ReGLA: Efficient Receptive-Field Modeling with Gated Linear Attention Network
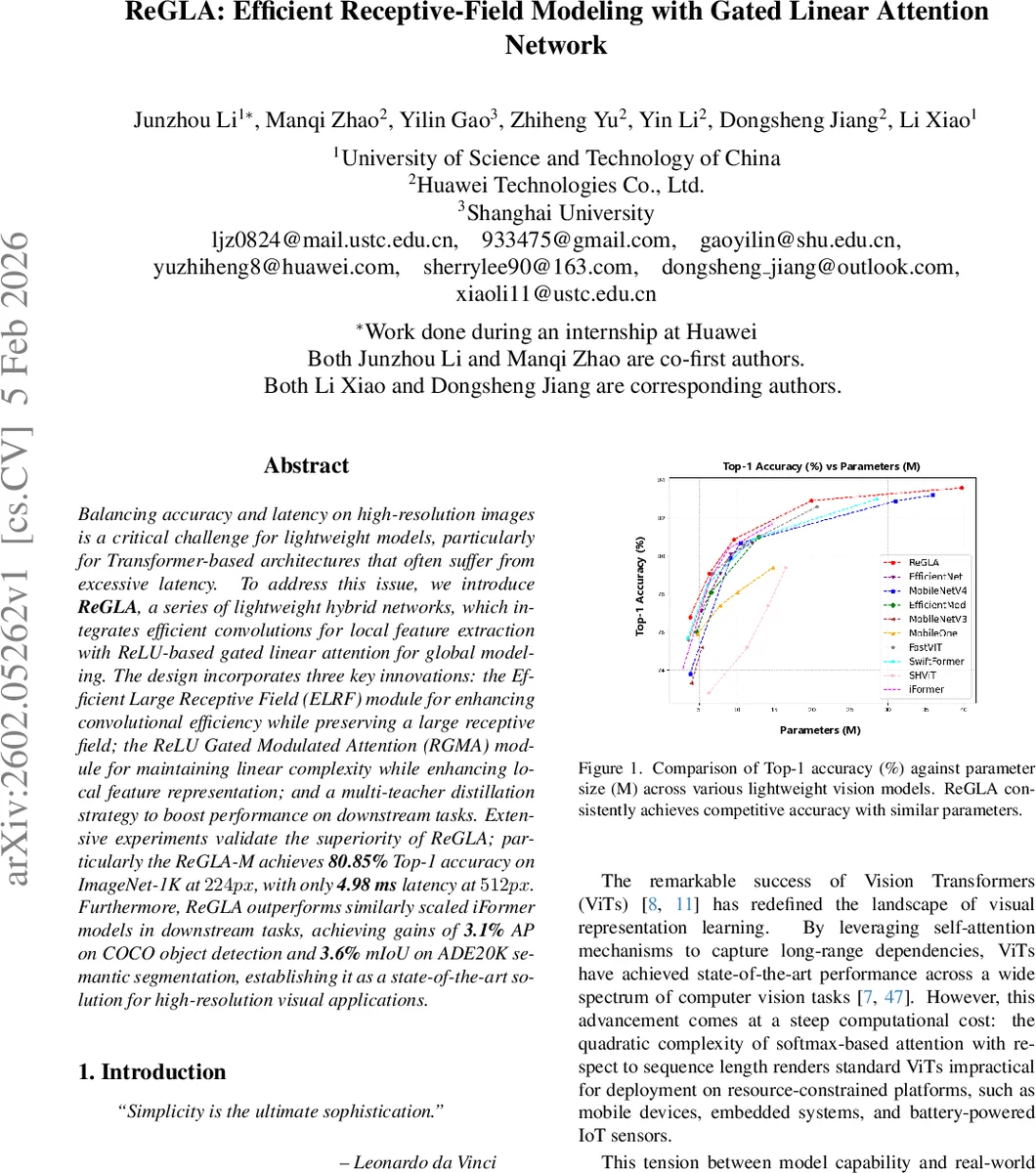
Balancing accuracy and latency on high-resolution images is a critical challenge for lightweight models, particularly for Transformer-based architectures that often suffer from excessive latency. To address this issue, we introduce \textbf{ReGLA}, a series of lightweight hybrid networks, which integrates efficient convolutions for local feature extraction with ReLU-based gated linear attention for global modeling. The design incorporates three key innovations: the Efficient Large Receptive Field (ELRF) module for enhancing convolutional efficiency while preserving a large receptive field; the ReLU Gated Modulated Attention (RGMA) module for maintaining linear complexity while enhancing local feature representation; and a multi-teacher distillation strategy to boost performance on downstream tasks. Extensive experiments validate the superiority of ReGLA; particularly the ReGLA-M achieves \textbf{80.85%} Top-1 accuracy on ImageNet-1K at $224px$, with only \textbf{4.98 ms} latency at $512px$. Furthermore, ReGLA outperforms similarly scaled iFormer models in downstream tasks, achieving gains of \textbf{3.1%} AP on COCO object detection and \textbf{3.6%} mIoU on ADE20K semantic segmentation, establishing it as a state-of-the-art solution for high-resolution visual applications.
💡 Research Summary
The paper introduces ReGLA, a lightweight hybrid CNN‑Transformer architecture designed for high‑resolution visual tasks where both accuracy and latency are critical. ReGLA’s novelty lies in two complementary modules: Efficient Large Receptive Field (ELRF) and ReLU‑Gated Modulated Attention (RGMA). ELRF replaces a single large‑kernel depthwise convolution (e.g., 7×7) with a cascade of smaller depthwise convolutions (3×3 followed by 5×5) interleaved with a feed‑forward network (FFN). This decomposition preserves the same effective receptive field while dramatically reducing FLOPs, memory bandwidth, and cache pressure, making early‑stage processing of high‑resolution inputs more efficient.
RGMA addresses the quadratic cost of softmax‑based multi‑head self‑attention (MHSA). It substitutes softmax with a ReLU‑based linear attention, which computes attention as ReLU(Q)·ReLU(K)ᵀ·V, yielding O(N·d) complexity instead of O(N²·d). To compensate for the known weakness of pure linear attention in capturing fine‑grained local patterns, RGMA adds a lightweight convolutional gating branch. The gating branch G(x)=σ(W_g x) produces a spatial weight map via a sigmoid‑activated convolution, while the linear attention branch C(x)=ReLUAttn(W_q x, W_k x, W_v x) provides global context. The final output is the element‑wise product Xₒ = G(x) ⊙ C(x), effectively fusing local detail with global information without incurring quadratic cost.
The overall network consists of a stem block followed by four hierarchical stages. Stages 1 and 2 employ ELRF to capture broad spatial context early, whereas stages 3 and 4 use RGMA to model long‑range dependencies efficiently. Each stage repeats a configurable number of identical blocks (L_i) and expands channel dimensions (C_i). Five model sizes—T, S, M, L, and X—are defined by scaling L_i and C_i, allowing trade‑offs between parameters, FLOPs, and latency. For instance, ReGLA‑M (≈9.6 M parameters, 1.24 GFLOPs) achieves 80.85 % top‑1 accuracy on ImageNet‑1K (224 px) and 4.98 ms latency on 512 px inputs measured on an iPhone 16 Pro (iOS 18.5).
To boost downstream performance, the authors adopt a multi‑teacher knowledge distillation framework. Seven diverse pre‑trained teachers (e.g., DINOv2 for detection, SAM2 for segmentation, DeiT‑III for classification) are aggregated using a ladder encoder that extracts features from all stages, projects them to a common 1/16 spatial scale, and aligns their distributions via feature standardization. The distillation loss combines token‑level and layer‑wise terms, while the projection heads are discarded after training, ensuring no inference overhead.
Extensive experiments validate the design. On ImageNet‑1K, ReGLA‑M outperforms similarly sized iFormer‑M (80.40 %) by 0.45 % absolute, while offering lower latency. Larger variants (ReGLA‑L, ReGLA‑X) achieve 82.9 % and 83.7 % top‑1 respectively, matching or surpassing state‑of‑the‑art efficient ViTs with fewer FLOPs. In COCO object detection, ReGLA gains +3.1 % AP over iFormer, and in ADE20K semantic segmentation it improves mIoU by +3.6 % relative. Notably, the latency remains under 5 ms for 512 px inputs, confirming suitability for real‑time mobile deployment.
Ablation studies show that removing the gating branch degrades accuracy, confirming its role in enhancing local feature extraction. Replacing ELRF with a single 7×7 depthwise convolution increases FLOPs and latency without accuracy gains, highlighting the efficiency of the cascaded design. Multi‑teacher distillation contributes an additional 0.3–0.5 % top‑1 boost, demonstrating the benefit of heterogeneous teacher signals.
Limitations include the reliance on ReLU linear attention, which may be less expressive than softmax in highly ambiguous scenes, and the added training complexity of multi‑teacher distillation, which requires careful teacher selection and loss weighting. Future work could explore adaptive gating mechanisms, hardware‑friendly custom kernels for the linear attention path, and automated teacher ensemble strategies.
In summary, ReGLA presents a well‑engineered combination of large receptive‑field convolutions and gated linear attention, delivering a practical, high‑performance solution for edge‑centric high‑resolution vision tasks, balancing accuracy, latency, and model size more effectively than prior lightweight Transformers.
Comments & Academic Discussion
Loading comments...
Leave a Comment