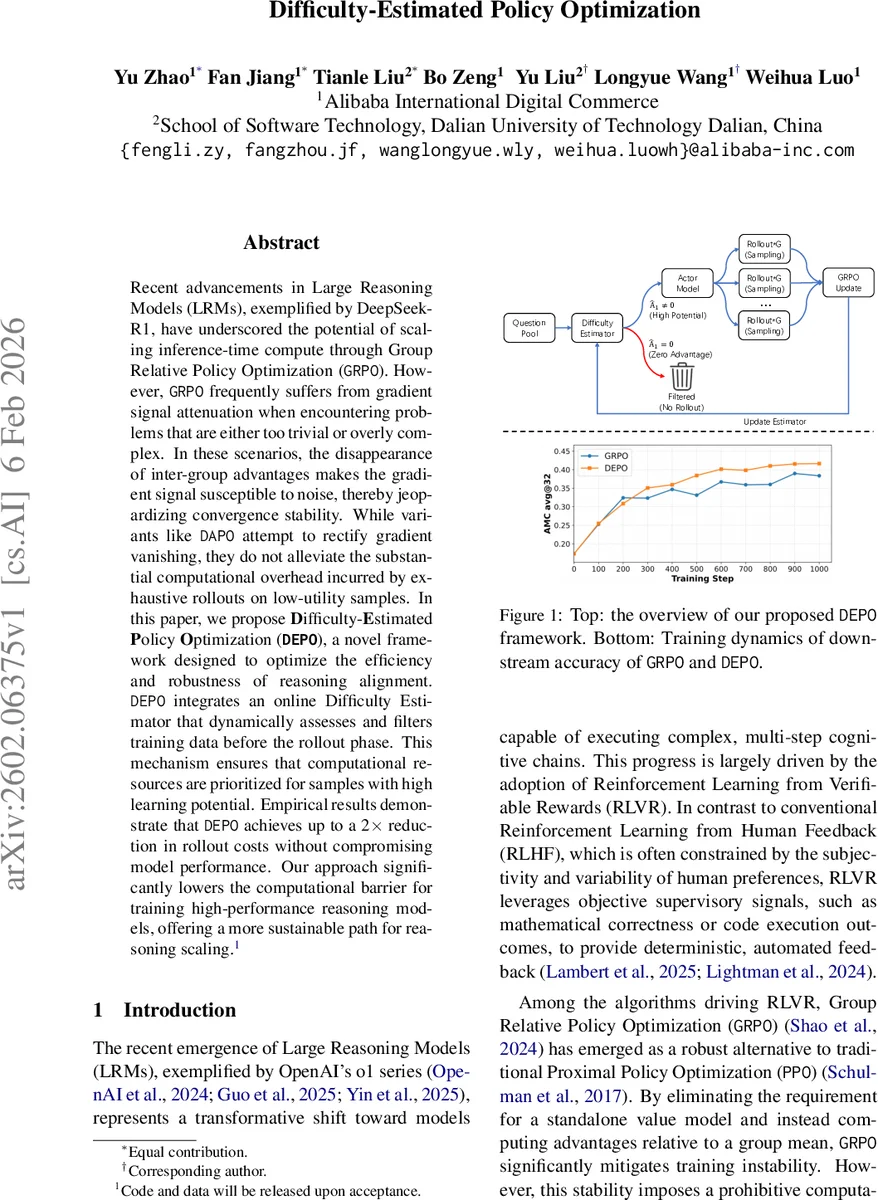
Recent advancements in Large Reasoning Models (LRMs), exemplified by DeepSeek-R1, have underscored the potential of scaling inference-time compute through Group Relative Policy Optimization (GRPO). However, GRPO frequently suffers from gradient signal attenuation when encountering problems that are either too trivial or overly complex. In these scenarios, the disappearance of inter-group advantages makes the gradient signal susceptible to noise, thereby jeopardizing convergence stability. While variants like DAPO attempt to rectify gradient vanishing, they do not alleviate the substantial computational overhead incurred by exhaustive rollouts on low-utility samples. In this paper, we propose Difficulty-Estimated Policy Optimization (DEPO), a novel framework designed to optimize the efficiency and robustness of reasoning alignment. DEPO integrates an online Difficulty Estimator that dynamically assesses and filters training data before the rollout phase. This mechanism ensures that computational resources are prioritized for samples with high learning potential. Empirical results demonstrate that DEPO achieves up to a 2x reduction in rollout costs without compromising model performance. Our approach significantly lowers the computational barrier for training high-performance reasoning models, offering a more sustainable path for reasoning scaling. Code and data will be released upon acceptance.
💡 Research Summary
The paper addresses two critical bottlenecks in training large reasoning models (LRMs) with Group Relative Policy Optimization (GRPO): (1) gradient signal attenuation (the “zero‑variance” problem) when sampled responses yield uniform rewards, and (2) the high computational cost of exhaustive rollouts for every training prompt. Existing mitigations such as dynamic oversampling, offline curriculum pruning, or perplexity‑based re‑ranking either still require costly rollouts or suffer from latency and stale difficulty estimates because they treat difficulty as a static property.
To overcome these issues, the authors propose Difficulty‑Estimated Policy Optimization (DEPO), a plug‑and‑play framework that integrates a lightweight, online Difficulty Estimator into the GRPO training loop. The estimator is built on a pre‑trained BERT encoder with two heads: (i) an estimated advantage head that predicts a normalized score approximating the true advantage that would be obtained after a rollout, and (ii) a perplexity head that predicts the current actor model’s perplexity on the prompt. Training of the estimator uses a composite loss: a binary‑cross‑entropy (BCE) loss for advantage prediction (L_DE), a distillation BCE loss aligning the perplexity prediction with the actor’s actual perplexity (L_distill), and a pairwise ranking loss (L_rank) that enforces a correct relative ordering of difficulty across prompt pairs. The BCE loss is deliberately chosen over MSE because its gradient does not vanish near the extremes, ensuring stable learning for very easy or very hard prompts.
Crucially, the estimator is updated online: after each GRPO iteration, the actual advantages and log‑probabilities obtained from the rollouts serve as ground‑truth labels for the estimator. This synchronised update allows the difficulty model to track the evolving capabilities of the actor in real time, eliminating the lag inherent in offline curricula. To avoid a “cold‑start” problem where an uncalibrated estimator would discard valuable data, the authors introduce a warm‑up phase. During the first n training steps, the estimator is trained with a reduced learning rate and only the advantage loss, allowing it to acquire a basic understanding of the task before full multi‑objective optimisation begins.
During training, each batch of prompts is first passed through the Difficulty Estimator. Prompts whose predicted advantage is close to zero are filtered out before any rollout is performed, thereby saving the expensive sampling and reward computation for those low‑utility samples. The remaining prompts proceed through the standard GRPO pipeline (sampling multiple responses, computing group‑relative advantages, and applying the clipped surrogate objective with a KL penalty). After the GRPO update, the estimator receives the true advantage values and updates its parameters.
Empirical evaluation is conducted on several RL‑VR (Reinforcement Learning from Verifiable Rewards) benchmarks, including mathematical reasoning and code‑execution tasks. The results show that DEPO consistently outperforms vanilla GRPO by 1.5 %–2.4 % absolute accuracy while halving the rollout cost on average (up to a 50 % reduction in total compute). When combined with other state‑of‑the‑art methods such as DAPO, DEPO yields an additional 2.4 % accuracy gain and a further 50 % reduction in computational overhead, demonstrating its orthogonal nature. Training curves reveal higher gradient variance (indicating richer learning signals) and smoother loss trajectories, confirming that the zero‑variance problem is effectively mitigated.
In summary, DEPO delivers three major benefits: (1) computational efficiency by pre‑emptively discarding trivial or intractable prompts, (2) enhanced learning stability through richer, non‑vanishing gradient signals, and (3) adaptivity via an online difficulty model that evolves with the policy. The framework is lightweight, requires only a modest BERT‑based estimator, and can be retro‑fitted to existing GRPO‑based pipelines, offering a practical path toward more sustainable scaling of high‑performance reasoning models.
Comments & Academic Discussion
Loading comments...
Leave a Comment