Horizon-LM: A RAM-Centric Architecture for LLM Training
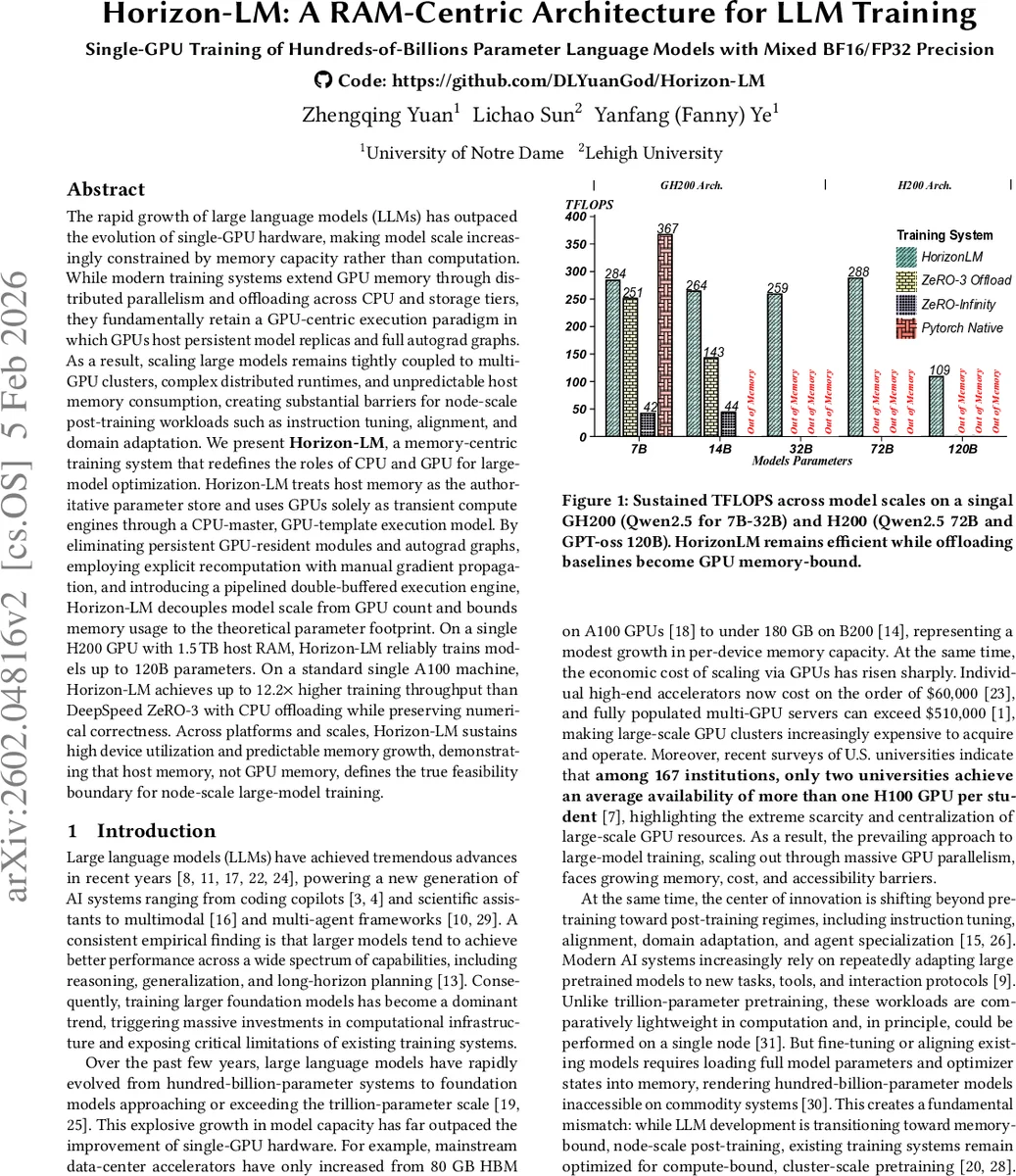
The rapid growth of large language models (LLMs) has outpaced the evolution of single-GPU hardware, making model scale increasingly constrained by memory capacity rather than computation. While modern training systems extend GPU memory through distributed parallelism and offloading across CPU and storage tiers, they fundamentally retain a GPU-centric execution paradigm in which GPUs host persistent model replicas and full autograd graphs. As a result, scaling large models remains tightly coupled to multi-GPU clusters, complex distributed runtimes, and unpredictable host memory consumption, creating substantial barriers for node-scale post-training workloads such as instruction tuning, alignment, and domain adaptation. We present Horizon-LM, a memory-centric training system that redefines the roles of CPU and GPU for large-model optimization. Horizon-LM treats host memory as the authoritative parameter store and uses GPUs solely as transient compute engines through a CPU-master, GPU-template execution model. By eliminating persistent GPU-resident modules and autograd graphs, employing explicit recomputation with manual gradient propagation, and introducing a pipelined double-buffered execution engine, Horizon-LM decouples model scale from GPU count and bounds memory usage to the theoretical parameter footprint. On a single H200 GPU with 1.5,TB host RAM, Horizon-LM reliably trains models up to 120B parameters. On a standard single A100 machine, Horizon-LM achieves up to 12.2$\times$ higher training throughput than DeepSpeed ZeRO-3 with CPU offloading while preserving numerical correctness. Across platforms and scales, Horizon-LM sustains high device utilization and predictable memory growth, demonstrating that host memory, not GPU memory, defines the true feasibility boundary for node-scale large-model training.
💡 Research Summary
The paper “Horizon‑LM: A RAM‑Centric Architecture for LLM Training” addresses the growing mismatch between the rapid scaling of large language models (LLMs) and the relatively stagnant memory capacity of single‑GPU hardware. Existing systems such as DeepSpeed ZeRO‑3, ZeRO‑Infinity, and FSDP extend effective GPU memory by offloading parameters, optimizer states, and activations to CPU RAM or NVMe, but they retain a GPU‑centric execution model: GPUs still host persistent model replicas and full autograd graphs, and every training step requires gathering the parameters onto the device. This design imposes three fundamental limitations: (1) training inevitably depends on multi‑GPU clusters and complex distributed runtimes; (2) CPU memory is repurposed as a runtime heap, making overall memory consumption unpredictable and not strictly proportional to model size; (3) even with abundant host memory, the tight coupling of memory management and computation prevents a single GPU from handling hundred‑billion‑parameter models.
Horizon‑LM proposes a radical shift: treat host memory as the authoritative parameter store and use GPUs solely as transient compute engines. The system adopts a “CPU‑master, GPU‑template” execution model. All model weights, gradients, and Adam optimizer moments reside in host RAM—weights and gradients in BF16 (2 bytes each) and moments in FP32 (8 bytes). GPUs keep only lightweight, reusable layer templates. During training, a layer’s parameters are streamed from host to GPU just before the forward pass, the computation is performed, and the buffers are immediately released. No persistent autograd graph is built; instead, Horizon‑LM performs explicit block‑wise recomputation and manual gradient propagation, which bounds GPU memory usage to a per‑layer footprint rather than the total model size.
The authors derive two key memory invariants. Host memory must scale linearly with model size: M_host ≥ P · (2 + 2 + 8) bytes = 12 P bytes, where P is the total number of parameters. Consequently, a 100 B‑parameter model needs at least 1.2 TB of RAM, and a 300 B model exceeds 3.6 TB. GPU memory, on the other hand, is limited by the maximum per‑layer parameter size (P_max) plus a constant factor for double‑buffering and activation checkpoints: M_GPU ≤ c_p·P_max + c_a·K·A_max + W_GPU. This decouples feasible model depth from GPU capacity; only the widest layer must fit within the bounded GPU budget.
Performance hinges on the host‑GPU interconnect. Each training iteration streams parameters (≈ P bytes) to the device and gradients (≈ P bytes) back, for a total of ~2 P bytes. Horizon‑LM decomposes this transfer at the layer granularity, overlapping the transfer of layer i’s parameters with the computation of layer i‑1 (or the backward of layer i). The feasibility condition becomes P_i / B_pcie ≤ T_comp,i‑1, where B_pcie is the effective bidirectional bandwidth (PCIe 5.0 or NVLink‑C2C). By pipelining a double‑buffered execution engine, the system hides data movement behind computation, ensuring that the bandwidth does not become a bottleneck.
Empirical evaluation demonstrates the approach’s practicality. On an NVIDIA H200 GPU equipped with 1.5 TB of host RAM, Horizon‑LM successfully trains a 120 B‑parameter model, a regime where prior offloading frameworks fail due to memory exhaustion. On a conventional A100 single‑node setup, Horizon‑LM achieves up to 12.2× higher throughput than DeepSpeed ZeRO‑3 with CPU offloading, while maintaining numerical correctness. Across a range of model sizes (7 B–120 B), the system sustains high GPU utilization (> 90 %) and exhibits predictable, linear host memory growth.
In conclusion, Horizon‑LM redefines large‑model training from a GPU‑centric to a RAM‑centric paradigm. By treating host memory as a clean, model‑proportional parameter store and by streaming per‑layer data through a tightly pipelined GPU engine, it removes the necessity for multi‑GPU clusters in many post‑training workloads such as instruction tuning, alignment, and domain adaptation. This dramatically lowers hardware costs, simplifies software stacks, and opens the door for researchers and practitioners to fine‑tune or adapt hundred‑billion‑parameter LLMs on a single node.
Comments & Academic Discussion
Loading comments...
Leave a Comment