TADS: Task-Aware Data Selection for Multi-Task Multimodal Pre-Training
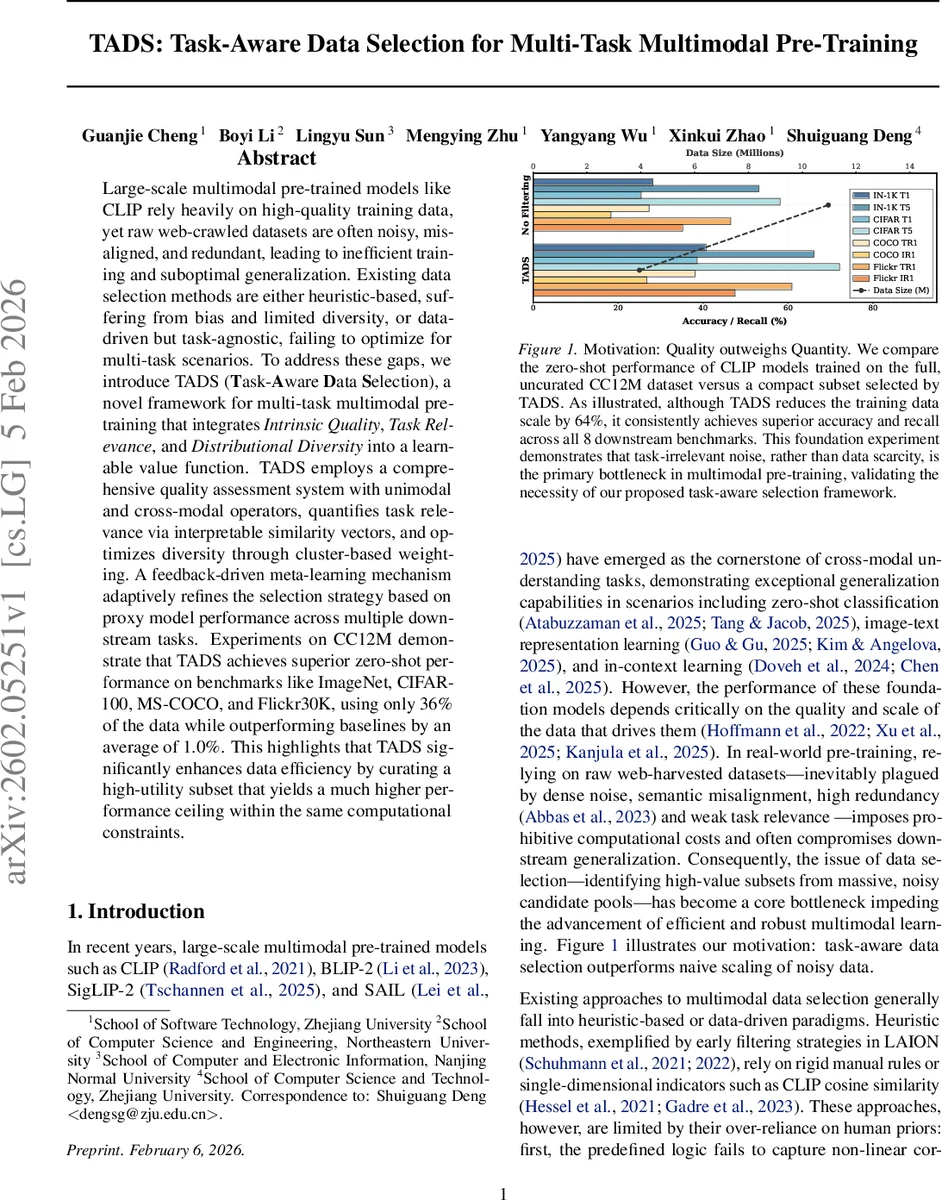
Large-scale multimodal pre-trained models like CLIP rely heavily on high-quality training data, yet raw web-crawled datasets are often noisy, misaligned, and redundant, leading to inefficient training and suboptimal generalization. Existing data selection methods are either heuristic-based, suffering from bias and limited diversity, or data-driven but task-agnostic, failing to optimize for multi-task scenarios. To address these gaps, we introduce TADS (Task-Aware Data Selection), a novel framework for multi-task multimodal pre-training that integrates Intrinsic Quality, Task Relevance, and Distributional Diversity into a learnable value function. TADS employs a comprehensive quality assessment system with unimodal and cross-modal operators, quantifies task relevance via interpretable similarity vectors, and optimizes diversity through cluster-based weighting. A feedback-driven meta-learning mechanism adaptively refines the selection strategy based on proxy model performance across multiple downstream tasks. Experiments on CC12M demonstrate that TADS achieves superior zero-shot performance on benchmarks like ImageNet, CIFAR-100, MS-COCO, and Flickr30K, using only 36% of the data while outperforming baselines by an average of 1.0%. This highlights that TADS significantly enhances data efficiency by curating a high-utility subset that yields a much higher performance ceiling within the same computational constraints.
💡 Research Summary
The paper tackles a fundamental bottleneck in large‑scale multimodal pre‑training: the overwhelming amount of noisy, misaligned, and redundant web‑crawled image‑text pairs that dilute model performance and inflate computational cost. While prior data‑selection approaches either rely on handcrafted heuristics (e.g., resolution thresholds, CLIP cosine similarity) or learn a single, task‑agnostic quality score, they fail to address the multi‑task nature of modern vision‑language models such as CLIP, BLIP‑2, or SAIL. To bridge this gap, the authors propose Task‑Aware Data Selection (TADS), a three‑stage framework that jointly optimizes Intrinsic Quality, Task Relevance, and Distributional Diversity through a learnable Data Value Network (DVN) and a bi‑level meta‑learning loop.
Stage 1 – Multi‑Layer Deduplication
Raw data U = {(I_i, T_i)} undergoes three successive filters: (a) metadata‑aware deduplication removes exact duplicates using file hashes and URLs, retaining the instance with the highest initial quality score S_init (a weighted sum of image resolution and text length). (b) Semantic deduplication clusters the dataset in a joint CLIP embedding space via Mini‑Batch K‑Means, then keeps the top γ · |C_j| samples per cluster based on S_init. (c) Quality‑guided deduplication eliminates fine‑grained redundancy by detecting structural duplication (edit‑distance) and semantic duplication (high text‑embedding cosine similarity). Within each redundant group, the sample with the highest CLIP alignment score (image‑text cosine) is kept. This cascade yields a compact, less redundant set U′.
Stage 2 – Multi‑Dimensional Value Characterization
The authors argue that data utility can be expressed as a vector of three orthogonal dimensions:
- Intrinsic Quality – A high‑dimensional feature vector f(x) =
Comments & Academic Discussion
Loading comments...
Leave a Comment