SPDA-SAM: A Self-prompted Depth-Aware Segment Anything Model for Instance Segmentation
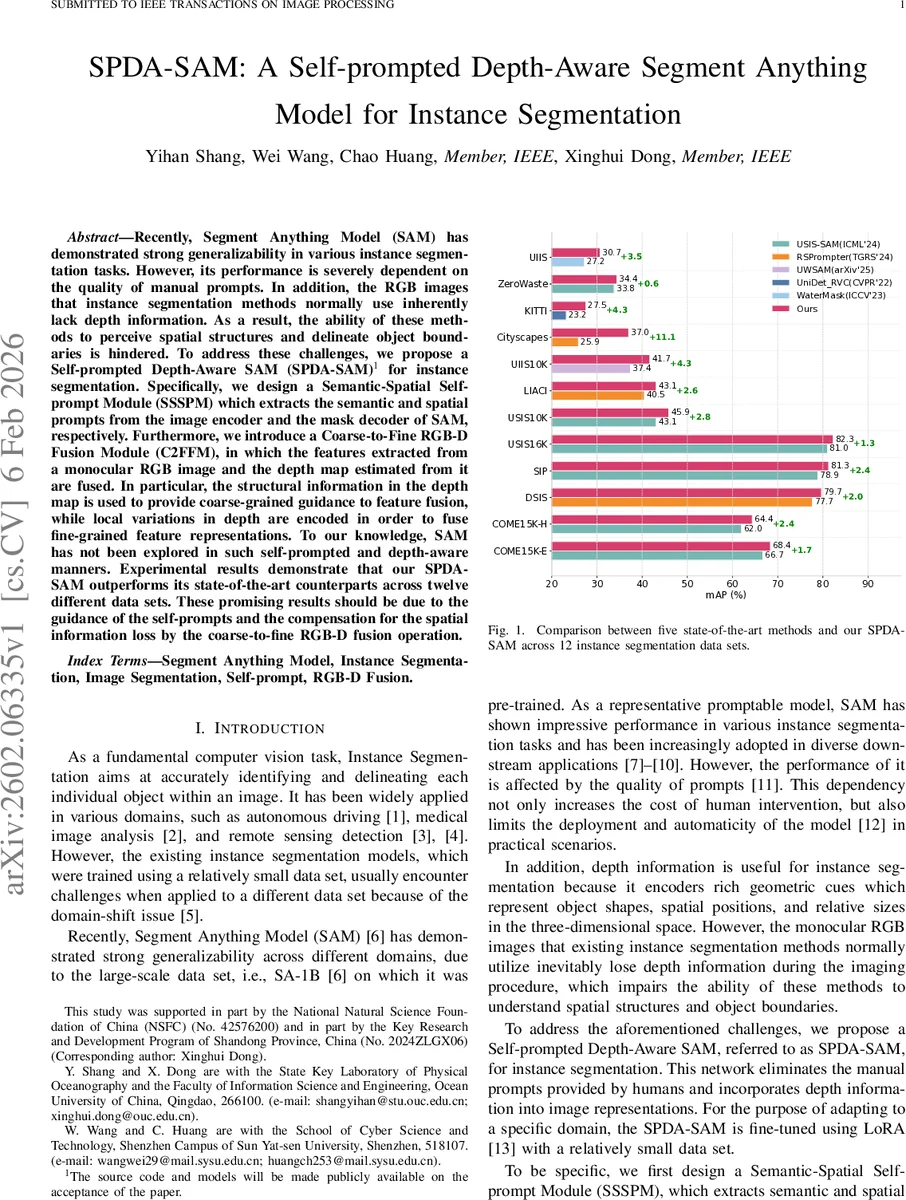
Recently, Segment Anything Model (SAM) has demonstrated strong generalizability in various instance segmentation tasks. However, its performance is severely dependent on the quality of manual prompts. In addition, the RGB images that instance segmentation methods normally use inherently lack depth information. As a result, the ability of these methods to perceive spatial structures and delineate object boundaries is hindered. To address these challenges, we propose a Self-prompted Depth-Aware SAM (SPDA-SAM) for instance segmentation. Specifically, we design a Semantic-Spatial Self-prompt Module (SSSPM) which extracts the semantic and spatial prompts from the image encoder and the mask decoder of SAM, respectively. Furthermore, we introduce a Coarse-to-Fine RGB-D Fusion Module (C2FFM), in which the features extracted from a monocular RGB image and the depth map estimated from it are fused. In particular, the structural information in the depth map is used to provide coarse-grained guidance to feature fusion, while local variations in depth are encoded in order to fuse fine-grained feature representations. To our knowledge, SAM has not been explored in such self-prompted and depth-aware manners. Experimental results demonstrate that our SPDA-SAM outperforms its state-of-the-art counterparts across twelve different data sets. These promising results should be due to the guidance of the self-prompts and the compensation for the spatial information loss by the coarse-to-fine RGB-D fusion operation.
💡 Research Summary
The paper introduces SPDA‑SAM, a novel framework that augments the Segment Anything Model (SAM) with self‑generated prompts and depth awareness to overcome two major limitations of existing instance‑segmentation pipelines: (1) heavy reliance on manually provided prompts, and (2) the loss of three‑dimensional spatial cues when only RGB images are used.
Architecture Overview
SPDA‑SAM consists of a dual‑path encoder and a self‑prompted decoder. The encoder re‑uses SAM’s backbone for two parallel streams: an RGB stream and a depth stream. The depth stream receives a monocular depth map generated by a pre‑trained depth‑estimation network (e.g., MonoDepth). Both streams are fine‑tuned with LoRA, allowing rapid adaptation to new domains with only a few annotated samples.
Semantic‑Spatial Self‑Prompt Module (SSSPM)
Instead of requiring external points, boxes, or masks, SSSPM automatically extracts two kinds of prompts from SAM’s internal representations:
- Semantic Prompt: derived from the final feature map of the image encoder, capturing high‑level contextual information.
- Spatial Prompt: taken from intermediate layers of the mask decoder that are sensitive to object boundaries, providing fine‑grained spatial cues.
These prompts are injected into SAM’s attention mechanisms, effectively guiding the mask decoder without any human input.
Coarse‑to‑Fine RGB‑D Fusion Module (C2FFM)
C2FFM fuses RGB and depth features at multiple scales:
- Coarse Fusion Block: depth features are down‑sampled, processed with dilated convolutions, reduced via a 1×1 convolution, up‑sampled, and finally passed through a sigmoid gate that modulates the RGB feature map. This step injects global structural information (e.g., object silhouettes).
- Four Fine Fusion Blocks: placed after Transformer blocks 2, 5, 8, and 11. For each block, RGB and depth tokens are flattened and cross‑attended in both directions (RGB‑query ↔ Depth‑key/value and vice‑versa). This hierarchical cross‑attention aligns local depth variations with RGB texture, sharpening boundaries and preserving fine details.
Training Strategy
The massive SAM parameters remain frozen; only low‑rank adapters (LoRA) are trained, drastically reducing memory and compute requirements. A small, domain‑specific dataset (tens to a few hundred images) suffices for fine‑tuning, enabling rapid deployment across diverse scenarios such as autonomous driving, underwater imaging, medical scans, and remote sensing.
Experimental Validation
The authors evaluate SPDA‑SAM on twelve public benchmarks (Cityscapes, KITTI, USIS‑SAM, COME15K, etc.). Across all datasets, SPDA‑SAM achieves higher mean Average Precision (mAP) than five state‑of‑the‑art baselines (USIS‑SAM, RSPrompter, UniDet_RVC, WaterMask, etc.), with improvements ranging from +1.7 to +11.1 percentage points. An extensive ablation study shows:
- Removing SSSPM (keeping only C2FFM) drops performance by ~1.5 pp, indicating the importance of self‑prompts.
- Removing C2FFM (keeping only SSSPM) drops performance by ~2.3 pp, confirming the benefit of depth fusion.
- Removing both modules reverts to vanilla SAM performance, which is significantly lower.
Limitations and Future Work
The approach depends on the quality of the monocular depth estimate; errors on reflective or transparent surfaces can misguide the fusion gates. Moreover, the dual‑encoder and multiple cross‑attention blocks increase FLOPs and memory, posing challenges for real‑time applications. Future directions include integrating more accurate depth sensors, designing lightweight fusion mechanisms, and visualizing the learned semantic/spatial prompts for better interpretability.
Conclusion
SPDA‑SAM demonstrates that automatic prompt generation combined with coarse‑to‑fine RGB‑D fusion can substantially improve SAM’s applicability to instance segmentation tasks that lack manual annotations and depth cues. The method delivers consistent gains across a wide variety of domains, suggesting strong potential for deployment in robotics, AR/VR, medical imaging, and other fields where accurate, prompt‑free segmentation is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment