RFM-Pose:Reinforcement-Guided Flow Matching for Fast Category-Level 6D Pose Estimation
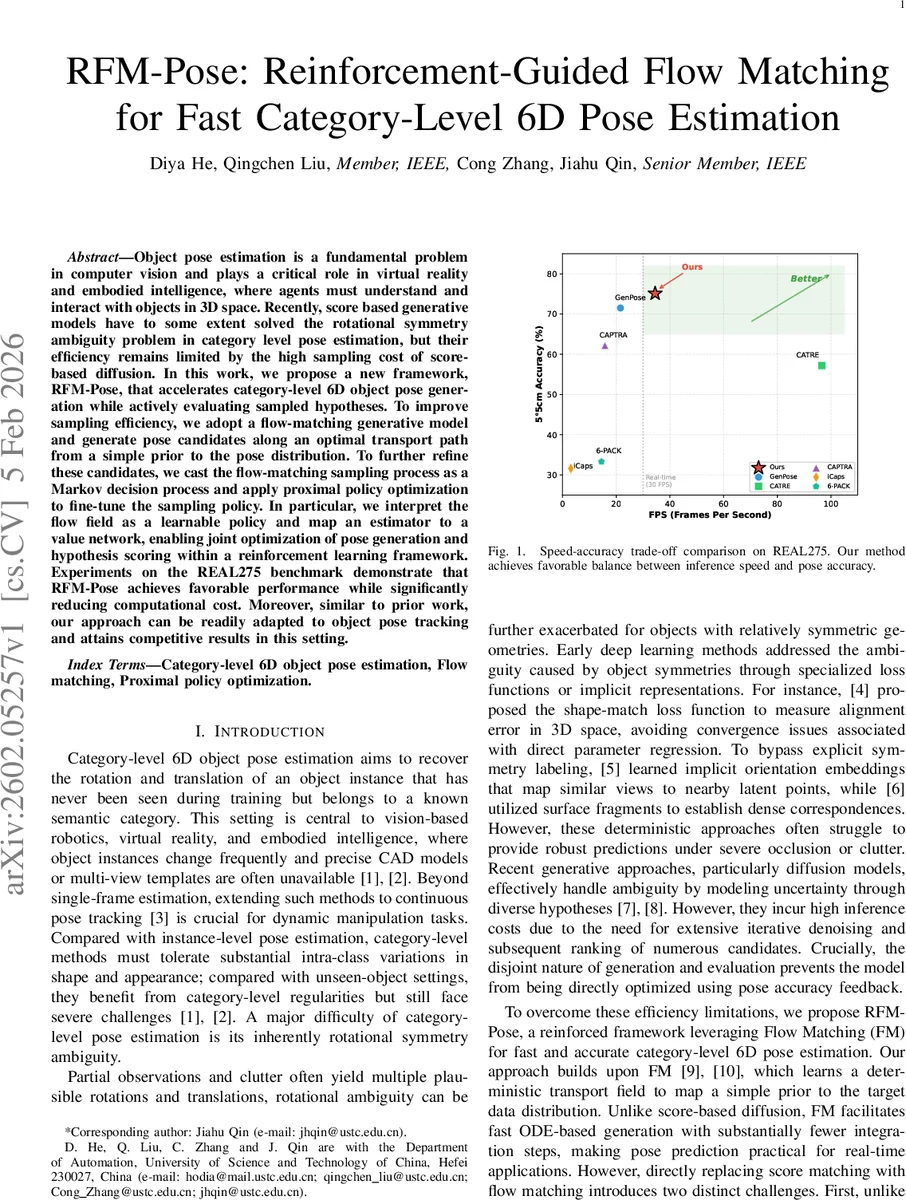
Object pose estimation is a fundamental problem in computer vision and plays a critical role in virtual reality and embodied intelligence, where agents must understand and interact with objects in 3D space. Recently, score based generative models have to some extent solved the rotational symmetry ambiguity problem in category level pose estimation, but their efficiency remains limited by the high sampling cost of score-based diffusion. In this work, we propose a new framework, RFM-Pose, that accelerates category-level 6D object pose generation while actively evaluating sampled hypotheses. To improve sampling efficiency, we adopt a flow-matching generative model and generate pose candidates along an optimal transport path from a simple prior to the pose distribution. To further refine these candidates, we cast the flow-matching sampling process as a Markov decision process and apply proximal policy optimization to fine-tune the sampling policy. In particular, we interpret the flow field as a learnable policy and map an estimator to a value network, enabling joint optimization of pose generation and hypothesis scoring within a reinforcement learning framework. Experiments on the REAL275 benchmark demonstrate that RFM-Pose achieves favorable performance while significantly reducing computational cost. Moreover, similar to prior work, our approach can be readily adapted to object pose tracking and attains competitive results in this setting.
💡 Research Summary
RFM‑Pose addresses the long‑standing trade‑off between accuracy and efficiency in category‑level 6D object pose estimation. Recent diffusion‑based generative approaches (e.g., GenPose, 6D‑Diff) model the multimodal pose distribution with score‑matching, thereby handling rotational symmetry and occlusion, but they require hundreds of denoising steps at inference time, making real‑time deployment impractical. The authors propose to replace the diffusion backbone with a flow‑matching (FM) model, which learns a deterministic optimal‑transport ODE that transports a simple Gaussian prior to the target pose distribution conditioned on a partial point cloud. Because FM generates samples by integrating a learned velocity field, it can produce high‑quality pose hypotheses with only a few Euler steps, reducing the computational burden by roughly an order of magnitude.
However, FM alone lacks a principled scoring mechanism for hypothesis selection and tends to produce an overly dispersed rotation distribution for symmetric objects, since it is trained to match velocities rather than directly minimize pose error. To overcome these limitations, the authors reinterpret the FM sampling trajectory as a Markov decision process (MDP). The state at step h consists of the observation O, the history of previously generated flow vectors u_h, and the normalized step index h/H. The pretrained flow network Γ_θ serves as an initial policy π_θ′, and each predicted flow vector is treated as an action that moves the pose state forward along the ODE.
A reinforcement‑learning (RL) stage fine‑tunes this policy using proximal policy optimization (PPO). The reward at each step combines rotation and translation errors: r_rot = exp(‑ΔR/τ_R) + bonus, r_trans = exp(‑ΔT/τ_T) + bonus, where ΔR and ΔT are the angular and Euclidean deviations from ground truth. Because rotation lives on SO(3) and translation on ℝ³ with different scales, a single scalar reward would be insufficient. Therefore, the authors introduce a multi‑critic value network V_ϕ with separate heads for rotation and translation, providing dense, modality‑specific value estimates that guide the PPO updates and reduce variance.
During training, the FM backbone is first learned with the standard conditional flow‑matching loss, then the policy and value networks are jointly optimized while keeping the integration horizon H fixed. This preserves the fast inference speed of FM while reshaping the learned velocity field to produce tighter SO(3) distributions that concentrate around the true pose modes.
At test time, the refined policy generates K pose candidates by integrating the ODE a small number of steps. The value network scores each candidate, and the top‑ranked hypotheses are aggregated: rotation is fused using the QUEST algorithm, and translation is combined via weighted averaging. This eliminates the need for costly likelihood estimation or external energy models.
Experiments on the REAL275 benchmark and the larger Omni6DPose dataset demonstrate that RFM‑Pose achieves comparable or slightly higher 5°/5 cm accuracy than state‑of‑the‑art diffusion methods while using roughly 6–8 integration steps instead of 100+ diffusion steps. The method runs at >30 FPS on a single GPU, meeting real‑time requirements. Moreover, the same framework can be applied to pose tracking across video frames, yielding competitive tracking performance without additional modifications.
In summary, the paper makes three key contributions: (1) introducing a flow‑matching generative backbone for fast 6D pose sampling; (2) formulating the sampling process as an MDP and applying PPO with a multi‑critic value estimator to refine the policy toward pose‑accuracy; and (3) demonstrating that the learned value network can serve as an effective, learned scoring function, enabling efficient hypothesis selection and aggregation. The work opens avenues for extending flow‑matching plus RL to other 3D perception tasks, such as object reconstruction, scene flow estimation, or robot manipulation planning, where fast, accurate sampling of transformations is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment