Generative Modeling via Drifting
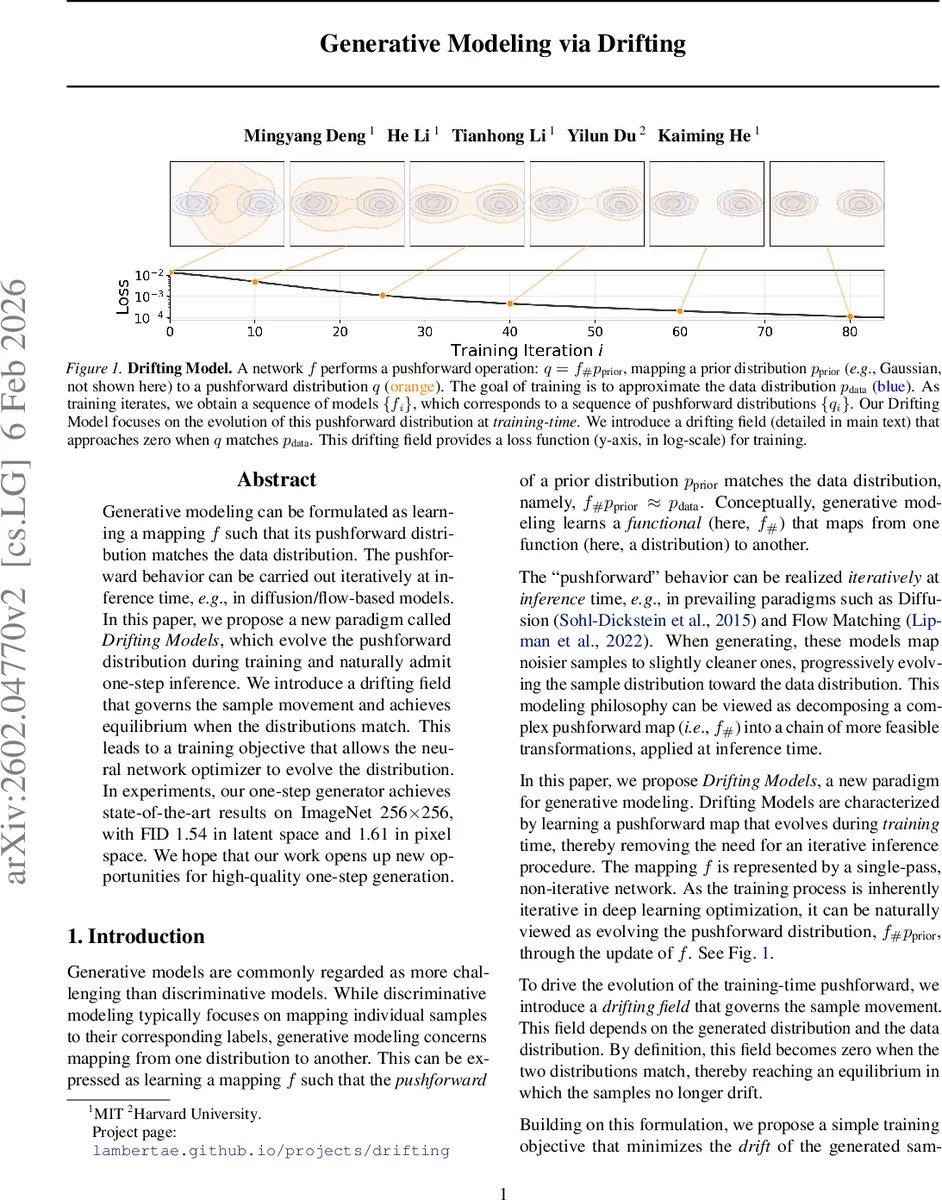
Generative modeling can be formulated as learning a mapping f such that its pushforward distribution matches the data distribution. The pushforward behavior can be carried out iteratively at inference time, for example in diffusion and flow-based models. In this paper, we propose a new paradigm called Drifting Models, which evolve the pushforward distribution during training and naturally admit one-step inference. We introduce a drifting field that governs the sample movement and achieves equilibrium when the distributions match. This leads to a training objective that allows the neural network optimizer to evolve the distribution. In experiments, our one-step generator achieves state-of-the-art results on ImageNet at 256 x 256 resolution, with an FID of 1.54 in latent space and 1.61 in pixel space. We hope that our work opens up new opportunities for high-quality one-step generation.
💡 Research Summary
The paper introduces a novel generative modeling paradigm called “Drifting Models,” which reframes the learning problem as an evolution of the push‑forward distribution during training rather than during inference. Traditional diffusion and flow‑based models rely on iterative SDE/ODE solvers at generation time, requiring many network evaluations to gradually transform noise into data. In contrast, Drifting Models evolve the mapping f : ε → x directly through the optimization process, so that a single forward pass of the trained network suffices to produce high‑quality samples.
The authors define a drifting field Vₚ,₍q₎(x) that depends on the current generated distribution q (the push‑forward of the prior under f) and the target data distribution p. The field is constructed to be anti‑symmetric, i.e., Vₚ,₍q₎ = –V_q,₍p₎, which guarantees that when p = q the field vanishes everywhere, establishing an equilibrium condition. Concretely, they decompose V into an attractive component V⁺ₚ(x) that pulls samples toward data points and a repulsive component V⁻_q(x) that pushes samples away from each other. Both components are expressed as kernel‑weighted mean‑shift vectors, using a Gaussian‑like kernel k(x, y) = exp(–‖x–y‖/τ). The final field V = V⁺ₚ – V⁻_q can be written as a double expectation over a positive (data) sample y⁺ and a negative (generated) sample y⁻, with a weight proportional to k(x, y⁺) k(x, y⁻).
Training is driven by minimizing the squared norm of this field: L = E_ε‖V(f_θ(ε))‖². Direct back‑propagation through V is avoided by employing a stop‑gradient trick: a “frozen target” x̂ = stopgrad(x + V) is computed using the current parameters, and the network is trained to reduce the mean‑squared error between its output x and x̂. This indirect optimization forces the network to move its samples in the direction prescribed by the drifting field, thereby reducing the field’s magnitude over successive iterations.
To handle high‑dimensional image data, the loss is applied not in pixel space but in a learned feature space. A pretrained self‑supervised encoder ϕ (e.g., a Vision Transformer) maps both real and generated images to feature vectors. The loss becomes ‖ϕ(x) – stopgrad(ϕ(x) + V(ϕ(x)))‖², and V is computed using the same kernel formulation on the feature vectors of positive and negative samples. Multi‑scale and multi‑location features are concatenated to provide richer gradients, akin to perceptual losses but without requiring paired targets.
Empirically, the authors train a single‑step generator on ImageNet at 256 × 256 resolution. Using the latent‑space generation protocol they achieve an FID of 1.54, and under the more demanding pixel‑space protocol they obtain an FID of 1.61. Both scores set new state‑of‑the‑art results among one‑step methods and are competitive with many multi‑step diffusion or flow models. The paper also includes ablation studies confirming that decreasing the drift norm correlates strongly with improved sample quality, and provides a theoretical heuristic (Appendix C.1) showing that, under mild non‑degeneracy assumptions, V ≈ 0 implies q ≈ p.
The work positions Drifting Models as a conceptually distinct alternative to adversarial GAN training, VAE ELBO optimization, normalizing‑flow likelihood maximization, and recent diffusion distillation approaches. By eliminating the need for iterative inference, Drifting Models promise faster deployment, lower computational cost, and easier integration into downstream pipelines. The authors suggest future directions such as learning the kernel parameters, extending the framework to video, 3‑D data, or text, and strengthening theoretical convergence guarantees. Overall, the paper delivers a compelling new viewpoint on generative modeling that unifies training dynamics with distribution matching through a principled drift field, achieving remarkable empirical performance with a remarkably simple inference procedure.
Comments & Academic Discussion
Loading comments...
Leave a Comment