Cross-Domain Few-Shot Segmentation via Multi-view Progressive Adaptation
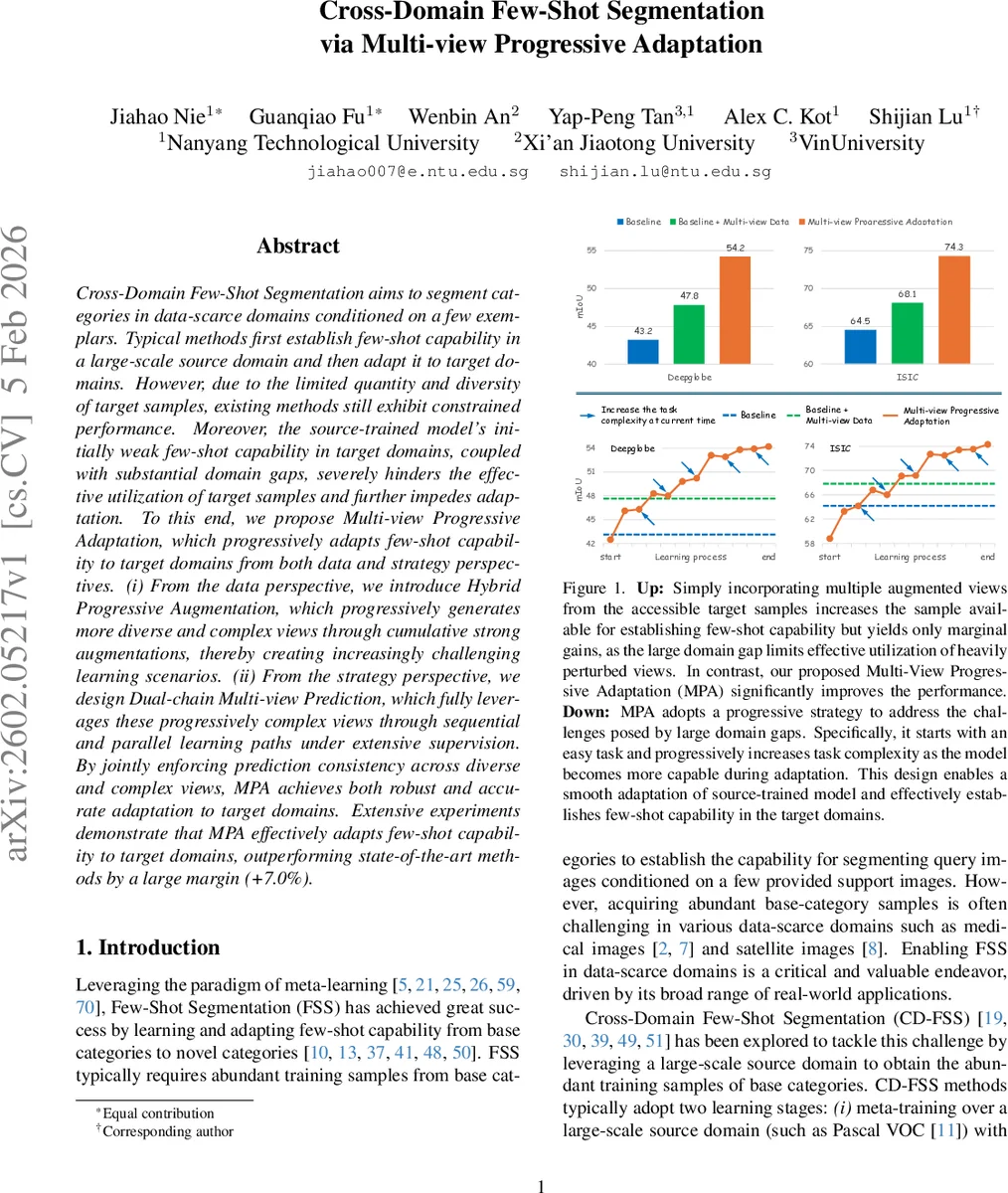
Cross-Domain Few-Shot Segmentation aims to segment categories in data-scarce domains conditioned on a few exemplars. Typical methods first establish few-shot capability in a large-scale source domain and then adapt it to target domains. However, due to the limited quantity and diversity of target samples, existing methods still exhibit constrained performance. Moreover, the source-trained model’s initially weak few-shot capability in target domains, coupled with substantial domain gaps, severely hinders the effective utilization of target samples and further impedes adaptation. To this end, we propose Multi-view Progressive Adaptation, which progressively adapts few-shot capability to target domains from both data and strategy perspectives. (i) From the data perspective, we introduce Hybrid Progressive Augmentation, which progressively generates more diverse and complex views through cumulative strong augmentations, thereby creating increasingly challenging learning scenarios. (ii) From the strategy perspective, we design Dual-chain Multi-view Prediction, which fully leverages these progressively complex views through sequential and parallel learning paths under extensive supervision. By jointly enforcing prediction consistency across diverse and complex views, MPA achieves both robust and accurate adaptation to target domains. Extensive experiments demonstrate that MPA effectively adapts few-shot capability to target domains, outperforming state-of-the-art methods by a large margin (+7.0%).
💡 Research Summary
Cross‑Domain Few‑Shot Segmentation (CD‑FSS) aims to transfer a model trained on a large‑scale source domain to a data‑scarce target domain, where only a few annotated support images are available. Existing pipelines follow a two‑stage paradigm: meta‑training on the source domain to acquire few‑shot capability, then adapting this capability to each target domain. This paradigm suffers from two fundamental bottlenecks: (1) the target domain provides extremely limited and low‑diversity samples for adaptation, and (2) the domain gap between source and target is often large, causing the source‑trained model to exhibit weak few‑shot performance on the target data. Consequently, previous methods achieve only modest gains when simply augmenting the few available target samples.
The paper proposes Multi‑view Progressive Adaptation (MPA), a framework that tackles both bottlenecks by progressively increasing task difficulty from both data and strategy perspectives.
Hybrid Progressive Augmentation (HPA) – From the data side, HPA generates a series of augmented query views from the single support image. Augmentation starts with a simple horizontal flip (easy view) and progressively adds stronger transformations such as hue shift, brightness change, and grid shuffle. The augmentations are cumulative, so later views become increasingly complex. Moreover, the number of query views N is gradually increased during adaptation (starting from N=1). This two‑fold progression raises the diversity of support‑query correspondences and forces the model to cope with harder visual variations as it becomes more capable.
Dual‑chain Multi‑view Prediction (DMP) – From the strategy side, DMP exploits the generated views through two complementary prediction chains.
Sequential chain: The support prototype is computed from the support image and mask. The first query view uses this prototype to predict its mask; the second query view then uses the prediction of the first view as additional guidance, and so on. Errors therefore accumulate along the chain, providing a natural curriculum that becomes harder as adaptation proceeds.
Parallel chain: Each query view independently performs a “support‑to‑query” prediction using the same support prototype. This yields multiple predictions for the same underlying class under different perturbations, encouraging the network to learn robust, view‑invariant representations.
Both chains are supervised with a combination of binary cross‑entropy, prototype‑based cosine similarity losses, and a consistency loss that forces predictions from the two chains to agree across all views. The overall loss is a weighted sum of these components, encouraging accurate predictions on each view while aligning the two learning paths.
Extensive experiments on heterogeneous target domains (e.g., DeepGlobe satellite imagery and ISIC medical images) demonstrate that MPA consistently outperforms prior state‑of‑the‑art CD‑FSS methods. The full MPA pipeline yields an average increase of about 7 % mIoU over the strongest baselines, with particularly large gains in the challenging 1‑shot setting. Ablation studies show that both HPA and DMP contribute independently to performance improvements, confirming the effectiveness of progressive difficulty and dual‑chain supervision.
Key contributions are: (1) identifying the dual constraints of limited target data and large domain gaps in CD‑FSS; (2) introducing a progressive augmentation scheme that adaptively raises view complexity and quantity; (3) designing a dual‑chain prediction mechanism that leverages both sequential error propagation and parallel diversity; and (4) delivering a unified framework that substantially narrows the performance gap between source‑trained models and target‑domain few‑shot segmentation.
Future directions include automated scheduling of augmentation difficulty, lightweight variants of the dual‑chain architecture, integration with large pre‑trained foundation models such as SAM, and extending the progressive adaptation paradigm to semi‑supervised or unsupervised domain adaptation scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment