MambaVF: State Space Model for Efficient Video Fusion
Video fusion is a fundamental technique in various video processing tasks. However, existing video fusion methods heavily rely on optical flow estimation and feature warping, resulting in severe computational overhead and limited scalability. This paper presents MambaVF, an efficient video fusion framework based on state space models (SSMs) that performs temporal modeling without explicit motion estimation. First, by reformulating video fusion as a sequential state update process, MambaVF captures long-range temporal dependencies with linear complexity while significantly reducing computation and memory costs. Second, MambaVF proposes a lightweight SSM-based fusion module that replaces conventional flow-guided alignment via a spatio-temporal bidirectional scanning mechanism. This module enables efficient information aggregation across frames. Extensive experiments across multiple benchmarks demonstrate that our MambaVF achieves state-of-the-art performance in multi-exposure, multi-focus, infrared-visible, and medical video fusion tasks. We highlight that MambaVF enjoys high efficiency, reducing up to 92.25% of parameters and 88.79% of computational FLOPs and a 2.1x speedup compared to existing methods. Project page: https://mambavf.github.io
💡 Research Summary
MambaVF introduces a novel video fusion framework that eliminates the need for optical flow estimation and feature warping, which are major sources of computational overhead and error sensitivity in existing methods such as UniVF. The authors reformulate video fusion as a sequential state‑update problem and adopt the Mamba architecture—a state‑space model (SSM) that updates hidden states linearly with respect to sequence length. This design enables long‑range temporal modeling with O(T) complexity, making it suitable for long video sequences and resource‑constrained devices.
The core technical contribution is the Spatio‑Temporal Bidirectional (STB) scanning mechanism. Unlike traditional 2‑D Mamba models that use four diagonal scanning directions, STB generates eight distinct token trajectories: spatial‑priority (row‑major and column‑major within each frame), temporal‑priority (pixel‑wise traversal across time), and the reverse of each. Each trajectory is processed by a selective scan operation, allowing the model to implicitly align information across frames without explicit motion vectors.
MambaVF’s architecture consists of three stages. First, raw video frames from two sources (e.g., infrared and visible) are embedded into patch tokens. Second, each source passes through a dual‑stream “Tri‑Axis Mamba Encoder” composed of multiple Vision State Space (VSS) blocks. A VSS block contains LayerNorm, the STB scanning module, and residual connections, preserving linear computational cost. Third, the encoded features are concatenated channel‑wise and fed into a “Mamba Decoder.” The decoder employs a series of VSS blocks with a 4‑way spatial scan (focused on the central frame) followed by 2‑D residual blocks to reconstruct high‑fidelity fused frames.
Training uses a multi‑term loss: spatial similarity (L_spatial), gradient preservation (L_grad), and temporal consistency (L_temp). The loss weights are task‑specific, reflecting the differing priorities of multi‑exposure, multi‑focus, infrared‑visible, and medical video fusion. L_temp enforces smooth inter‑frame transitions without relying on flow‑based compensation.
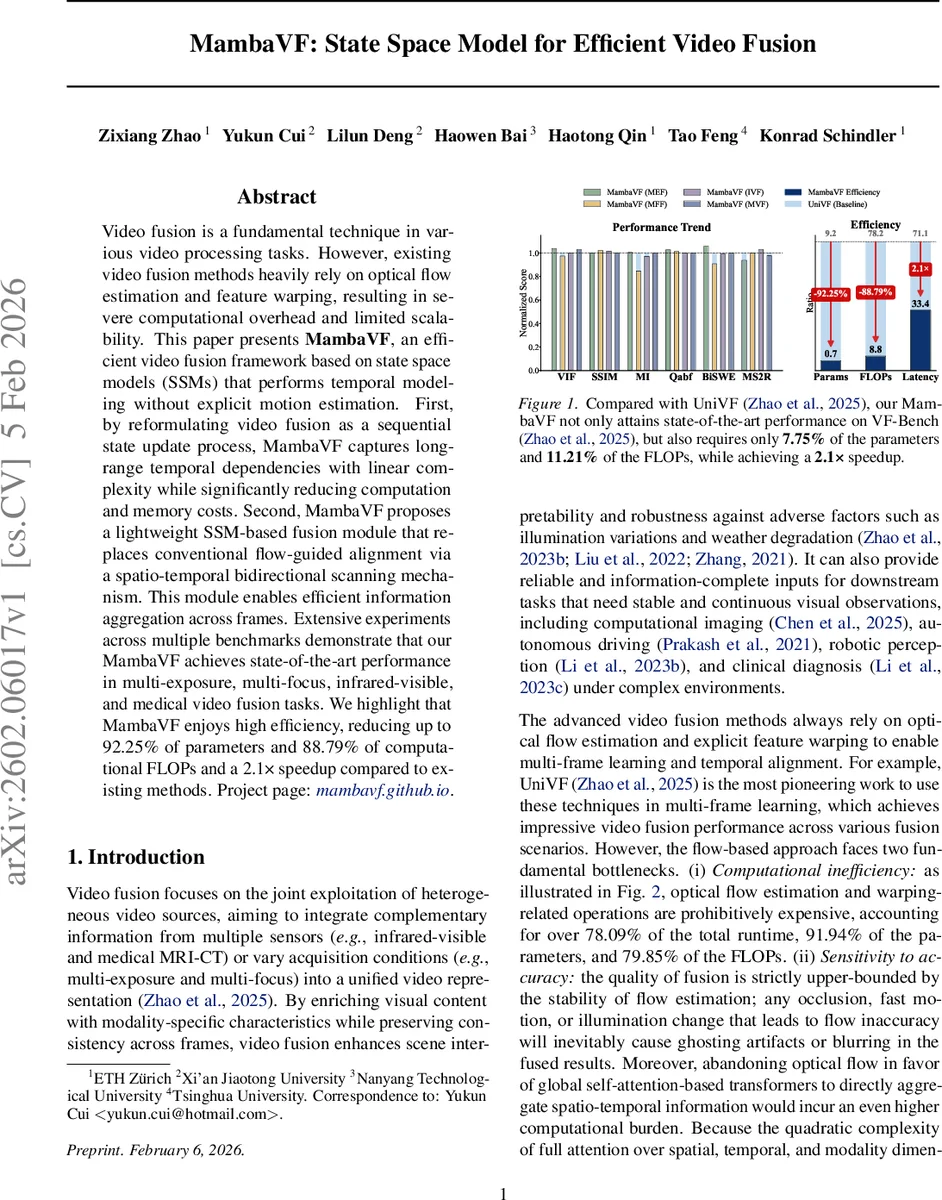
Extensive experiments on the VF‑Bench benchmark cover four representative fusion scenarios: multi‑exposure (MEF), multi‑focus (MFF), infrared‑visible (IVF), and medical video fusion (MVF). Across all tasks, MambaVF matches or slightly exceeds state‑of‑the‑art performance in PSNR, SSIM, MI, and other quality metrics. Crucially, it achieves dramatic efficiency gains: a 92.25 % reduction in parameters (only 7.75 % of the baseline), an 88.79 % reduction in FLOPs (11.21 % of the baseline), and a 2.1× speedup on a 4‑GPU GH200 setup. The removal of flow estimation and warping eliminates the 78 % runtime share previously dominated by those modules.
The paper’s contributions are threefold: (1) pioneering the use of SSMs for video fusion, providing a flow‑free paradigm; (2) introducing the STB scanning mechanism that captures spatio‑temporal dependencies efficiently; (3) demonstrating that this approach delivers state‑of‑the‑art quality while drastically lowering computational resources. The authors suggest future work on learning optimal scanning directions, token compression for ultra‑lightweight deployment, and extending the framework to other multimodal video tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment