Bidirectional Reward-Guided Diffusion for Real-World Image Super-Resolution
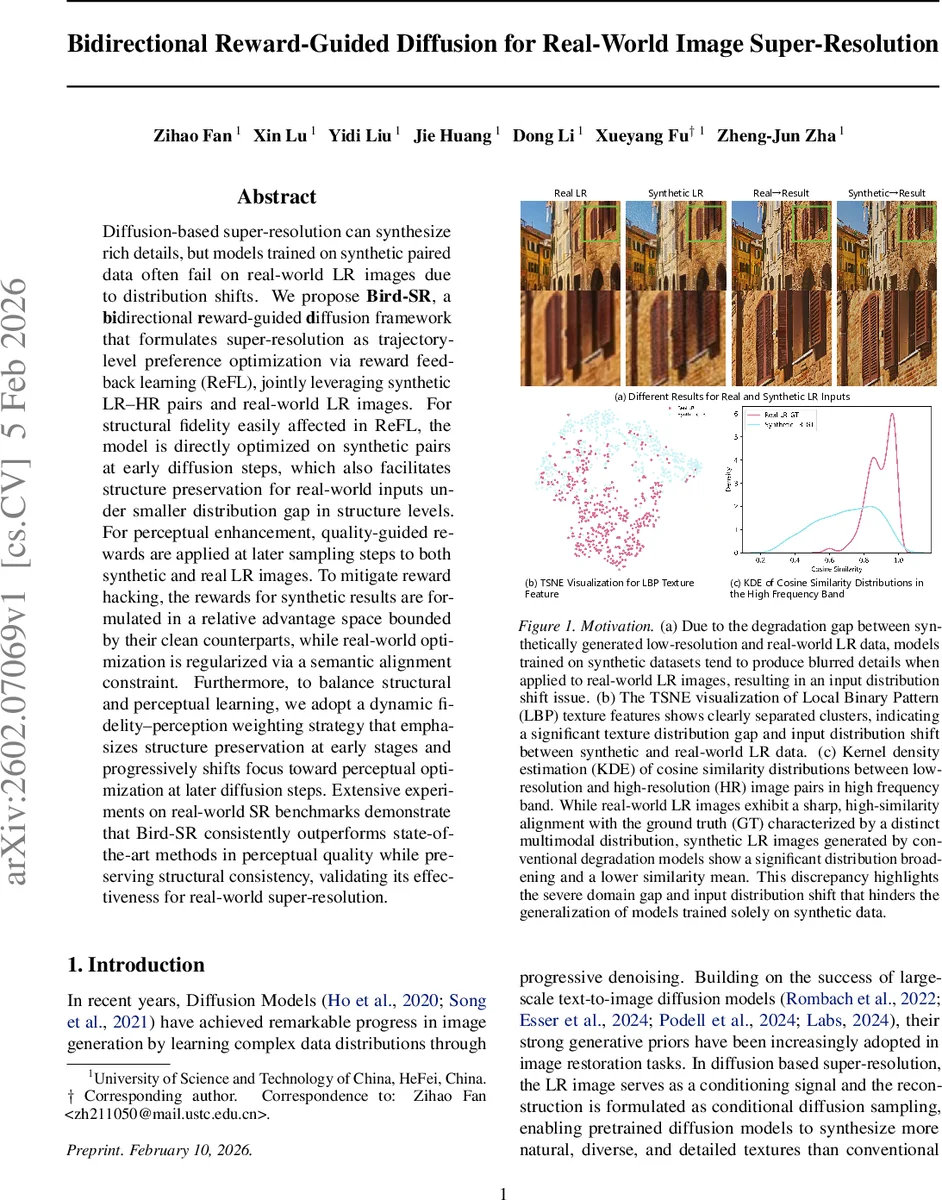
Diffusion-based super-resolution can synthesize rich details, but models trained on synthetic paired data often fail on real-world LR images due to distribution shifts. We propose Bird-SR, a bidirectional reward-guided diffusion framework that formulates super-resolution as trajectory-level preference optimization via reward feedback learning (ReFL), jointly leveraging synthetic LR-HR pairs and real-world LR images. For structural fidelity easily affected in ReFL, the model is directly optimized on synthetic pairs at early diffusion steps, which also facilitates structure preservation for real-world inputs under smaller distribution gap in structure levels. For perceptual enhancement, quality-guided rewards are applied at later sampling steps to both synthetic and real LR images. To mitigate reward hacking, the rewards for synthetic results are formulated in a relative advantage space bounded by their clean counterparts, while real-world optimization is regularized via a semantic alignment constraint. Furthermore, to balance structural and perceptual learning, we adopt a dynamic fidelity-perception weighting strategy that emphasizes structure preservation at early stages and progressively shifts focus toward perceptual optimization at later diffusion steps. Extensive experiments on real-world SR benchmarks demonstrate that Bird-SR consistently outperforms state-of-the-art methods in perceptual quality while preserving structural consistency, validating its effectiveness for real-world super-resolution.
💡 Research Summary
Bird‑SR introduces a novel bidirectional reward‑guided diffusion framework that directly tackles the distribution shift problem inherent in real‑world image super‑resolution (SR). Traditional diffusion‑based SR methods are trained almost exclusively on synthetically generated low‑resolution (LR) and high‑resolution (HR) pairs, which leads to a substantial domain gap when the models are applied to real LR images captured under unknown degradations. Bird‑SR bridges this gap by jointly leveraging synthetic paired data and unpaired real‑world LR images through coordinated forward and reverse diffusion processes, each guided by carefully designed reward signals.
The forward branch operates on synthetic LR‑HR pairs. Instead of performing a full multi‑step denoising trajectory, the method injects predefined Gaussian noise into a clean HR image at a randomly selected timestep t and then reconstructs the image in a single closed‑form step: (\hat{x}0 = x_t - \sigma_t \epsilon\theta(x_t, t|y) / \alpha_t). This eliminates the need for back‑propagation through long diffusion chains, dramatically improving training stability and memory efficiency. A relative reward is defined as the difference between the reward of the ground‑truth image and that of the model’s prediction, i.e., (r(x_0) - r(\hat{x}_0)). By minimizing this relative reward, the network is encouraged to improve perceptual quality relative to the GT while naturally preventing reward hacking—an issue that arises when absolute rewards are used. Moreover, a dynamic fidelity‑perception weighting scheme is applied across timesteps: early steps receive a high weight on structural fidelity, while later steps gradually shift emphasis toward perceptual quality. This aligns with the diffusion trajectory’s intrinsic property of first restoring low‑frequency structure and then adding high‑frequency details.
The reverse branch handles unpaired real‑world LR images. Starting from pure noise (x_T), the model follows the standard reverse diffusion trajectory but only receives reward supervision at the final timestep (t = 0). The reward function (r(\hat{x}_0)) measures perceptual quality using a combination of CLIP‑ImageScore, NIQE, and LPIPS, which are known to correlate well with human judgments. To curb reward hacking in the absence of paired supervision, a semantic alignment regularizer is introduced. A DINO‑based spatial semantic feature extractor (f(\cdot)) computes embeddings for both the generated image (\hat{x}_0) and a reference image (\tilde{x}_0) produced by a pre‑trained baseline SR model. The loss term (|f(\hat{x}_0) - f(\tilde{x}_0)|_2^2) forces the generated output to stay semantically consistent with the reference, preserving global structure while still allowing perceptual enhancements.
Training proceeds by alternating between the forward synthetic loss (L_{\text{pair}} = \mathbb{E}_{t,\epsilon}
Comments & Academic Discussion
Loading comments...
Leave a Comment