DecompressionLM: Deterministic, Diagnostic, and Zero-Shot Concept Graph Extraction from Language Models
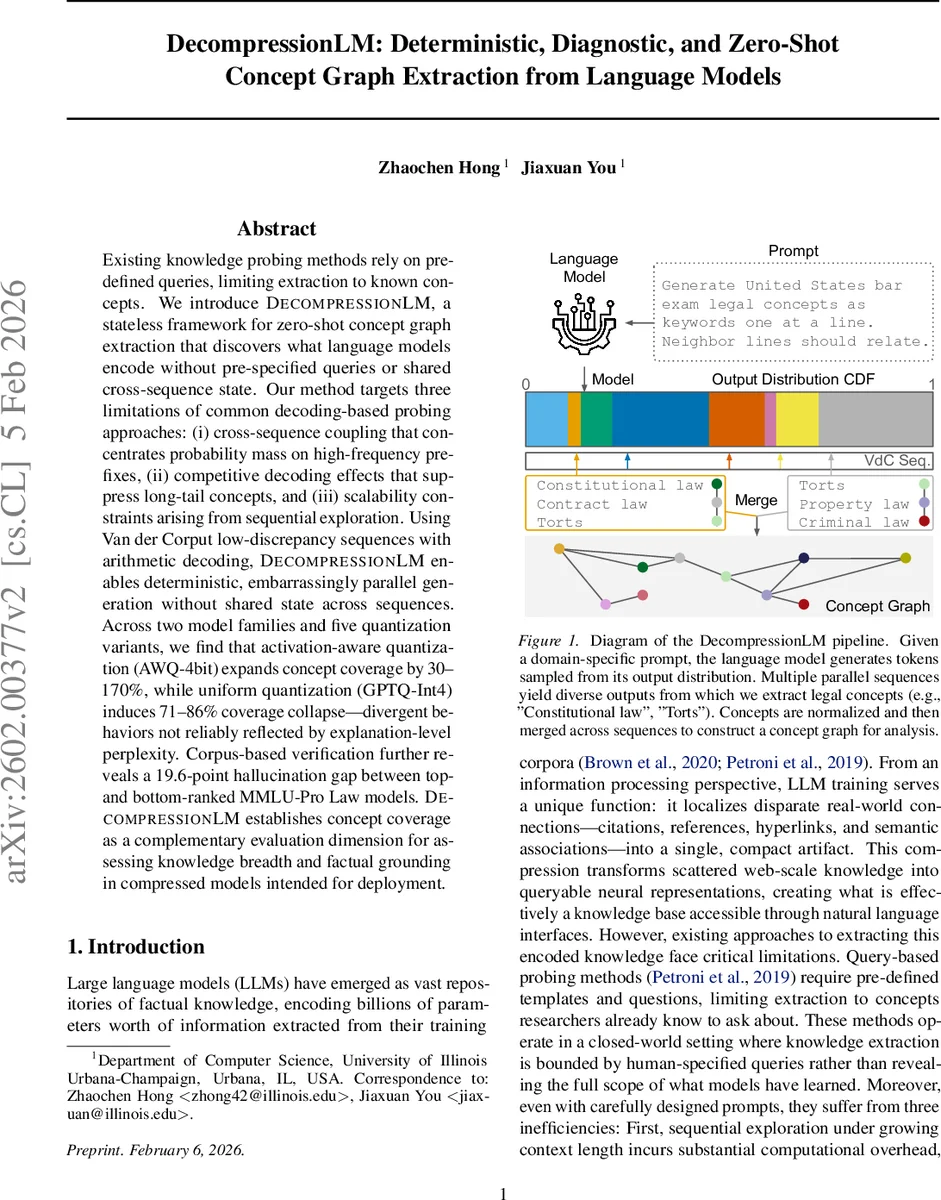
Existing knowledge probing methods rely on pre-defined queries, limiting extraction to known concepts. We introduce DecompressionLM, a stateless framework for zero-shot concept graph extraction that discovers what language models encode without pre-specified queries or shared cross-sequence state. Our method targets three limitations of common decoding-based probing approaches: (i) cross-sequence coupling that concentrates probability mass on high-frequency prefixes, (ii) competitive decoding effects that suppress long-tail concepts, and (iii) scalability constraints arising from sequential exploration. Using Van der Corput low-discrepancy sequences with arithmetic decoding, DecompressionLM enables deterministic, embarrassingly parallel generation without shared state across sequences. Across two model families and five quantization variants, we find that activation-aware quantization (AWQ-4bit) expands concept coverage by 30-170%, while uniform quantization (GPTQ-Int4) induces 71-86% coverage collapse - divergent behaviors not reliably reflected by explanation-level perplexity. Corpus-based verification further reveals a 19.6-point hallucination gap between top- and bottom-ranked MMLU-Pro Law models. DecompressionLM establishes concept coverage as a complementary evaluation dimension for assessing knowledge breadth and factual grounding in compressed models intended for deployment.
💡 Research Summary
DecompressionLM introduces a novel, stateless framework for extracting concept graphs from large language models (LLMs) without relying on pre‑defined queries or shared cross‑sequence state. Existing probing methods such as LAMA or AutoPrompt require handcrafted templates, limiting discovery to concepts that researchers already know to ask about. Moreover, decoding strategies commonly used for probing—beam search, greedy decoding, or even naive ancestral sampling—introduce systematic biases: (i) competitive hypothesis selection concentrates probability mass on high‑likelihood prefixes, (ii) cross‑sequence coupling during sequential exploration hampers scalability, and (iii) a “rich‑get‑richer” effect in autoregressive sampling suppresses long‑tail concepts even when the model’s distribution supports them.
DecompressionLM tackles these three limitations by (1) replacing sequential beam search with deterministic quasi‑random sampling using the Van der Corput (VdC) low‑discrepancy sequence, (2) coupling this sequence with arithmetic coding to turn each real‑valued code into a unique token sequence, and (3) ensuring that each generated sequence is completely independent (stateless) from all others. The VdC sequence provides an unbounded, seed‑free schedule of codes that uniformly cover the unit interval
Comments & Academic Discussion
Loading comments...
Leave a Comment