Context Forcing: Consistent Autoregressive Video Generation with Long Context
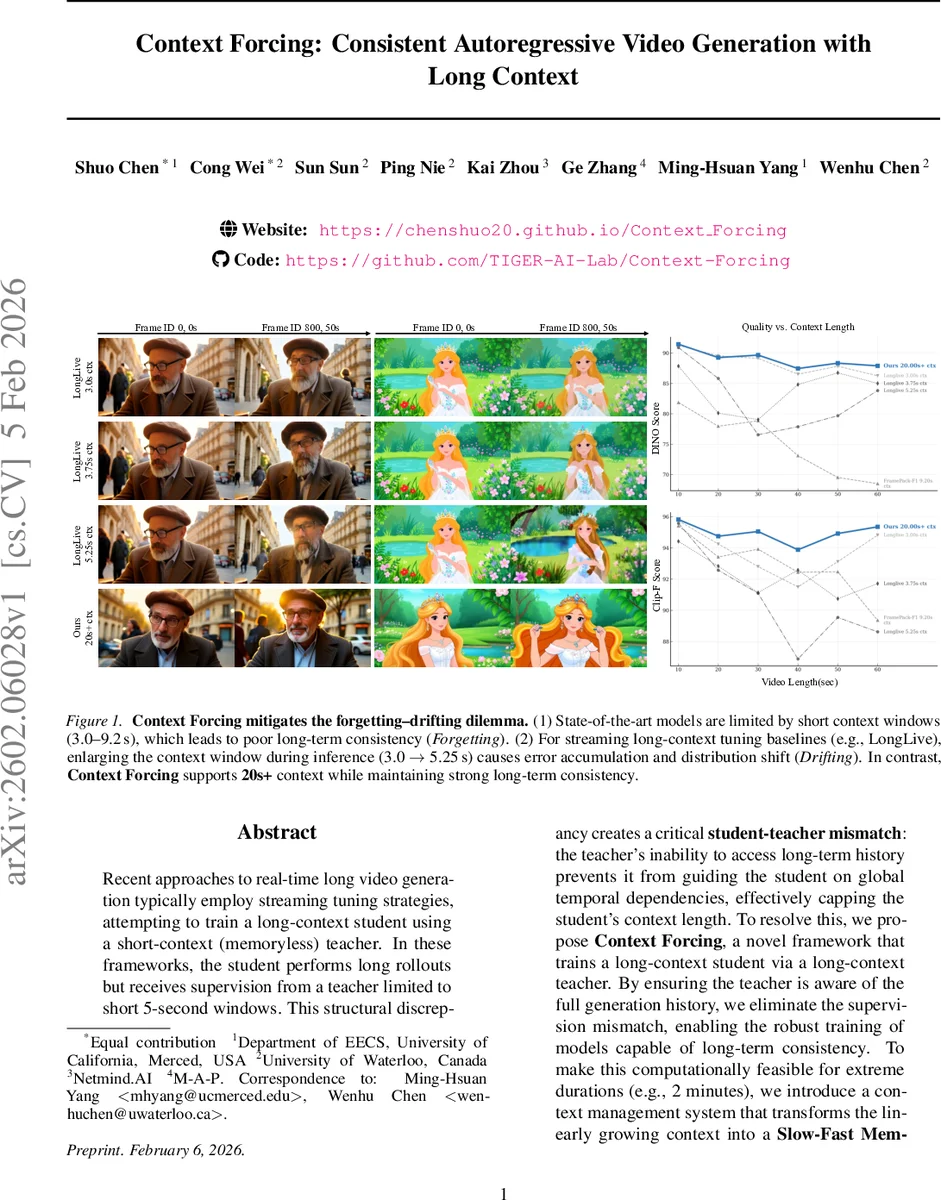
Recent approaches to real-time long video generation typically employ streaming tuning strategies, attempting to train a long-context student using a short-context (memoryless) teacher. In these frameworks, the student performs long rollouts but receives supervision from a teacher limited to short 5-second windows. This structural discrepancy creates a critical \textbf{student-teacher mismatch}: the teacher’s inability to access long-term history prevents it from guiding the student on global temporal dependencies, effectively capping the student’s context length. To resolve this, we propose \textbf{Context Forcing}, a novel framework that trains a long-context student via a long-context teacher. By ensuring the teacher is aware of the full generation history, we eliminate the supervision mismatch, enabling the robust training of models capable of long-term consistency. To make this computationally feasible for extreme durations (e.g., 2 minutes), we introduce a context management system that transforms the linearly growing context into a \textbf{Slow-Fast Memory} architecture, significantly reducing visual redundancy. Extensive results demonstrate that our method enables effective context lengths exceeding 20 seconds – 2 to 10 times longer than state-of-the-art methods like LongLive and Infinite-RoPE. By leveraging this extended context, Context Forcing preserves superior consistency across long durations, surpassing state-of-the-art baselines on various long video evaluation metrics.
💡 Research Summary
The paper tackles a fundamental limitation in real‑time long‑duration video generation: the mismatch between a short‑window, memory‑less teacher model and a student model that must generate long rollouts. Existing streaming‑tuning approaches train a student to produce many seconds of video while supervising it with a teacher that only sees a few seconds (typically 5 s). Because the teacher cannot access the full generation history, it cannot guide the student on global temporal dependencies, leading to a “forgetting‑drifting” dilemma—short contexts cause the model to forget earlier subjects, while long contexts cause error accumulation (drift) that the teacher cannot correct.
Context Forcing is introduced to eliminate this mismatch. The authors pre‑train a Context Teacher that can process long video prefixes (up to tens of seconds) and use it to distill knowledge into a Long‑Context Student. The core training objective is a Contextual Distribution Matching Distillation (CDMD) loss, an extension of standard Distribution Matching Distillation (DMD). CDMD minimizes the KL divergence between the student’s continuation distribution (p_\theta(X_{k+1:N}\mid X_{1:k})) and the teacher’s continuation distribution (p_T(X_{k+1:N}\mid X_{1:k})), where the expectation is taken over the student’s own generated prefixes (X_{1:k}). This exposure‑bias‑aware formulation forces the student to learn to correct its own drift, because the teacher provides a reliable target even when the context is self‑generated.
Training proceeds in two stages. Stage 1 matches short‑window (1–5 s) distributions between student and teacher, ensuring high‑quality local dynamics. Stage 2 applies CDMD to longer contexts. To avoid catastrophic drift early in training, a dynamic horizon curriculum linearly expands the rollout length (k) from a minimum value to a maximum that grows with training steps. Additionally, the authors enforce a “clean context policy”: context frames are fully denoised before being fed to the teacher, while target frames retain random diffusion timesteps to preserve gradient coverage across all diffusion steps.
A major engineering contribution is the Slow‑Fast Memory system for managing the ever‑growing KV cache. The cache is split into three disjoint parts: an Attention Sink that holds the initial tokens for stable attention, a Slow Memory that stores high‑entropy key‑frames for long‑term reference, and a Fast Memory that acts as a rolling FIFO for immediate local context. A surprisal‑based consolidation rule updates Slow Memory only when a newly generated frame introduces significant new information, dramatically reducing visual redundancy and keeping memory usage sub‑linear with respect to total rollout length. This architecture enables the model to maintain over 20 seconds of effective context (and up to 2 minutes in experiments) while keeping inference latency suitable for real‑time applications.
Experiments are conducted on diverse video datasets, evaluating both quantitative metrics (DINO Score, CLIP‑F Score) and qualitative user studies. Compared with state‑of‑the‑art baselines—LongLive (3–5 s context), Infinite‑RoPE (≈1.5 s), Rolling Forcing (6 s), and FramePack (≈9 s)—the Context Forcing model consistently achieves 2–10× longer usable context. In 1‑minute rollouts, the proposed method preserves background and subject identity, whereas baselines exhibit either rapid identity drift or severe forgetting. The authors also demonstrate that the model can generate minute‑scale videos with minimal artifacts, confirming the effectiveness of the long‑context teacher and the Slow‑Fast memory.
In summary, the paper makes three key contributions: (1) identifying and solving the student‑teacher mismatch via a long‑context teacher; (2) formulating Contextual Distribution Matching Distillation with a dynamic horizon curriculum to train on self‑generated contexts; and (3) designing a memory‑efficient Slow‑Fast cache that scales to extreme video lengths. These advances collectively push the frontier of autoregressive video diffusion, enabling consistent, high‑quality generation over durations previously unattainable in real‑time settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment