Vibe AIGC: A New Paradigm for Content Generation via Agentic Orchestration
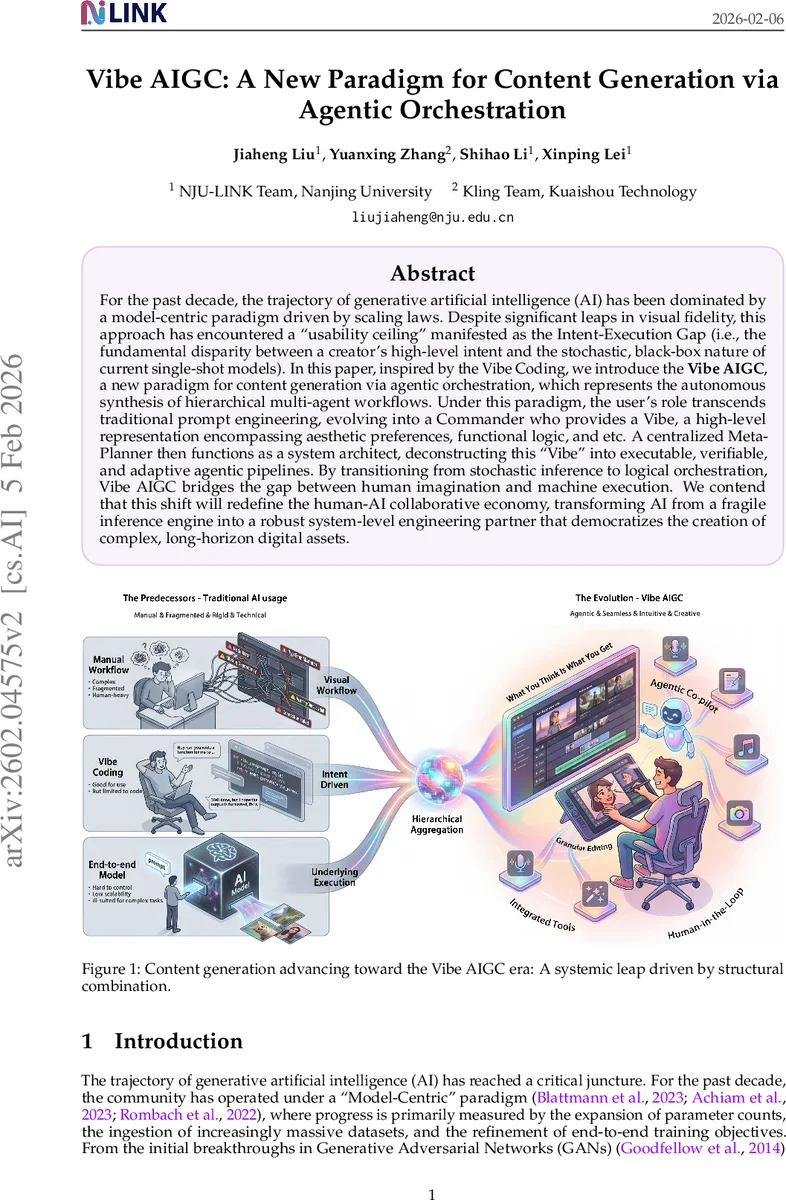
For the past decade, the trajectory of generative artificial intelligence (AI) has been dominated by a model-centric paradigm driven by scaling laws. Despite significant leaps in visual fidelity, this approach has encountered a usability ceiling'' manifested as the Intent-Execution Gap (i.e., the fundamental disparity between a creator's high-level intent and the stochastic, black-box nature of current single-shot models). In this paper, inspired by the Vibe Coding, we introduce the \textbf{Vibe AIGC}, a new paradigm for content generation via agentic orchestration, which represents the autonomous synthesis of hierarchical multi-agent workflows. Under this paradigm, the user's role transcends traditional prompt engineering, evolving into a Commander who provides a Vibe, a high-level representation encompassing aesthetic preferences, functional logic, and etc. A centralized Meta-Planner then functions as a system architect, deconstructing this Vibe’’ into executable, verifiable, and adaptive agentic pipelines. By transitioning from stochastic inference to logical orchestration, Vibe AIGC bridges the gap between human imagination and machine execution. We contend that this shift will redefine the human-AI collaborative economy, transforming AI from a fragile inference engine into a robust system-level engineering partner that democratizes the creation of complex, long-horizon digital assets.
💡 Research Summary
The paper “Vibe AIGC: A New Paradigm for Content Generation via Agentic Orchestration” argues that the dominant model‑centric approach to generative AI—driven by ever larger parameter counts and massive datasets—has reached a “usability ceiling.” While scaling has produced impressive visual fidelity, it has not solved the fundamental Intent‑Execution Gap: the mismatch between a creator’s high‑level, multidimensional vision and the stochastic, black‑box behavior of single‑shot generative models. As a result, users are forced into a labor‑intensive “prompt engineering” loop, repeatedly tweaking keywords and re‑rolling generations to obtain acceptable results. This workflow is especially problematic for long‑horizon creative tasks that require temporal consistency, character fidelity, and deep semantic alignment.
Inspired by the emerging concept of “Vibe Coding,” the authors propose a shift from model‑centric generation to a system‑centric paradigm called Vibe AIGC. In this framework, the user assumes the role of a “Commander” who supplies a Vibe—a high‑level representation that encodes aesthetic preferences, functional goals, and implicit constraints. A centralized Meta‑Planner then parses the Vibe, decomposes it into a hierarchy of specialized agents, and orchestrates an executable, verifiable workflow. Each agent may be a fine‑tuned diffusion model, a text‑to‑video generator, a reference‑based transformer, or an editing module, but the key is that they are coordinated logically rather than invoked independently.
The Meta‑Planner maintains a feedback loop: if intermediate outputs deviate from the intended Vibe, the Commander can issue high‑level corrective cues (e.g., “make the scene darker” or “increase tension”). The planner then reconfigures the underlying pipeline—adjusting prompts, swapping agents, or altering execution order—rather than simply re‑sampling a single model. This recursive orchestration turns the generation process from stochastic guessing into deterministic, falsifiable reasoning.
The paper provides a detailed critique of current video‑generation technologies. State‑of‑the‑art latent diffusion models with spacetime transformers compress video into patches and denoise conditioned on text, but they suffer from high computational cost, limited training data, and difficulty maintaining identity consistency across frames. Reference‑based generation and editing methods (e.g., DreamBooth‑style subject personalization, text‑guided in‑painting) are hampered by scarce paired data and “content leakage” artifacts. Unified multimodal models that treat video as a token sequence alongside text and audio have been explored, yet they still lag behind specialized DiT models in fidelity and semantic alignment.
By contrast, Vibe AIGC’s agentic orchestration can dynamically combine these heterogeneous capabilities, allowing complex, multi‑step creative pipelines (storyboarding, script writing, music analysis, character sheet generation, final editing) to be assembled automatically. The authors argue that the primary research frontier now lies in perfecting the orchestration layer: designing robust Meta‑Planners, defining standard interfaces among agents, and establishing human‑AI interaction protocols that support high‑level feedback and verification.
Finally, the paper outlines a roadmap for building the Vibe AIGC ecosystem: (1) develop open‑source Meta‑Planner frameworks, (2) create reusable, modular agents with well‑specified APIs, (3) curate benchmark suites that evaluate end‑to‑end workflow quality rather than isolated model metrics, and (4) foster community standards for safety, reproducibility, and economic incentives. If realized, Vibe AIGC would transform generative AI from a fragile inference engine into a robust system‑level engineering partner, democratizing the creation of long‑horizon digital assets such as cinematic music videos, interactive narratives, and complex multimedia productions.
Comments & Academic Discussion
Loading comments...
Leave a Comment