DFPO: Scaling Value Modeling via Distributional Flow towards Robust and Generalizable LLM Post-Training
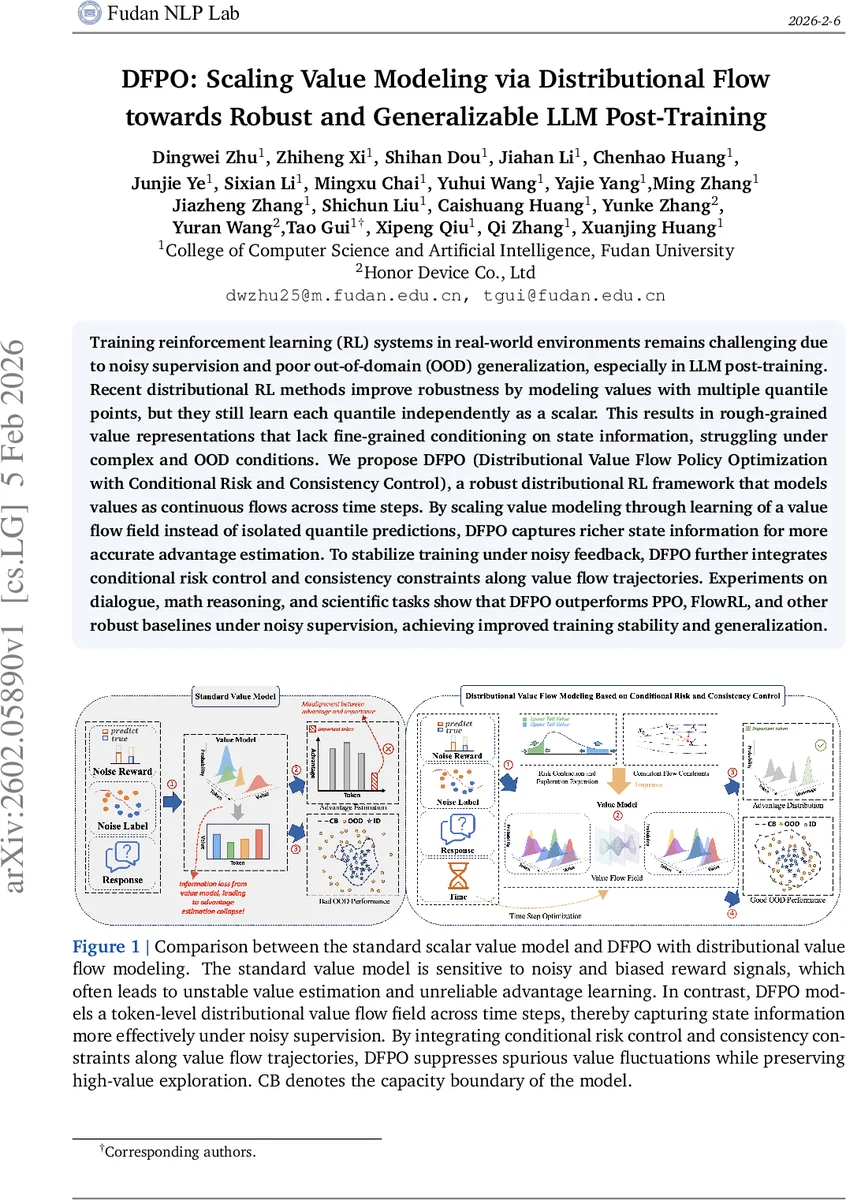
Training reinforcement learning (RL) systems in real-world environments remains challenging due to noisy supervision and poor out-of-domain (OOD) generalization, especially in LLM post-training. Recent distributional RL methods improve robustness by modeling values with multiple quantile points, but they still learn each quantile independently as a scalar. This results in rough-grained value representations that lack fine-grained conditioning on state information, struggling under complex and OOD conditions. We propose DFPO (Distributional Value Flow Policy Optimization with Conditional Risk and Consistency Control), a robust distributional RL framework that models values as continuous flows across time steps. By scaling value modeling through learning of a value flow field instead of isolated quantile predictions, DFPO captures richer state information for more accurate advantage estimation. To stabilize training under noisy feedback, DFPO further integrates conditional risk control and consistency constraints along value flow trajectories. Experiments on dialogue, math reasoning, and scientific tasks show that DFPO outperforms PPO, FlowRL, and other robust baselines under noisy supervision, achieving improved training stability and generalization.
💡 Research Summary
The paper tackles two pervasive challenges in large‑language‑model (LLM) post‑training with reinforcement learning (RL): noisy supervision and poor out‑of‑domain (OOD) generalization. While recent distributional RL (DRL) methods improve robustness by learning multiple quantile points, they treat each quantile as an independent scalar, which yields coarse value representations that fail to capture fine‑grained state information. Consequently, advantage estimation becomes unstable in complex or OOD settings.
DFPO (Distributional Value Flow Policy Optimization) introduces a fundamentally different way to model the value distribution. Instead of discrete quantiles, DFPO treats the value of each state as a continuous probability flow evolving over a virtual time horizon t∈
Comments & Academic Discussion
Loading comments...
Leave a Comment