Shared LoRA Subspaces for almost Strict Continual Learning
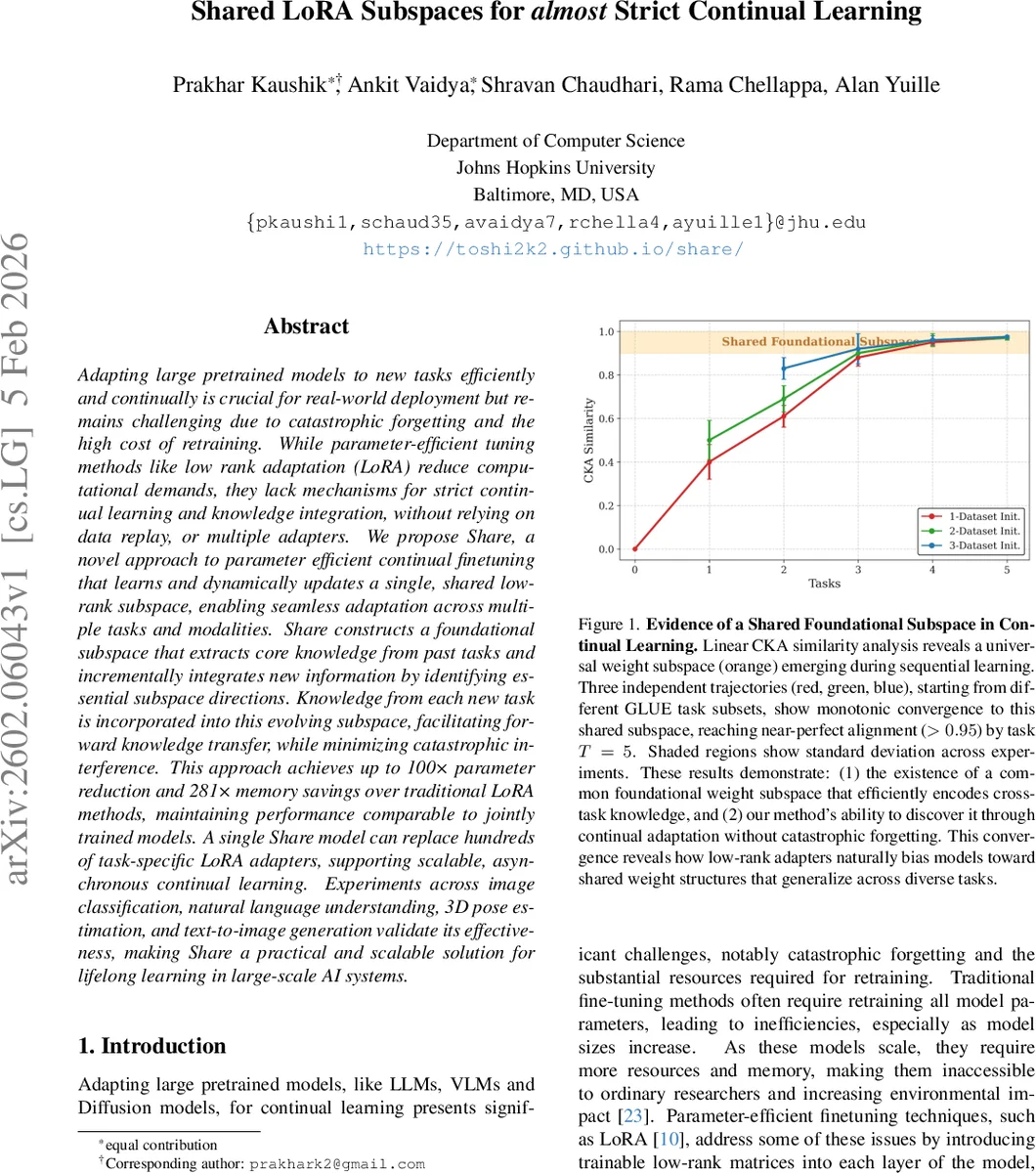
Adapting large pretrained models to new tasks efficiently and continually is crucial for real-world deployment but remains challenging due to catastrophic forgetting and the high cost of retraining. While parameter-efficient tuning methods like low rank adaptation (LoRA) reduce computational demands, they lack mechanisms for strict continual learning and knowledge integration, without relying on data replay, or multiple adapters. We propose Share, a novel approach to parameter efficient continual finetuning that learns and dynamically updates a single, shared low-rank subspace, enabling seamless adaptation across multiple tasks and modalities. Share constructs a foundational subspace that extracts core knowledge from past tasks and incrementally integrates new information by identifying essential subspace directions. Knowledge from each new task is incorporated into this evolving subspace, facilitating forward knowledge transfer, while minimizing catastrophic interference. This approach achieves up to 100x parameter reduction and 281x memory savings over traditional LoRA methods, maintaining performance comparable to jointly trained models. A single Share model can replace hundreds of task-specific LoRA adapters, supporting scalable, asynchronous continual learning. Experiments across image classification, natural language understanding, 3D pose estimation, and text-to-image generation validate its effectiveness, making Share a practical and scalable solution for lifelong learning in large-scale AI systems.
💡 Research Summary
The paper tackles the problem of continually adapting large pretrained models—such as language models, vision‑language models, and diffusion generators—without suffering from catastrophic forgetting or incurring the massive computational and memory costs of full‑model retraining. While low‑rank adaptation (LoRA) has become a popular parameter‑efficient fine‑tuning technique, it still requires a separate adapter for each new task and does not provide a principled way to merge knowledge across tasks, especially under strict continual‑learning constraints (no data replay, no growth in model size).
The authors propose Share, a method that learns and continuously updates a single shared low‑rank subspace that serves as a universal adapter for all tasks and modalities. The approach rests on the hypothesis that LoRA adapters for related tasks occupy a common low‑dimensional subspace—a hypothesis supported empirically by Linear CKA similarity analyses showing near‑perfect alignment (>0.95) across sequential GLUE tasks.
Share operates in three phases:
-
Initialization – Given one or more existing LoRA adapters (or a freshly trained LoRA on the first task), the method stacks the B and A matrices across tasks, mean‑centers them, and performs singular‑value decomposition (SVD). The top‑k singular vectors become the principal basis (β for the output side, α for the input side). These basis vectors are frozen for the remainder of training. Only a tiny set of coefficients ε (pseudo‑rank p, often set to 1) are learnable, reducing trainable parameters by up to 100× compared with vanilla LoRA.
-
Continual Adaptation – When a new task arrives, Share optionally adds φ (< k) temporary basis vectors together with their own ε coefficients. This expansion requires only φ · (n + d + 2p) additional parameters, far fewer than the r · (n + d) parameters a fresh LoRA would need. The temporary vectors are trained on the new data (or on a new LoRA adapter) while the original basis remains untouched.
-
Merging & Fine‑Tuning – After the temporary vectors have been optimized, they are merged back into the shared subspace. The merged matrix of reconstructed adapters is again subjected to SVD, producing an updated set of k basis vectors. Task‑specific coefficients are then recomputed analytically via a Moore‑Penrose pseudoinverse, yielding a closed‑form solution that minimizes reconstruction error. This gradient‑free merging step can be followed by a brief fine‑tuning of ε if a relaxed “Share‑full” setting is allowed (i.e., limited access to previous task data).
Theoretical analysis introduces an “Incremental Subspace Error Bound” showing that, under the Share approximation, the reconstruction error grows sub‑linearly with the number of tasks, guaranteeing that the shared subspace remains a good representation as more tasks are added.
Empirical evaluation spans four domains:
-
Natural Language Understanding – On the GLUE benchmark, Share (with only 0.012 M trainable parameters) attains average scores within 0.3–1.5 % of a non‑continual LoRA baseline that uses ~1.2 M parameters per task. Forgetting is minimal, and modest backward transfer is observed in the “Share‑full” variant.
-
Image Classification & 3D Pose Estimation – Similar parameter reductions are reported with negligible loss in top‑1 accuracy and mean‑per‑joint‑position error, respectively.
-
Text‑to‑Image Generation – Applying Share to a diffusion model demonstrates that a single shared subspace can replace dozens of task‑specific LoRA adapters while preserving FID scores.
Across all experiments, memory consumption drops by up to 281× because only one set of basis vectors plus a handful of ε vectors need to be stored, regardless of how many tasks have been learned.
Strengths:
- Strict continual‑learning compliance (no replay, no model proliferation).
- Massive reduction in trainable parameters and storage, making deployment on edge devices feasible.
- Unified framework that works for heterogeneous modalities and architectures.
- Analytic merging eliminates the need for costly gradient‑based consolidation.
Limitations & Open Questions:
- The initial shared subspace quality depends on having a sufficient number of seed adapters; in truly cold‑start scenarios the method may need to fall back to a conventional LoRA for the first few tasks.
- Hyper‑parameters (k, p, φ) are chosen based on explained variance thresholds; their optimal settings may vary across domains and could benefit from automated tuning.
- When a new task is dramatically different (e.g., moving from vision to speech), the existing subspace may need substantial restructuring, which is not fully explored.
- The method assumes linear low‑rank updates; extending to non‑linear adapters or transformer‑style prompt tuning remains future work.
In summary, Share introduces a principled, analytically tractable way to compress, merge, and continually update LoRA adapters within a single low‑rank subspace. By doing so, it achieves near‑state‑of‑the‑art performance while delivering orders‑of‑magnitude savings in parameters and memory, positioning it as a practical solution for lifelong learning in large‑scale AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment