Uncovering Vulnerabilities of LLM-Assisted Cyber Threat Intelligence
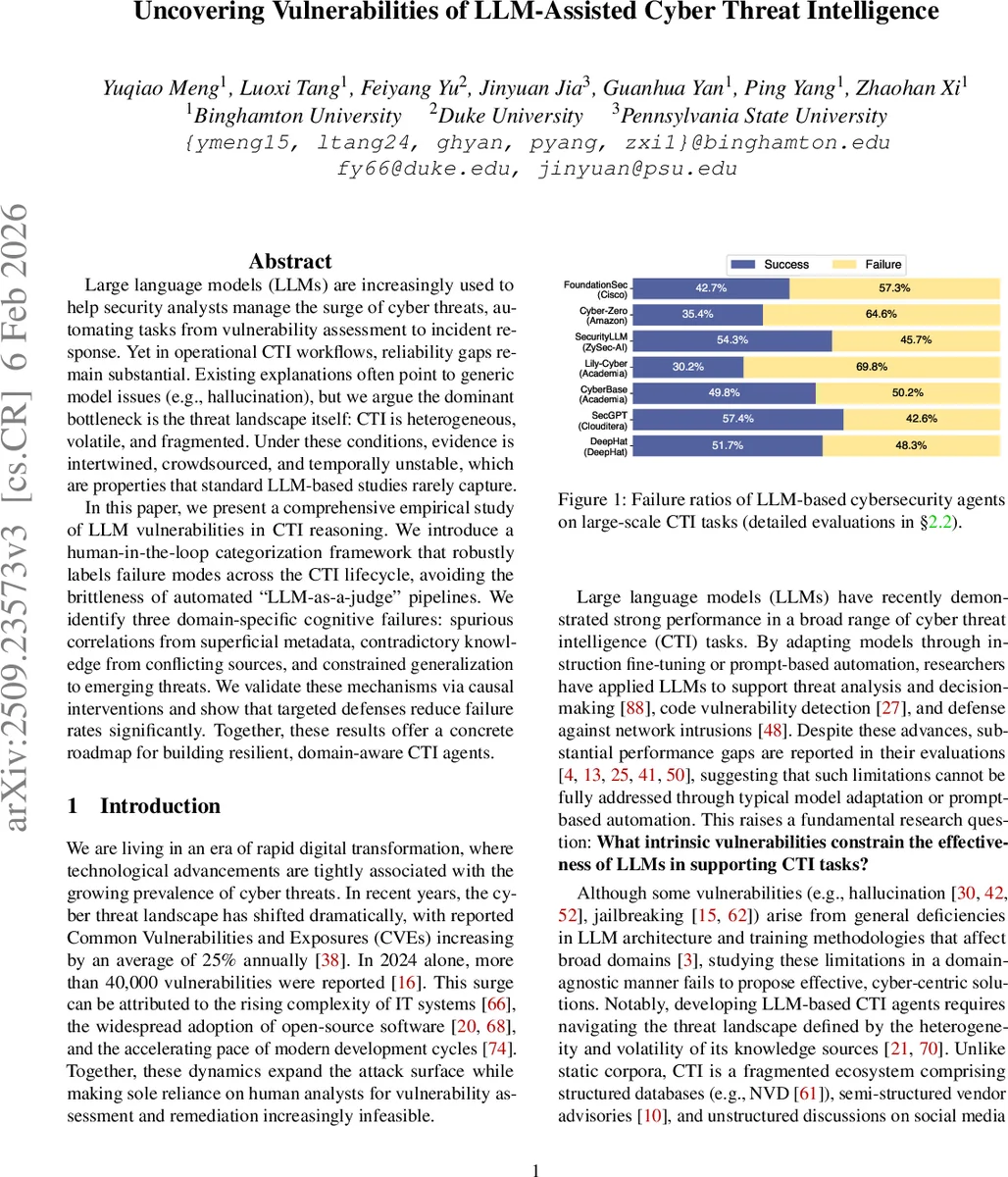
Large language models (LLMs) are increasingly used to help security analysts manage the surge of cyber threats, automating tasks from vulnerability assessment to incident response. Yet in operational CTI workflows, reliability gaps remain substantial. Existing explanations often point to generic model issues (e.g., hallucination), but we argue the dominant bottleneck is the threat landscape itself: CTI is heterogeneous, volatile, and fragmented. Under these conditions, evidence is intertwined, crowdsourced, and temporally unstable, which are properties that standard LLM-based studies rarely capture. In this paper, we present a comprehensive empirical study of LLM vulnerabilities in CTI reasoning. We introduce a human-in-the-loop categorization framework that robustly labels failure modes across the CTI lifecycle, avoiding the brittleness of automated “LLM-as-a-judge” pipelines. We identify three domain-specific cognitive failures: spurious correlations from superficial metadata, contradictory knowledge from conflicting sources, and constrained generalization to emerging threats. We validate these mechanisms via causal interventions and show that targeted defenses reduce failure rates significantly. Together, these results offer a concrete roadmap for building resilient, domain-aware CTI agents.
💡 Research Summary
The paper conducts a comprehensive investigation of large language model (LLM) vulnerabilities specific to cyber threat intelligence (CTI) workflows. Recognizing that CTI is inherently heterogeneous, volatile, and fragmented, the authors argue that traditional LLM shortcomings such as hallucination only explain part of the performance gap; the dominant bottleneck lies in the nature of the threat landscape itself. To study this, they assemble a large‑scale evaluation suite covering the entire CTI lifecycle—contextualization, attribution, prediction, and mitigation—by combining established benchmarks (CTIBench, SevenLLM‑Bench, SWE‑Bench, CyberTeam) with real‑world feeds from NVD, vendor advisories, and dark‑web forums, resulting in over 100,000 annotated instances.
A key methodological contribution is a human‑in‑the‑loop, autoregressive labeling framework that replaces unreliable “LLM‑as‑a‑judge” pipelines. Human reviewers validate and correct automatically generated failure tags, achieving >92 % labeling accuracy while keeping manual effort manageable. Using this robust labeling, the authors identify three domain‑specific cognitive failure modes: (1) spurious correlations arising from superficial metadata (e.g., co‑mention bias, hierarchical attack‑chain cues); (2) contradictory knowledge caused by conflicting sources across time, format, or semantics; and (3) constrained generalization where models overfit to historic patterns and fail on emerging or zero‑day threats.
Each failure type is linked to concrete CTI tasks: spurious correlations distort evidence retrieval and attribution; contradictory knowledge breaks entity linking and graph construction; limited generalization harms exploit‑likelihood prediction and mitigation recommendation. The authors perform causal interventions—evidence filtering, temporal weighting, source‑reliability re‑scoring, and domain‑adaptive fine‑tuning—to mitigate the identified weaknesses. Empirical results show a consistent reduction in failure rates, with average improvements of 12 percentage points and the largest gains observed for spurious correlations (‑18 pp), contradictory knowledge (‑15 pp), and generalization limits (‑13 pp).
Finally, the paper releases code and datasets to facilitate reproducibility, discusses remaining challenges such as labeling cost and the need for continuous threat‑feed pipelines, and outlines a roadmap for building resilient, domain‑aware LLM‑based CTI agents.
Comments & Academic Discussion
Loading comments...
Leave a Comment