See Less, See Right: Bi-directional Perceptual Shaping For Multimodal Reasoning
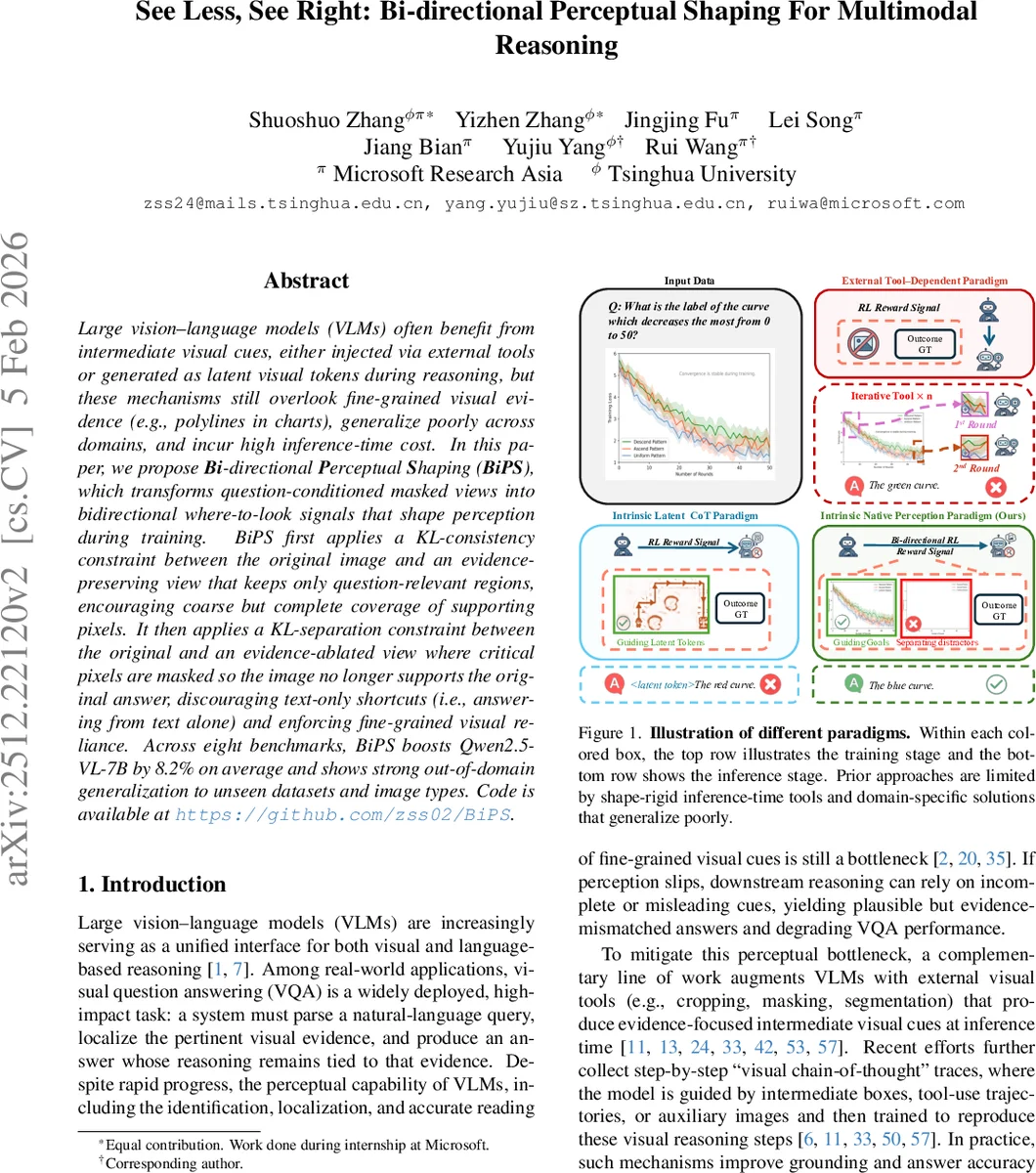
Large vision-language models (VLMs) often benefit from intermediate visual cues, either injected via external tools or generated as latent visual tokens during reasoning, but these mechanisms still overlook fine-grained visual evidence (e.g., polylines in charts), generalize poorly across domains, and incur high inference-time cost. In this paper, we propose Bi-directional Perceptual Shaping (BiPS), which transforms question-conditioned masked views into bidirectional where-to-look signals that shape perception during training. BiPS first applies a KL-consistency constraint between the original image and an evidence-preserving view that keeps only question-relevant regions, encouraging coarse but complete coverage of supporting pixels. It then applies a KL-separation constraint between the original and an evidence-ablated view where critical pixels are masked so the image no longer supports the original answer, discouraging text-only shortcuts (i.e., answering from text alone) and enforcing fine-grained visual reliance. Across eight benchmarks, BiPS boosts Qwen2.5-VL-7B by 8.2% on average and shows strong out-of-domain generalization to unseen datasets and image types.
💡 Research Summary
Large vision‑language models (VLMs) excel at answering visual questions but often rely on coarse visual cues or text‑only shortcuts, especially when fine‑grained evidence such as thin polylines in charts is required. Existing methods mitigate this by injecting external tools (cropping, masking, segmentation) or by training the model to emit latent visual tokens at inference time. These approaches suffer from three major drawbacks: (i) shape rigidity – rectangular crops or blunt masks cannot capture irregular or fragmented evidence; (ii) domain specificity – custom tools and training pipelines are tightly coupled to particular layouts, limiting cross‑domain generalization; and (iii) inference‑time overhead – generating intermediate cues adds computational cost and error propagation.
The paper introduces Bi‑directional Perceptual Shaping (BiPS), a training‑time only framework that transforms a question‑conditioned masked view of an image into two complementary views: an evidence‑preserving view (I_pres) that retains only the regions necessary to answer the question, and an evidence‑ablated view (I_abl) that removes those critical pixels while keeping the overall context. By applying a KL‑consistency loss between the original image and I_pres, the model is encouraged to keep its answer distribution unchanged when only the essential evidence remains. Conversely, a KL‑separation loss between the original image and I_abl pushes the distributions apart, discouraging the model from solving the task using text alone and forcing reliance on visual evidence. Both losses are integrated into the Group‑Relative Policy Optimization (GRPO) framework, with stop‑gradient and clipping mechanisms for stability.
A key technical contribution is a programmatic data construction pipeline that leverages executable chart code (ECD dataset). Because each chart element (marks, axes, legends) is explicitly defined in code, an auxiliary LLM arbitrator can edit the code to generate precise I_pres and I_abl images without human annotation. The pipeline also reformulates open‑ended questions into multiple‑choice format, filters out “easy” examples using the base model, and finally produces 13 K high‑quality (image, question, I_pres, I_abl) tuples.
Experiments fine‑tune Qwen2.5‑VL‑7B with BiPS on the chart‑derived data and evaluate on eight benchmarks covering chart QA (CharXiv, ChartQAPro), general VQA (MMStar), and math‑oriented visual reasoning (MathVista). BiPS yields an average accuracy gain of 7.3 % over the base model. Adding 39 K math‑focused examples with standard GRPO further raises the average improvement to 8.2 %. Notably, the model trained solely on chart data generalizes well to out‑of‑domain datasets, demonstrating strong cross‑domain robustness.
In summary, BiPS converts inference‑time visual cues into training‑time supervisory signals, using bidirectional KL constraints to shape the model’s internal perception. The approach requires no extra annotations at test time, incurs zero inference overhead, and achieves fine‑grained grounding even for irregular visual structures. While the current pipeline depends on code‑driven domains (charts), the underlying idea—pairing evidence‑preserving and evidence‑ablated views and regularizing with KL—offers a promising direction for extending visual grounding to broader image domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment