Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
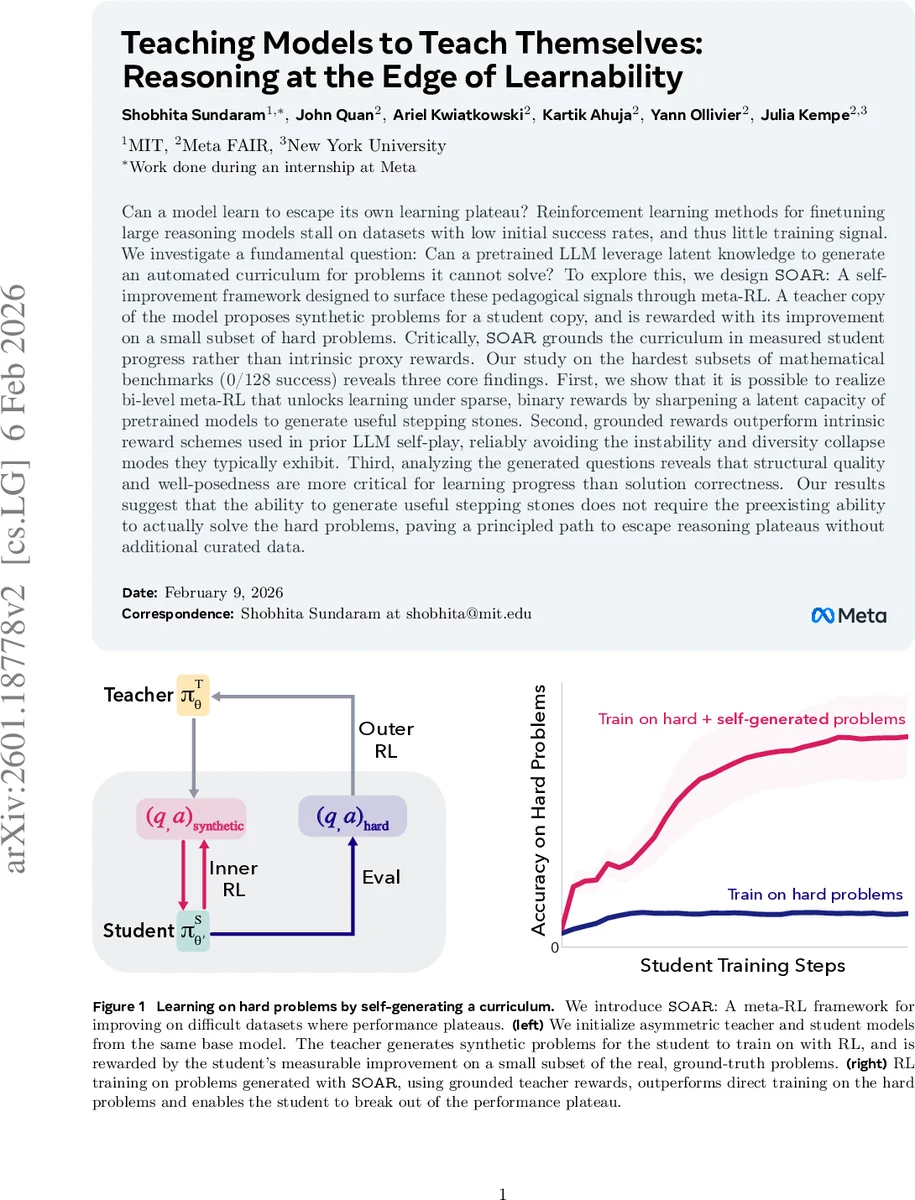
Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.
💡 Research Summary
The paper tackles a fundamental obstacle in fine‑tuning large language models (LLMs) for reasoning tasks: when the initial success rate on a target dataset is near zero, reinforcement learning with verifiable rewards (RL‑VR) provides almost no learning signal, and the model remains stuck on a performance plateau. Existing curriculum‑learning approaches either rely on manually curated intermediate datasets or on proxy difficulty estimates, both of which presuppose the existence of solvable “easy” problems. The authors ask whether a pretrained LLM can autonomously discover and generate its own “stepping‑stone” problems that make the hard target learnable, even when it cannot solve the target problems directly.
To answer this, they introduce SOAR (Self‑Optimization via Asymmetric RL), a bi‑level meta‑reinforcement‑learning framework that couples a teacher model with a student model. Both start from the same pretrained checkpoint, but the teacher’s role is to synthesize question‑answer pairs, while the student trains on those synthetic problems using standard RL‑VR (e.g., REINFORCE or RLOO). Crucially, the teacher’s reward is grounded: after the student finishes a short inner‑loop training on a generated batch, the teacher receives a scalar reward equal to the improvement in the student’s accuracy on a small, fixed subset of the original hard dataset (the “black‑box” reward). No external verification of the synthetic questions or answers is required; the usefulness of a generated pair is judged solely by its impact on downstream performance.
The outer loop trains the teacher with RLOO, sampling multiple batches of synthetic problems (group size g, batch size n). Each batch is used to update the student for a fixed number of steps, after which the student’s performance on a sampled evaluation set Q_R from the hard training data is measured. The teacher’s reward for a batch X_k is defined as
R(X_k) = Acc(π_S′_k(Q_R)) – Acc(π_S(Q_R)),
where π_S′_k denotes the student after training on X_k. This formulation avoids the need to back‑propagate through the entire inner training trajectory, sidestepping the computational intractability typical of bilevel optimization.
Experiments are conducted with Llama‑3.2‑3B‑Instruct on the most difficult subsets of the MATH and HARP benchmarks, where baseline RL‑VR achieves 0 / 128 success. Over 600 meta‑RL runs (multiple random seeds), SOAR yields dramatic gains: up to 4× improvement in Pass@1 and 2× in Pass@32 on MATH, and comparable lifts on HARP. Generated curricula also transfer: a teacher trained on one hard subset can produce useful questions for a different hard subset, indicating that the discovered stepping‑stones capture domain‑wide reasoning patterns rather than overfitting to a single problem set.
A key comparative analysis shows that grounded rewards outperform intrinsic proxy rewards (e.g., learnability scores, self‑consistency) used in prior LLM self‑play. Intrinsic schemes suffer from instability, reward hacking, and a collapse of question diversity, whereas SOAR’s black‑box grounding consistently drives the teacher toward producing diverse, well‑structured problems that genuinely aid the student.
Qualitative inspection of generated questions reveals that structural quality and well‑posedness matter more than answer correctness. Even when the teacher’s answer is wrong, a clear, appropriately challenging question can still push the student’s policy toward better reasoning strategies. This suggests that the latent knowledge required to formulate a useful problem is separable from the knowledge needed to solve it, and that meta‑RL can sharpen this latent capacity.
The paper’s contributions are threefold: (1) a practical implementation of a double meta‑RL loop that avoids inner‑loop unrolling, (2) a demonstration that grounding the teacher’s reward in real performance eliminates the pitfalls of intrinsic reward hacking, and (3) empirical evidence that problem structure outweighs solution accuracy in escaping reasoning plateaus. The authors discuss future directions, including scaling to larger models, extending to other domains (program synthesis, scientific reasoning), and enhancing teacher‑student asymmetry to further boost exploration.
In summary, SOAR provides a principled, data‑free method for LLMs to generate their own curricula, enabling them to break out of hard learning plateaus without any additional curated data. This work opens a new avenue for self‑improving AI systems that can autonomously discover the intermediate knowledge they need to acquire higher‑level capabilities.
Comments & Academic Discussion
Loading comments...
Leave a Comment