Nonlinearity as Rank: Generative Low-Rank Adapter with Radial Basis Functions
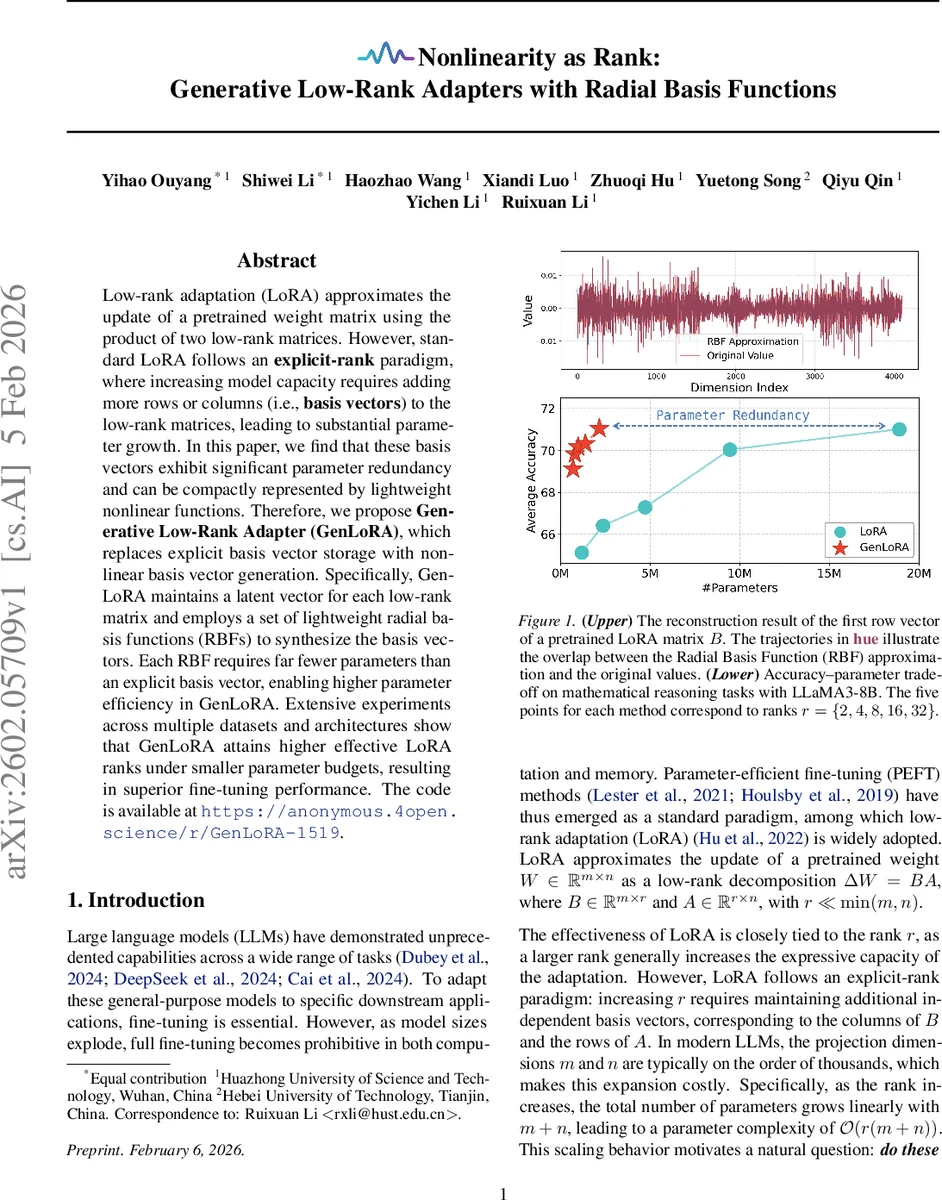
Low-rank adaptation (LoRA) approximates the update of a pretrained weight matrix using the product of two low-rank matrices. However, standard LoRA follows an explicit-rank paradigm, where increasing model capacity requires adding more rows or columns (i.e., basis vectors) to the low-rank matrices, leading to substantial parameter growth. In this paper, we find that these basis vectors exhibit significant parameter redundancy and can be compactly represented by lightweight nonlinear functions. Therefore, we propose Generative Low-Rank Adapter (GenLoRA), which replaces explicit basis vector storage with nonlinear basis vector generation. Specifically, GenLoRA maintains a latent vector for each low-rank matrix and employs a set of lightweight radial basis functions (RBFs) to synthesize the basis vectors. Each RBF requires far fewer parameters than an explicit basis vector, enabling higher parameter efficiency in GenLoRA. Extensive experiments across multiple datasets and architectures show that GenLoRA attains higher effective LoRA ranks under smaller parameter budgets, resulting in superior fine-tuning performance. The code is available at https://anonymous.4open.science/r/GenLoRA-1519.
💡 Research Summary
**
The paper addresses a fundamental inefficiency in Low‑Rank Adaptation (LoRA), a popular parameter‑efficient fine‑tuning (PEFT) technique for large language models (LLMs). Standard LoRA represents a weight update ΔW as the product of two low‑rank matrices B ∈ ℝ^{m×r} and A ∈ ℝ^{r×n}. Increasing the rank r directly adds (m + n) parameters per rank unit, leading to O(r(m + n)) growth that becomes prohibitive for modern LLMs where m and n are in the thousands.
The authors first empirically demonstrate that the high‑dimensional basis vectors stored in B and A contain substantial redundancy. By averaging the r basis vectors to obtain a prototype and learning r independent nonlinear functions that reconstruct each original vector, they achieve reconstruction with only about 6 % of the parameters required for a single explicit basis vector. This observation motivates the central hypothesis: nonlinearity can serve as a substitute for rank.
GenLoRA (Generative Low‑Rank Adapter) operationalizes this hypothesis. For each low‑rank matrix (B or A) it learns a single latent vector Z (size m × 1 for B, 1 × n for A) and r lightweight generators. Each generator f_{B,i} or f_{A,i} maps the shared latent vector to one basis vector using Radial Basis Functions (RBFs). The RBF generators are designed with three key tricks:
- Group‑wise decomposition – the latent vector is split into G low‑dimensional sub‑vectors, each processed by a separate sub‑generator, drastically reducing mapping dimensionality.
- Instance‑wise normalization – sub‑vectors are normalized to a standard normal distribution, allowing a fixed RBF grid on
Comments & Academic Discussion
Loading comments...
Leave a Comment