Vector Quantization using Gaussian Variational Autoencoder
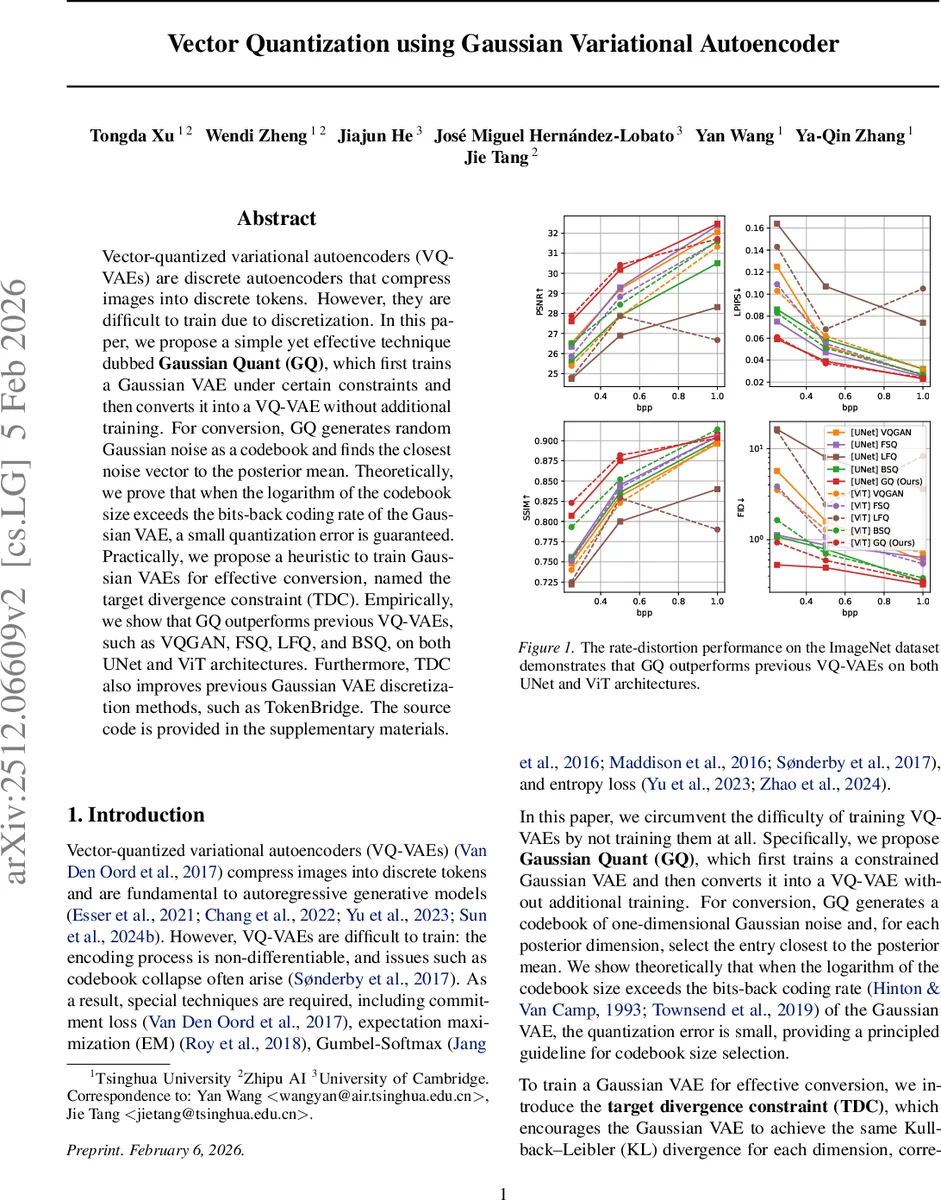
Vector-quantized variational autoencoders (VQ-VAEs) are discrete autoencoders that compress images into discrete tokens. However, they are difficult to train due to discretization. In this paper, we propose a simple yet effective technique dubbed Gaussian Quant (GQ), which first trains a Gaussian VAE under certain constraints and then converts it into a VQ-VAE without additional training. For conversion, GQ generates random Gaussian noise as a codebook and finds the closest noise vector to the posterior mean. Theoretically, we prove that when the logarithm of the codebook size exceeds the bits-back coding rate of the Gaussian VAE, a small quantization error is guaranteed. Practically, we propose a heuristic to train Gaussian VAEs for effective conversion, named the target divergence constraint (TDC). Empirically, we show that GQ outperforms previous VQ-VAEs, such as VQGAN, FSQ, LFQ, and BSQ, on both UNet and ViT architectures. Furthermore, TDC also improves previous Gaussian VAE discretization methods, such as TokenBridge. The source code is provided in the supplementary materials.
💡 Research Summary
The paper tackles the long‑standing difficulty of training vector‑quantized variational autoencoders (VQ‑VAEs), which suffer from nondifferentiable encoding, codebook collapse, and the need for elaborate regularizers. The authors propose a two‑step “train‑then‑convert” framework called Gaussian Quant (GQ). First, a standard Gaussian VAE is trained under a novel per‑dimension constraint called the Target Divergence Constraint (TDC). TDC forces the KL divergence of each latent dimension, R_i = D_KL(q(Z_i|X)‖N(0,1)), to stay close to a target value log K that corresponds to the desired codebook size. This is achieved by assigning three adaptive penalty weights (λ_min, λ_mean, λ_max) that are increased or decreased depending on whether R_i falls below, within, or above a small tolerance band around log K. The weights are updated each gradient step using a multiplicative factor β and clipped to a safe range. By aligning each R_i with log K, the posterior means μ_i and variances σ_i become calibrated to the eventual quantization budget.
In the conversion phase, a fixed codebook of K one‑dimensional Gaussian samples c₁:K ∼ N(0,1) is generated once. For each latent dimension i, the posterior mean μ_i is quantized to the nearest codeword: \hat{z}i = arg min{c_j∈c₁:K}‖μ_i – c_j‖. No further training is required; the operation is a simple nearest‑neighbor lookup. The authors prove that when the logarithm of the codebook size exceeds the bits‑back coding rate R_i by t nats, the probability of a large quantization error (| \hat{z}_i – μ_i | ≥ σ_i) decays doubly‑exponentially as exp(‑exp(t·c)). Conversely, if the codebook is too small (log K < R_i – t), the error probability grows exponentially. Hence, setting log K ≈ R_i (or rounding up) guarantees a negligible quantization error.
The method naturally extends to multi‑dimensional codebooks (m > 1). Here, m consecutive latent dimensions are grouped into a single token, and an m‑dimensional Gaussian codebook c₁:K ∼ N(0, I_m) is used. Quantization minimizes a σ‑weighted Euclidean distance while optionally adding a regularization term ω‖c_j‖ to discourage codebook collapse at low bitrates. The same TDC principle is applied to the sum of the m per‑dimension rates, ensuring the total budget matches log K.
Empirically, the authors evaluate GQ on ImageNet using two backbone families: a UNet from Stable Diffusion 3 and a Vision‑Transformer (ViT) from the BSQ line. They compare against VQ‑GAN, FSQ, LFQ, BSQ, and several pre‑trained VQ‑GAN variants, measuring PSNR, LPIPS, SSIM, and reconstruction FID (rFID) across bitrates from 0.07 to 1.00 bpp (codebook sizes 2¹⁴–2¹⁸, token counts 256–4096). GQ consistently outperforms all baselines; for example, at 0.5 bpp UNet GQ achieves PSNR 27.61 dB vs. VQ‑GAN’s 26.51 dB, and LPIPS 0.059 vs. 0.125. Similar gains are observed for ViT. The authors also demonstrate that applying TDC to the earlier TokenBridge conversion method improves its KL alignment and reconstruction metrics, confirming the general utility of the constraint.
Finally, the paper shows that GQ can be plugged into a Llama‑based transformer decoder for image generation, yielding competitive generation FID and Inception Scores without any extra fine‑tuning of the quantizer.
In summary, the contributions are threefold: (1) a simple, training‑free conversion from a constrained Gaussian VAE to a VQ‑VAE, (2) a rigorous theoretical link between codebook size and bits‑back coding rate that guides the choice of K, and (3) the Target Divergence Constraint, a lightweight per‑dimension KL regularizer that makes the Gaussian VAE “conversion‑ready.” The approach eliminates the need for complex VQ‑VAE training tricks, scales to both convolutional and transformer architectures, and delivers state‑of‑the‑art reconstruction and generation performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment