Training Data Efficiency in Multimodal Process Reward Models
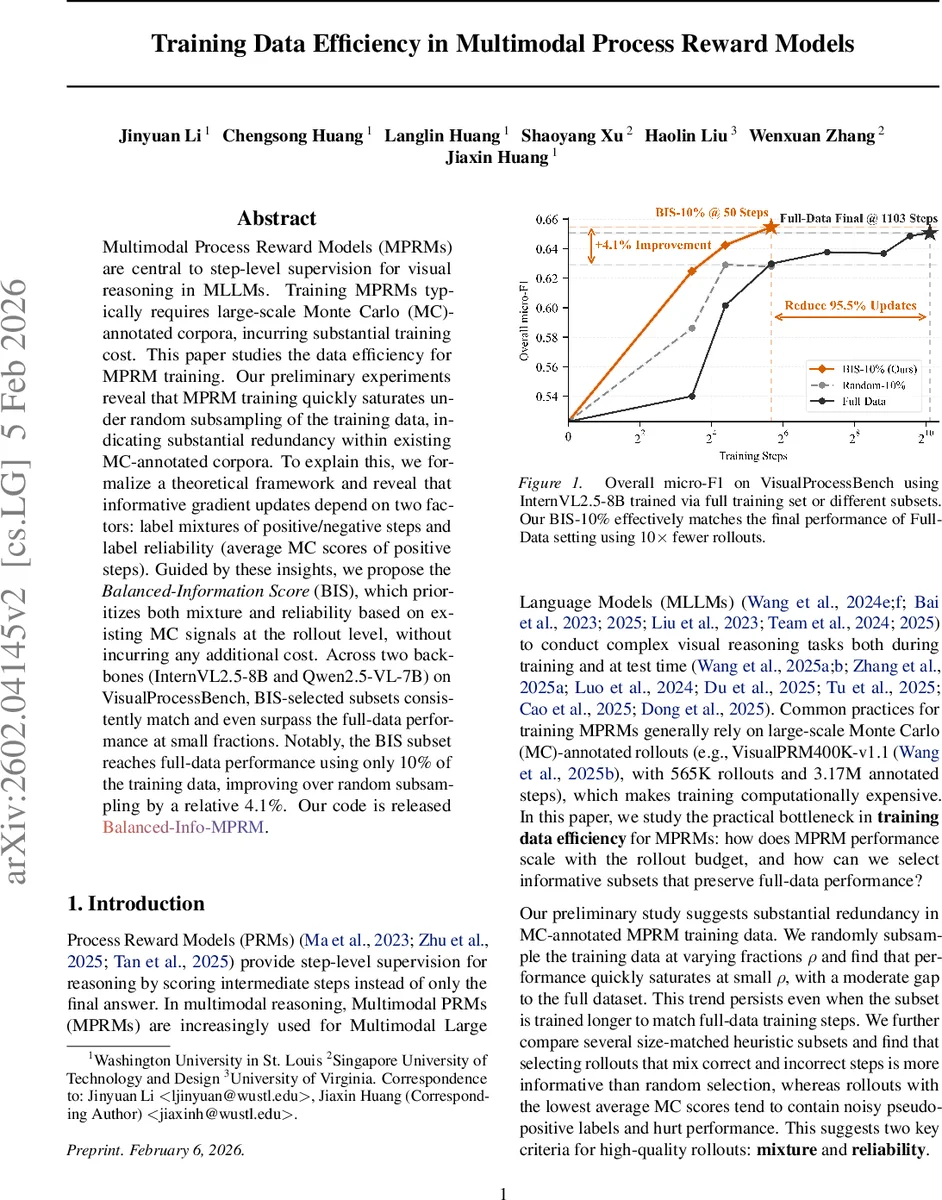
Multimodal Process Reward Models (MPRMs) are central to step-level supervision for visual reasoning in MLLMs. Training MPRMs typically requires large-scale Monte Carlo (MC)-annotated corpora, incurring substantial training cost. This paper studies the data efficiency for MPRM training. Our preliminary experiments reveal that MPRM training quickly saturates under random subsampling of the training data, indicating substantial redundancy within existing MC-annotated corpora. To explain this, we formalize a theoretical framework and reveal that informative gradient updates depend on two factors: label mixtures of positive/negative steps and label reliability (average MC scores of positive steps). Guided by these insights, we propose the Balanced-Information Score (BIS), which prioritizes both mixture and reliability based on existing MC signals at the rollout level, without incurring any additional cost. Across two backbones (InternVL2.5-8B and Qwen2.5-VL-7B) on VisualProcessBench, BIS-selected subsets consistently match and even surpass the full-data performance at small fractions. Notably, the BIS subset reaches full-data performance using only 10% of the training data, improving over random subsampling by a relative 4.1%.
💡 Research Summary
The paper investigates the data efficiency of Multimodal Process Reward Models (MPRMs), which provide step‑level supervision for visual reasoning in multimodal large language models (MLLMs). Existing MPRM training pipelines rely on massive Monte‑Carlo (MC) annotated rollouts (e.g., VisualPRM400K‑v1.1 with 565 K rollouts and 3.17 M annotated steps), incurring high computational cost. The authors first conduct a systematic empirical study by randomly subsampling the training corpus at various fractions (ρ). They observe that performance (micro‑F1 on VisualProcessBench) quickly saturates even when only 25 % or 10 % of the data are retained, and the gap to the full‑data model remains modest even when the number of SGD updates is matched. This suggests that the training bottleneck is not data scarcity but noisy gradients caused by label noise in MC annotations.
To understand why certain subsets are more informative, the authors construct three 25 % subsets: Random‑25 % (uniform sampling), Low‑MC‑25 % (lowest average MC scores per rollout), and Mixed‑25 % (rollouts containing both positive and negative steps). Experiments reveal that Mixed‑25 % consistently outperforms the other two, despite having a similar proportion of incorrect steps as Low‑MC‑25 %. Low‑MC rollouts contain many “pseudo‑positive” labels (steps labeled positive despite very low success rates), which degrade learning. The Mixed subset, by contrast, offers a balanced exposure to both correct and erroneous reasoning while preserving reliable positive signals.
The authors formalize these observations using a teacher‑student abstraction. The teacher represents the ideal step‑level correctness distribution q∗(ϕ)=σ(⟨w∗,ϕ⟩), while the student learns from noisy MC binary labels Y_mc. Under standard SGD convergence analysis for logistic regression, the excess risk decomposes into a data‑complexity term C_data N_eff^‑½ and an optimization term C_opt T^‑½. In the MPRM setting, C_data N_eff^‑½ is already small because of the massive number of annotated steps, whereas C_opt dominates due to gradient noise induced by MC label uncertainty. Random subsampling only inflates the data term by γ^‑½, leaving the dominant optimization term unchanged; thus performance degrades only slightly. This theoretical result explains the empirical plateau.
Further, the authors derive that the expected squared gradient norm at the teacher’s optimum is proportional to q∗(1‑q∗)‖ϕ‖², which is maximized when the teacher is most uncertain (q∗≈0.5). Hence steps with a balanced mixture of positive and negative labels carry the strongest learning signal. Conversely, MC scores quantify label reliability: low MC scores correspond to high label noise, especially for steps that are incorrectly labeled positive. Therefore, two complementary criteria—mixture (uncertainty) and reliability (average MC score of positive steps)—characterize informative rollouts.
Guided by these insights, the paper introduces the Balanced‑Information Score (BIS). For each rollout, BIS computes (1) a mixture factor reflecting the proportion of positive vs. negative steps, and (2) a reliability factor given by the average MC score over the positive steps. The two factors are multiplied to produce a single “mixed‑but‑reliable” score. BIS requires only the existing MC annotations; no extra model inference or annotation is needed.
Extensive experiments on two backbones—InternVL2.5‑8B and Qwen2.5‑VL‑7B—validate BIS. Selecting the top 10 % of rollouts by BIS yields micro‑F1 identical to (or slightly higher than) training on the full dataset, while random 10 % selection lags behind by about 4 % relative. The BIS‑10 % model reaches full‑data performance after just 50 training steps, saving roughly 95.5 % of compute. Across other fractions (5 %, 20 %) BIS consistently outperforms random and other heuristics (e.g., highest MC score). The gains hold for both backbones and across all five sources in VisualProcessBench, demonstrating robustness.
In summary, the paper makes three key contributions: (1) an empirical demonstration that MPRM training data contain substantial redundancy; (2) a theoretical framework linking gradient noise, label mixture, and MC‑based reliability to explain why random subsampling plateaus; and (3) the Balanced‑Information Score, a simple, model‑agnostic data‑selection metric that dramatically improves data efficiency without extra cost. The findings suggest that future MPRM research can achieve comparable or better performance with a fraction of the MC‑annotated rollouts, reducing annotation and training costs and accelerating development cycles for multimodal reasoning systems. Potential future work includes extending BIS to other multimodal tasks (e.g., video reasoning, robotic planning) and integrating dynamic, curriculum‑style selection strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment