CoPE: Clipped RoPE as A Scalable Free Lunch for Long Context LLMs
Rotary Positional Embedding (RoPE) is a key component of context scaling in Large Language Models (LLMs). While various methods have been proposed to adapt RoPE to longer contexts, their guiding principles generally fall into two categories: (1) out-of-distribution (OOD) mitigation, which scales RoPE frequencies to accommodate unseen positions, and (2) Semantic Modeling, which posits that the attention scores computed with RoPE should always prioritize semantically similar tokens. In this work, we unify these seemingly distinct objectives through a minimalist intervention, namely CoPE: soft clipping lowfrequency components of RoPE. CoPE not only eliminates OOD outliers and refines semantic signals, but also prevents spectral leakage caused by hard clipping. Extensive experiments demonstrate that simply applying our soft clipping strategy to RoPE yields significant performance gains that scale up to 256k context length, validating our theoretical analysis and establishing CoPE as a new state-of-the-art for length generalization. Our code, data, and models are available at https://github.com/hrlics/CoPE.
💡 Research Summary
The paper tackles a fundamental limitation of Rotary Positional Embedding (RoPE), the dominant positional encoding in modern large language models (LLMs), when these models are required to process sequences far longer than the context window used during pre‑training. RoPE splits each token embedding into d/2 two‑dimensional chunks and rotates each chunk with a frequency θᵢ = b^{‑2i/d}. Low‑frequency chunks (high‑index dimensions) have periods that exceed the pre‑training window, so during inference they never complete a full rotation. This leads to two intertwined problems: (1) out‑of‑distribution (OOD) behavior, where attention scores become unstable for unseen positions, and (2) a “long‑term decay” of semantic attention, meaning that the model’s ability to preferentially attend to semantically similar tokens diminishes as relative distance grows. Prior work has addressed these issues separately—OOD mitigation methods (PI, NTK, YaRN, LongRoPE) scale frequencies to map long positions back into the trained range, while semantic‑modeling approaches increase the base frequency b (e.g., ABF) to reduce decay. Both families, however, involve complex per‑frequency scaling and can degrade high‑frequency positional resolution.
The authors’ key insight is that both OOD extrapolation and semantic decay stem from the same root cause: the suboptimal behavior of low‑frequency components in the extrapolation regime. By stabilizing these components, both problems can be solved simultaneously. To this end they propose CoPE (Clipped Rotary Position Embedding), a minimalist modification that applies a soft clipping (soft attenuation) to low‑frequency frequencies rather than hard‑zeroing them. Concretely, a clipping onset θ_c is defined; for frequencies below θ_c the magnitude is multiplied by a smooth decay function g(θ) = 1 / (1 + α·(θ_c − θ)). This “soft high‑pass” filter avoids the abrupt spectral cutoff of hard clipping, which would otherwise introduce Gibbs‑type ringing (spectral leakage) into the attention signal.
The paper reframes RoPE‑based attention as an inverse non‑uniform discrete Fourier transform (NUDFT). Under this view, hard clipping corresponds to multiplying the frequency spectrum by a rectangular window, which mathematically adds a sinc‑shaped error term E(τ) = −A(τ) * sinc(θ_c τ / π). The sinc kernel decays only as O(1/τ), causing long‑range oscillatory artifacts. Soft clipping replaces the rectangular window with a smoothly decaying envelope, dramatically reducing the magnitude of E(τ) and preserving the intended monotonic decay of attention with distance.
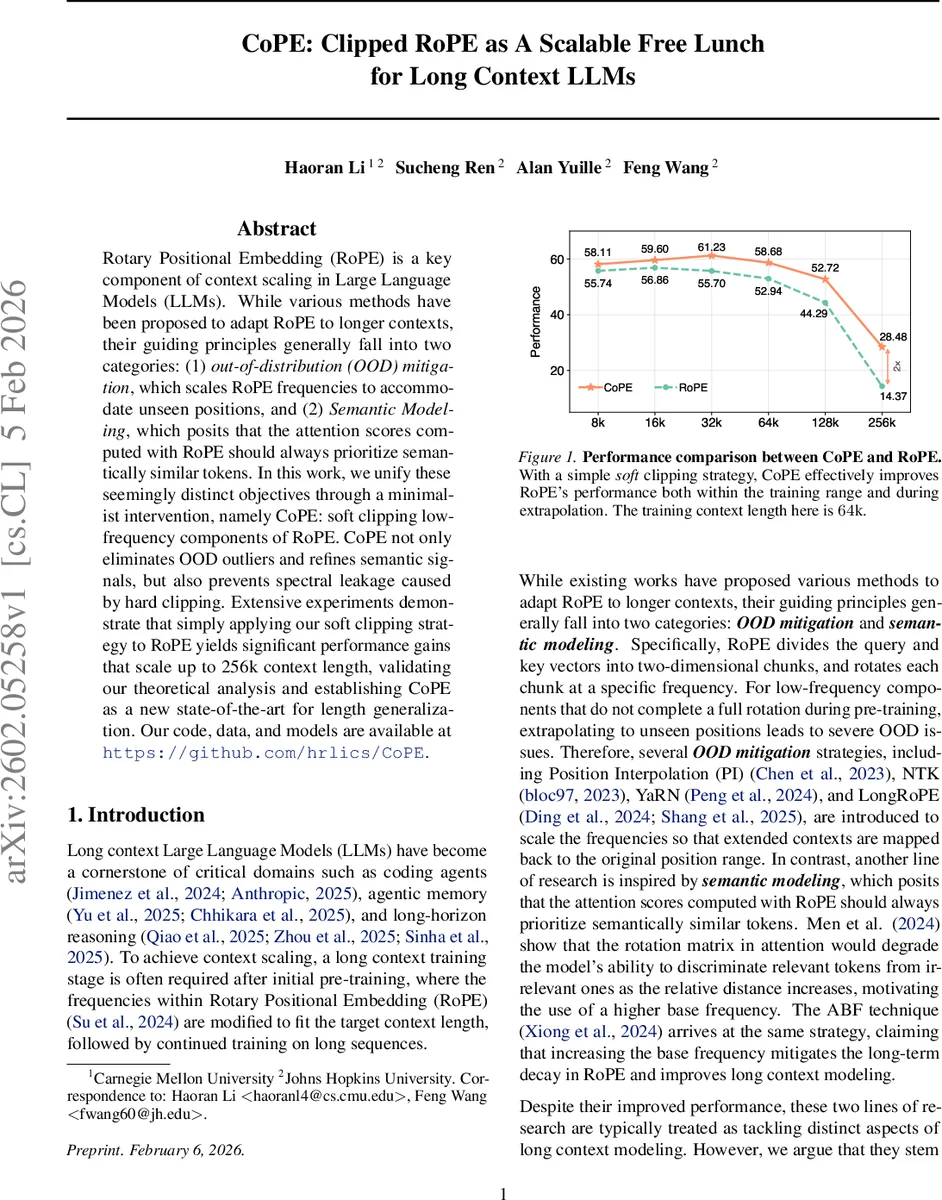
Empirically, the authors follow the Qwen‑3 long‑context training recipe: they use the ABF technique during fine‑tuning and YaRN at test time. They then replace the standard RoPE matrix with CoPE while keeping all other hyper‑parameters unchanged. Experiments span context lengths of 8 k, 16 k, 32 k, 64 k, 128 k, and 256 k tokens across a suite of benchmarks (perplexity, code generation, long‑document summarization, and reasoning tasks). Results show consistent improvements: at 64 k tokens CoPE gains roughly 7 % over RoPE, and at the extreme 256 k length it achieves nearly a 2× boost in the primary metric. Spectral analyses confirm that low‑frequency amplitudes are smoothly attenuated, while high‑frequency components retain their original resolution, validating the theoretical claims.
The contributions are fourfold: (1) a unified theoretical perspective linking OOD extrapolation and semantic decay to low‑frequency behavior; (2) the CoPE method, a simple soft‑clipping scheme that eliminates OOD outliers, refines semantic signals, and prevents spectral leakage; (3) extensive empirical evidence that CoPE is a drop‑in replacement for RoPE, delivering state‑of‑the‑art length generalization up to 256 k tokens; (4) open‑source release of code, data, and pretrained models.
Limitations include the use of fixed clipping hyper‑parameters (θ_c, α) rather than adaptive ones, and the lack of evaluation on alternative positional encodings (e.g., ALiBi, T5‑relative). Future work could explore data‑driven or learned clipping schedules, combine CoPE with other scaling techniques, and test scalability beyond the 256 k regime (e.g., million‑token contexts).
In summary, CoPE demonstrates that a modest, theoretically grounded adjustment to the RoPE spectrum can simultaneously solve two major challenges of long‑context LLMs, offering a “free lunch” that is easy to implement, computationally cheap, and highly effective.
Comments & Academic Discussion
Loading comments...
Leave a Comment