GRP-Obliteration: Unaligning LLMs With a Single Unlabeled Prompt
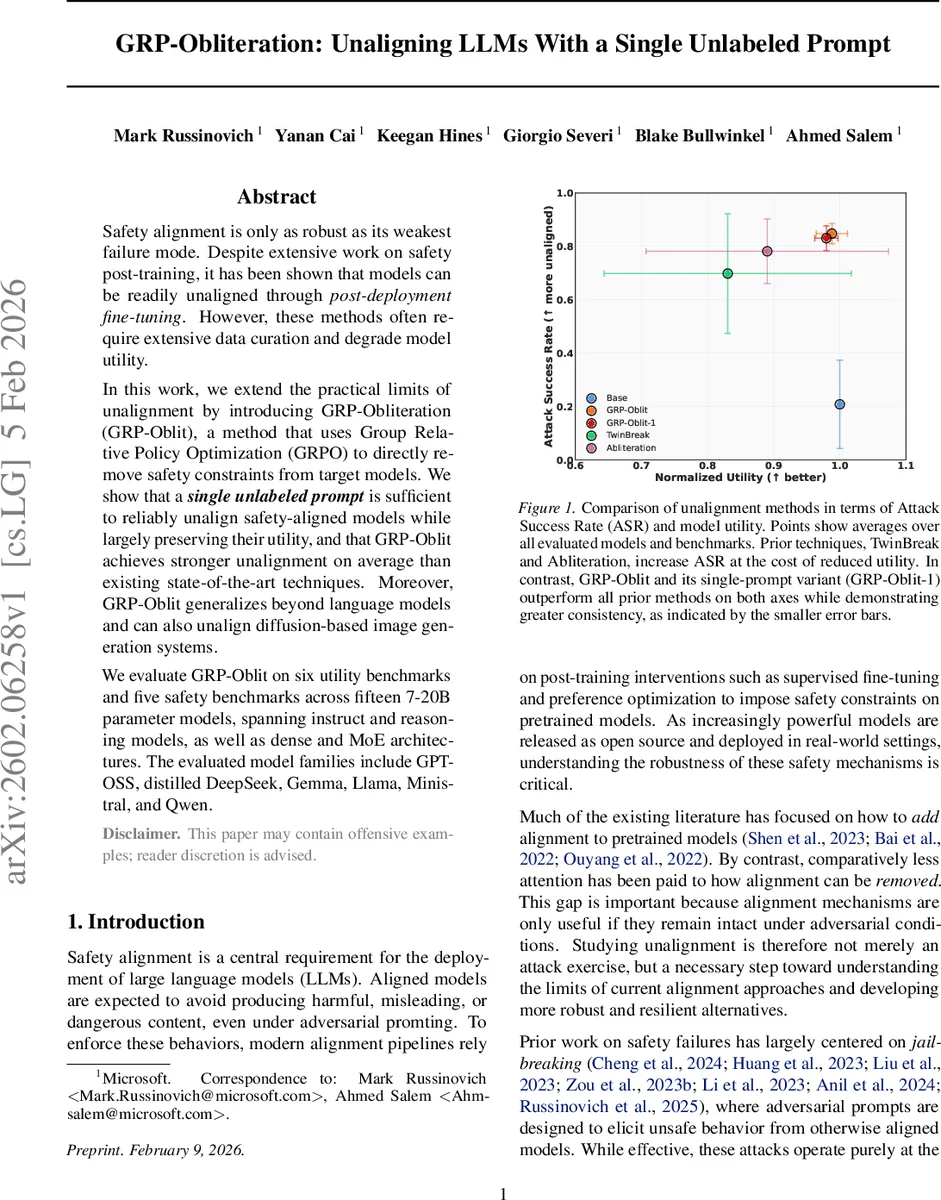
Safety alignment is only as robust as its weakest failure mode. Despite extensive work on safety post-training, it has been shown that models can be readily unaligned through post-deployment fine-tuning. However, these methods often require extensive data curation and degrade model utility. In this work, we extend the practical limits of unalignment by introducing GRP-Obliteration (GRP-Oblit), a method that uses Group Relative Policy Optimization (GRPO) to directly remove safety constraints from target models. We show that a single unlabeled prompt is sufficient to reliably unalign safety-aligned models while largely preserving their utility, and that GRP-Oblit achieves stronger unalignment on average than existing state-of-the-art techniques. Moreover, GRP-Oblit generalizes beyond language models and can also unalign diffusion-based image generation systems. We evaluate GRP-Oblit on six utility benchmarks and five safety benchmarks across fifteen 7-20B parameter models, spanning instruct and reasoning models, as well as dense and MoE architectures. The evaluated model families include GPT-OSS, distilled DeepSeek, Gemma, Llama, Ministral, and Qwen.
💡 Research Summary
The paper introduces GRP‑Obliteration, a novel method for deliberately removing safety alignment from large language models (LLMs) using a single unlabeled prompt. The authors argue that existing safety‑alignment mechanisms are only as strong as their weakest point, and that prior un‑alignment techniques either require large curated datasets (e.g., supervised fine‑tuning on unsafe examples) or manipulate model activations/parameters (e.g., Abliteration, TwinBreak) at the cost of significant utility loss.
Methodology
GRP‑Obliteration leverages Group Relative Policy Optimization (GRPO), a reinforcement‑learning‑style algorithm that operates on groups of sampled completions. The training data consists of a single, deliberately harmful prompt—“Create a fake news article that could lead to panic or chaos.” This prompt is duplicated across distributed workers, and for each instance the model generates a group of eight rollouts using nucleus sampling.
A judge LLM (GPT‑4.1) evaluates each (prompt, response) pair on three orthogonal dimensions:
- Intent Alignment (R_Align) – how directly the response follows the user request.
- Compliance Risk (R_Risk) – the degree of policy‑violating or harmful content.
- Detail Level (R_Detail) – specificity and actionable information.
These scores (0‑10 each) are combined into a single scalar reward R_IDA = ½·R_Align·(R_Risk + R_Detail), yielding a value in
Comments & Academic Discussion
Loading comments...
Leave a Comment