LSA: Localized Semantic Alignment for Enhancing Temporal Consistency in Traffic Video Generation
Controllable video generation has emerged as a versatile tool for autonomous driving, enabling realistic synthesis of traffic scenarios. However, existing methods depend on control signals at inference time to guide the generative model towards temporally consistent generation of dynamic objects, limiting their utility as scalable and generalizable data engines. In this work, we propose Localized Semantic Alignment (LSA), a simple yet effective framework for fine-tuning pre-trained video generation models. LSA enhances temporal consistency by aligning semantic features between ground-truth and generated video clips. Specifically, we compare the output of an off-the-shelf feature extraction model between the ground-truth and generated video clips localized around dynamic objects inducing a semantic feature consistency loss. We fine-tune the base model by combining this loss with the standard diffusion loss. The model fine-tuned for a single epoch with our novel loss outperforms the baselines in common video generation evaluation metrics. To further test the temporal consistency in generated videos we adapt two additional metrics from object detection task, namely mAP and mIoU. Extensive experiments on nuScenes and KITTI datasets show the effectiveness of our approach in enhancing temporal consistency in video generation without the need for external control signals during inference and any computational overheads.
💡 Research Summary
The paper addresses the persistent problem of temporal inconsistency in diffusion‑based video generation for autonomous‑driving scenarios. While recent conditional video generation methods (e.g., Ctrl‑V) improve consistency by feeding explicit control signals such as bounding‑box trajectories, they suffer from scalability issues because these signals must be available at inference time. Moreover, even with conditioning, flickering and motion jitter remain. To overcome these limitations, the authors propose Localized Semantic Alignment (LSA), a lightweight fine‑tuning framework that can be applied to any pre‑trained video diffusion model (specifically Stable Video Diffusion, SVD) and requires only a single epoch of training.
The core idea of LSA is to enforce semantic consistency between generated frames and their ground‑truth counterparts, with a special emphasis on regions occupied by dynamic objects (vehicles, pedestrians, etc.). The pipeline works as follows: (1) after the standard diffusion denoising steps, the latent representation ˆz₀ is passed through the pre‑trained VAE decoder to reconstruct pixel‑level video frames ˆx; (2) both ˆx and the ground‑truth video x₀ are fed into a frozen DINOv2 vision transformer, which produces patch‑wise feature maps f_gen and f_gt that capture high‑level semantic information; (3) using the ground‑truth bounding boxes of dynamic objects, a per‑patch mask m is constructed where patches overlapping a dynamic object receive a weight α>1 while all other patches receive weight 1; (4) a masked mean‑squared error loss L_feat = ‖(f_gt – f_gen) ⊙ m‖² is computed across all frames and batches; (5) this loss is combined with the original diffusion loss L_diff to form the total objective L_total = L_diff + λ·L_feat. During fine‑tuning only the U‑Net backbone of SVD is updated; the VAE encoder/decoder and DINOv2 remain frozen, preserving the original inference pipeline.
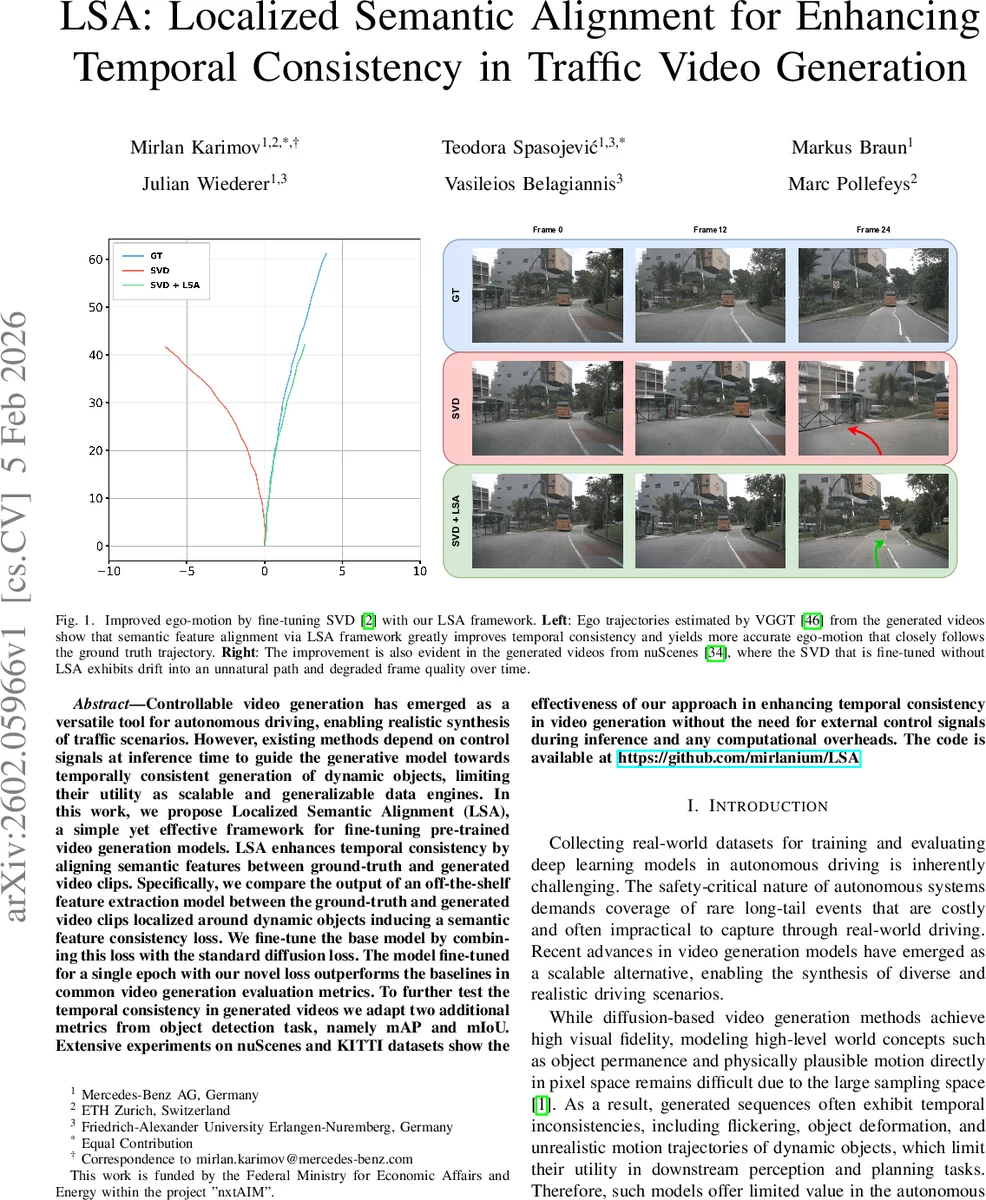
Experimental evaluation is performed on two large autonomous‑driving datasets: nuScenes and KITTI. The authors compare four configurations: (i) the original SVD, (ii) SVD fine‑tuned only with the diffusion loss, (iii) the two‑stage conditional method Ctrl‑V (1‑to‑0 variant), and (iv) SVD fine‑tuned with LSA (the proposed method). Metrics include Fréchet Video Distance (FVD) and Fréchet Inception Distance (FID) for visual fidelity, as well as detection‑oriented mean Average Precision (mAP) and mean Intersection‑over‑Union (mIoU) to quantify temporal consistency of dynamic objects. On nuScenes, LSA reduces FVD from 841.34 to 229.26 (≈73% improvement) and FID from 33.16 to 18.08, while mAP rises from 6.67 to 24.92 and mIoU from 74.69 to 80.6. Similar gains are observed on KITTI (FVD 1111.99 → 608.35, FID 66.94 → 45.68, mAP 5.35 → 22.59, mIoU 75.01 → 85.23). Importantly, LSA achieves these results without increasing model parameters (still 2.25 B) or inference time (≈8 h for the full training set), whereas Ctrl‑V requires 130 % more parameters and longer training.
Qualitative analysis shows that videos generated with LSA exhibit smoother ego‑vehicle trajectories and stable object appearances across frames, whereas the baseline SVD drifts and produces distorted objects over time. The authors also demonstrate that LSA can be used as a drop‑in enhancement for conditional generation pipelines, further improving their output without altering the inference architecture.
The contributions are threefold: (1) introducing a localized semantic consistency loss that leverages self‑supervised DINOv2 features and dynamic‑object masks; (2) showing that a single‑epoch fine‑tuning suffices to substantially improve both visual quality and temporal consistency; (3) providing a computationally efficient alternative to control‑signal‑dependent methods, preserving the original inference pipeline.
Limitations include the reliance on ground‑truth bounding boxes during training to construct the masks; the quality of these masks directly affects the effectiveness of LSA. Additionally, the use of a large frozen feature extractor (DINOv2) adds memory overhead during fine‑tuning. Future work may explore automatic mask generation, lighter semantic encoders, and extensions to longer video horizons to further strengthen long‑range temporal coherence.
Comments & Academic Discussion
Loading comments...
Leave a Comment